Node.js 源码剖析
前言:之前分享了 Node.js 的底层原理,主要是简单介绍了 Node.js 的一些基础原理和一些核心模块的实现,本文从 Node.js 整体方面介绍 Node.js 的底层原理。
内容主要包括五个部分。第一部分是首先介绍一下 Node.js 的组成和代码架构。然后介绍一下 Node.js 中的 Libuv, 还有 V8 和模块加载器。最后介绍一下 Node.js 的服务器架构。
1 Node.js 的组成和代码架构
下面先来看一下Node.js 的组成。Node.js 主要是由 V8、Libuv 和一些第三方库组成。
- V8 我们都比较熟悉,它是一个 JS 引擎。但是它不仅实现了 JS 解析和执行,它还是自定义拓展。比如说我们可以通过 V8 提供一些 C++ API 去定义一些全局变量,这样话我们在 JS 里面去使用这个变量了。正是因为 V8 支持这个自定义的拓展,所以才有了 Node.js 等 JS 运行时。
- Libuv 是一个跨平台的异步 IO 库。它主要的功能是它封装了各个操作系统的一些 API, 提供网络还有文件进程的这些功能。我们知道在 JS 里面是没有网络文件这些功能的,在前端时,是由浏览器提供的,而在 Node.js 里,这些功能是由 Libuv 提供的。
- 另外 Node.js 里面还引用了很多第三方库,比如 DNS 解析库,还有 HTTP 解析器等等。
接下来看一下 Node.js 代码整体的架构。
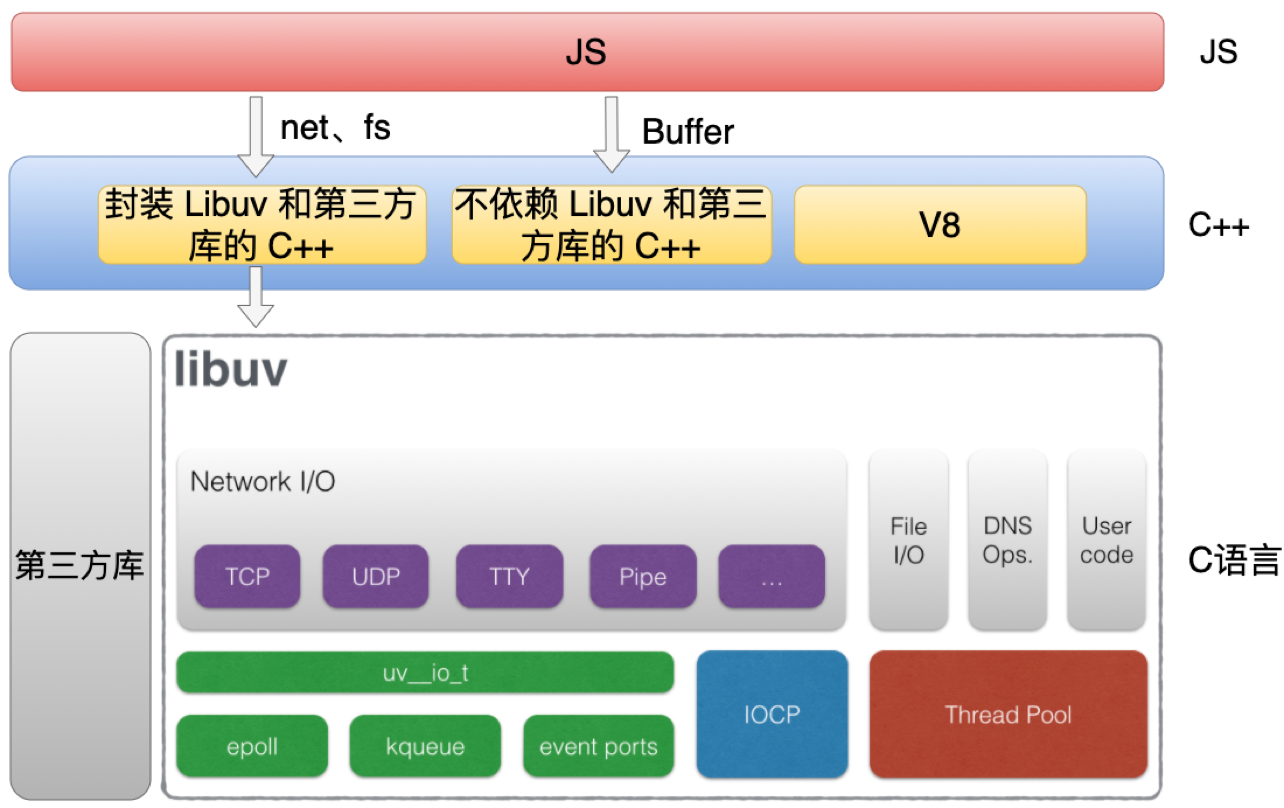 Node.js 代码主要是分为三个部分,分别是C、C++ 和 JS。
Node.js 代码主要是分为三个部分,分别是C、C++ 和 JS。
- JS 代码就是我们平时在使用的那些 JS 的模块,比方说像 http 和 fs 这些模块。
- C++ 代码主要分为三个部分,第一部分主要是封装 Libuv 和第三方库的 C++ 代码,比如net 和 fs 这些模块都会对应一个 C++ 模块,它主要是对底层的一些封装。第二部分是不依赖 Libuv 和第三方库的 C++ 代码,比方像 Buffer 模块的实现。第三部分 C++ 代码是 V8 本身的代码。
- C 语言代码主要是包括 Libuv 和第三方库的代码,它们都是纯 C 语言实现的代码。
了解了 Nodejs 的组成和代码架构之后,再来看一下 Node.js 中各个主要部分的实现。
2 Node.js 中的 Libuv
首先来看一下 Node.js 中的 Libuv,下面从三个方面介绍 Libuv。
- 介绍 Libuv 的模型和限制
- 介绍线程池解决的问题和带来的问题
- 介绍事件循环
2.1 Libuv 的模型和限制
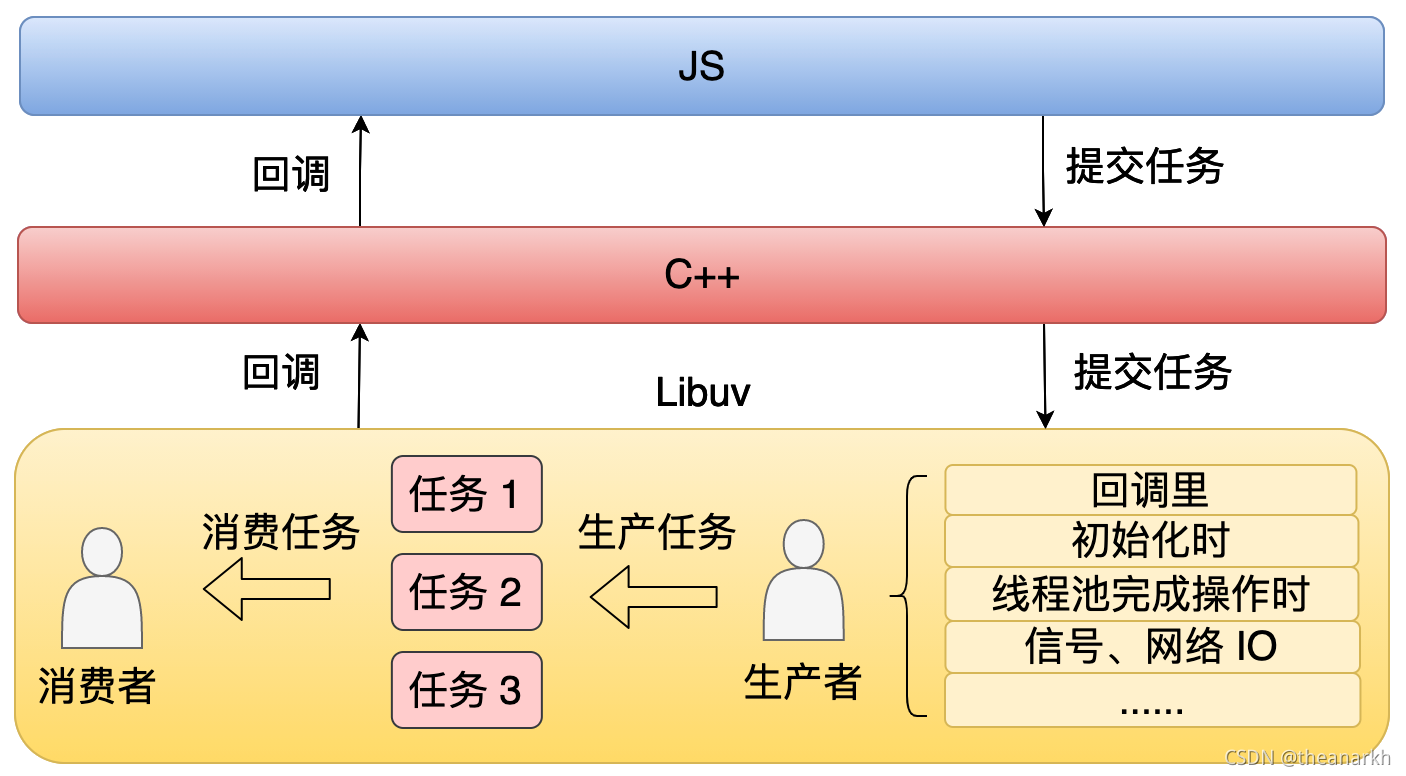
Libuv 本质上是一个生产者消费者的模型。
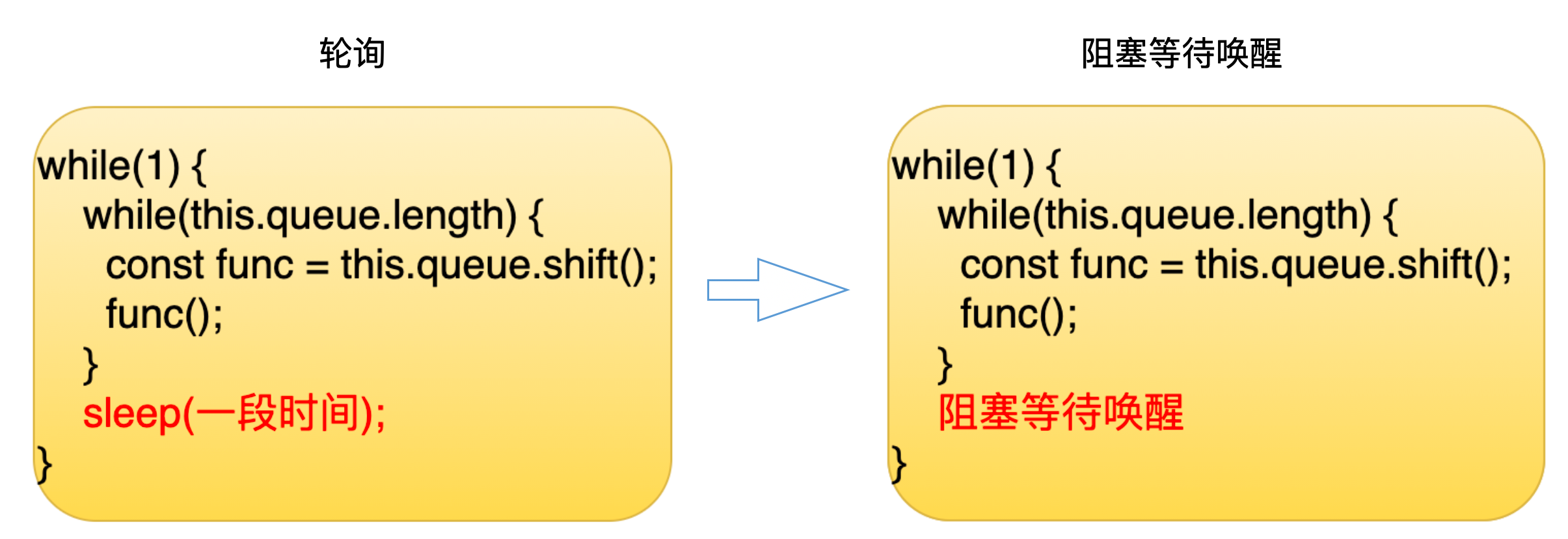
但是生产者的消费者模型存在一个问题,就是消费者和生产者之间,怎么去同步?比如说在没有任务消费的时候,这个消费者他应该在干嘛?第一种方式是消费者可以睡眠一段时间,睡醒之后,他会去判断有没有任务需要消费,如果有的话就继续消费,如果没有的话他就继续睡眠。很显然这种方式其实是比较低效的。第二种方式是消费者会把自己挂起,也就是说这个消费所在的进程会被挂起,然后等到有任务的时候,操作系统就会唤醒它,相对来说,这种方式是更高效的,Libuv 里也正是使用这种方式。
 这个逻辑主要是由事件驱动模块实现的,下面看一下事件驱动的大致的流程。
这个逻辑主要是由事件驱动模块实现的,下面看一下事件驱动的大致的流程。
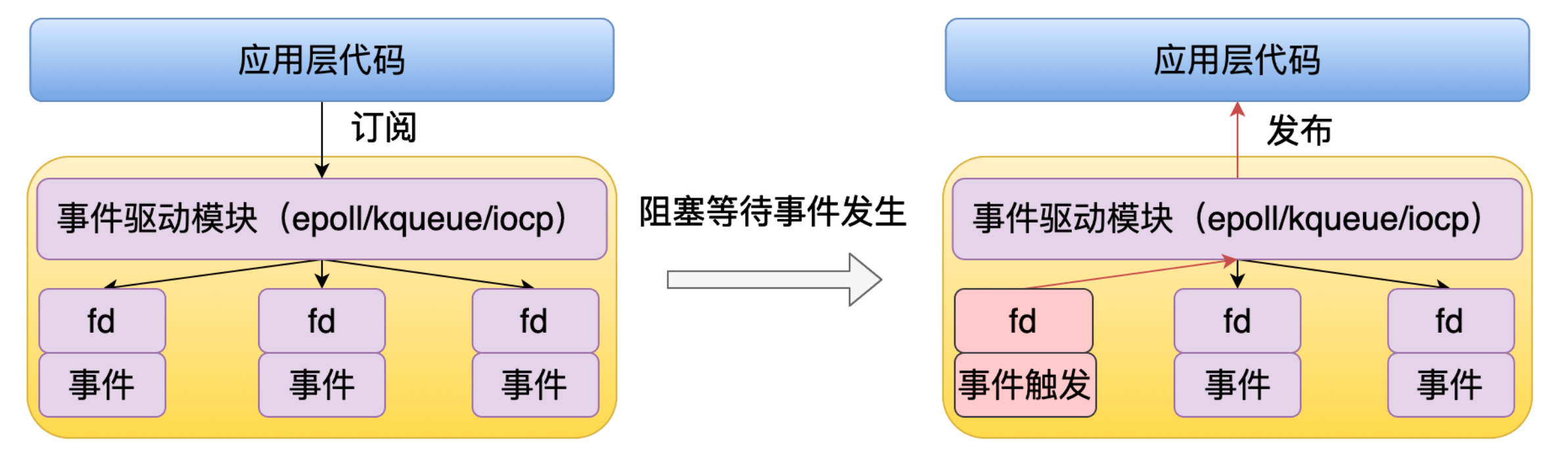 应用层代码可以通过事件驱动模块订阅 fd 的事件,如果这个事件还没有准备好的话,那么这个进程就会被挂起。然后等到这个 fd 所对应的事件触发了之后,就会通过事件驱动模块回调应用层的代码。
应用层代码可以通过事件驱动模块订阅 fd 的事件,如果这个事件还没有准备好的话,那么这个进程就会被挂起。然后等到这个 fd 所对应的事件触发了之后,就会通过事件驱动模块回调应用层的代码。
下面以 Linux 的 事件驱动模块 epoll 为例,来看一下使用流程。
- 首先通过 epoll_create 去创建一个epoll 实例。
- 然后通过 epoll_ctl 这个函数订阅、修改或者取消订阅一个 fd 的一些事件。
- 最后通过 epoll_wait 去判断当前订阅的事件有没有发生,如果有事情要发生的话,那么就直接执行上层回调,如果没有事件发生的话,这种时候可以选择不阻塞,定时阻塞或者一直阻塞,直到有事件发生。要不要阻塞或者说阻塞多久,是根据当前系统的情况。比如 Node.js 里面如果有定时器的节点的话,那么 Node.js 就会定时阻塞,这样就可以保证定时器可以按时执行。
接下来再深入一点去看一下 epoll 的大致的实现。
 当应用层代码调用事件驱动模块订阅 fd 的事件时,比如说这里是订阅一个可读事件。那么事件驱动模块它就会往这个 fd 的队列里面注册一个回调,如果当前这个事件还没有触发,这个进程它就会被阻塞。等到有一块数据写入了这个 fd 时,也就是说这个 fd 有可读事件了,操作系统就会执行事件驱动模块的回调,事件驱动模块就会相应的执行用层代码的回调。
当应用层代码调用事件驱动模块订阅 fd 的事件时,比如说这里是订阅一个可读事件。那么事件驱动模块它就会往这个 fd 的队列里面注册一个回调,如果当前这个事件还没有触发,这个进程它就会被阻塞。等到有一块数据写入了这个 fd 时,也就是说这个 fd 有可读事件了,操作系统就会执行事件驱动模块的回调,事件驱动模块就会相应的执行用层代码的回调。
但是 epoll 存在一些限制。首先第一个是不支持文件操作的,比方说文件读写这些,因为操作系统没有实现。第二个是不适合执行耗时操作,比如大量 CPU 计算、引起进程阻塞的任务,因为 epoll 通常是搭配单线程的,如果在单线程里执行耗时任务,就会导致后面的任务无法执行。
2.2 线程池解决的问题和带来的问题
针对这个问题,Libuv 提供的解决方案就是使用线程池。下面来看一下引入了线程池之后, 线程池和主线程的关系。
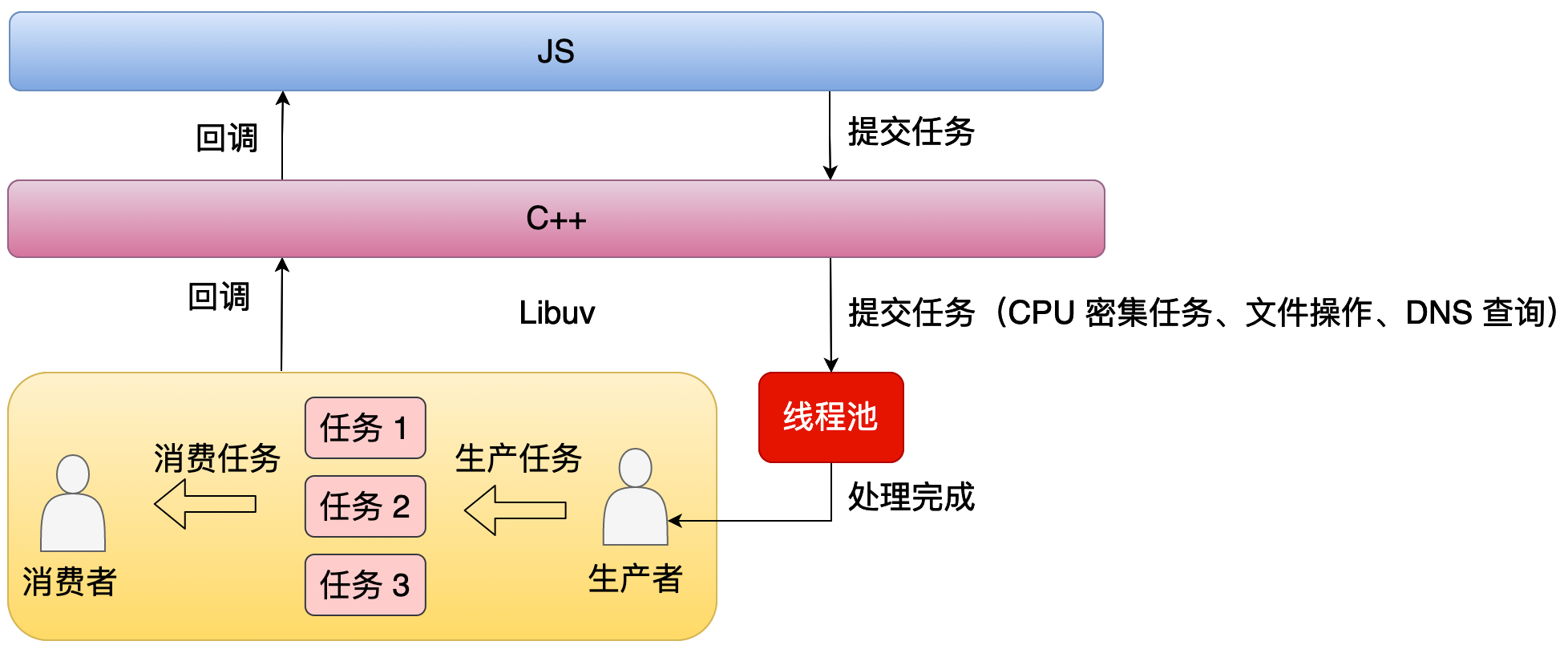 从这个图中我们可以看到,当应用层提交任务时,比方说像 CPU 计算还有文件操作,这种时候不是交给主线程去处理的,而是直接交给线程池处理的。线程池处理完之后它会通知主线程。
从这个图中我们可以看到,当应用层提交任务时,比方说像 CPU 计算还有文件操作,这种时候不是交给主线程去处理的,而是直接交给线程池处理的。线程池处理完之后它会通知主线程。
但是引入了多线程后会带来一个问题,就是怎么去保证上层代码跑在单个线程里面。因为我们知道 JS 它是单线程的,如果线程池处理完一个任务之后,直接执行上层回调,那么上层代码就会完全乱了。这种时候就需要一个异步通知的机制,也就是说当一个线程它处理完任务的时候,它不是直接去执行上程回调的,而是通过异步机制去通知主线程来执行这个回调。
 Libuv 中具体通过 fd 的方式去实现的。当线程池完成任务时,它会以原子的方式去修改这个 fd 为可读的,然后在主线程事件循环的 Poll IO 阶段时,它就会执行这个可读事件的回调,从而执行上层的回调。可以看到,Node.js 虽然是跑在多线程上面的,但是所有的 JS 代码都是跑在单个线程里的,这也是我们经常讨论的 Node.js 是单线程还是多线程的,从不同的角度去看就会得到不同的答案。
Libuv 中具体通过 fd 的方式去实现的。当线程池完成任务时,它会以原子的方式去修改这个 fd 为可读的,然后在主线程事件循环的 Poll IO 阶段时,它就会执行这个可读事件的回调,从而执行上层的回调。可以看到,Node.js 虽然是跑在多线程上面的,但是所有的 JS 代码都是跑在单个线程里的,这也是我们经常讨论的 Node.js 是单线程还是多线程的,从不同的角度去看就会得到不同的答案。
下面的图就是异步任务处理的一个大致过程。
 比如我们想读一个文件的时候,这时候主线程会把这个任务直接提交到线程池里面去处理,然后主线程就可以继续去做自己的事情了。当在线程池里面的线程完成这个任务之后,它就会往这个主线程的队列里面插入一个节点,然后主线程在 Poll IO 阶段时,它就会去执行这个节点里面的回调。
比如我们想读一个文件的时候,这时候主线程会把这个任务直接提交到线程池里面去处理,然后主线程就可以继续去做自己的事情了。当在线程池里面的线程完成这个任务之后,它就会往这个主线程的队列里面插入一个节点,然后主线程在 Poll IO 阶段时,它就会去执行这个节点里面的回调。
2.3 事件循环
了解 Libuv 的一些核心实现之后,下面我们再看一下 Libuv 中一个著名的事件循环。事件循环主要分为七个阶段,
- 第一是 timer 阶段,timer 阶段是处理定时器相关的一些任务,比如 Node.js 中的 setTimeout和 setInterval。
- 第二是 pending 的阶段, pending 阶段主要处理 Poll IO 阶段执行回调时产生的回调。
- 第三是 check、prepare 和 idle 三个阶段,这三个阶段主要处理一些自定义的任务。setImmediate 属于 check 阶段。
- 第四是 Poll IO 阶段,Poll IO 阶段主要要处理跟文件描述符相关的一些事件。
- 第五是 close 阶段, 它主要是处理,调用了 uv_close 时传入的回调。比如关闭一个 TCP 连接时传入的回调,它就会在这个阶段被执行。
下面这个图是各个阶段在事件循环的顺序图。

-
定时器
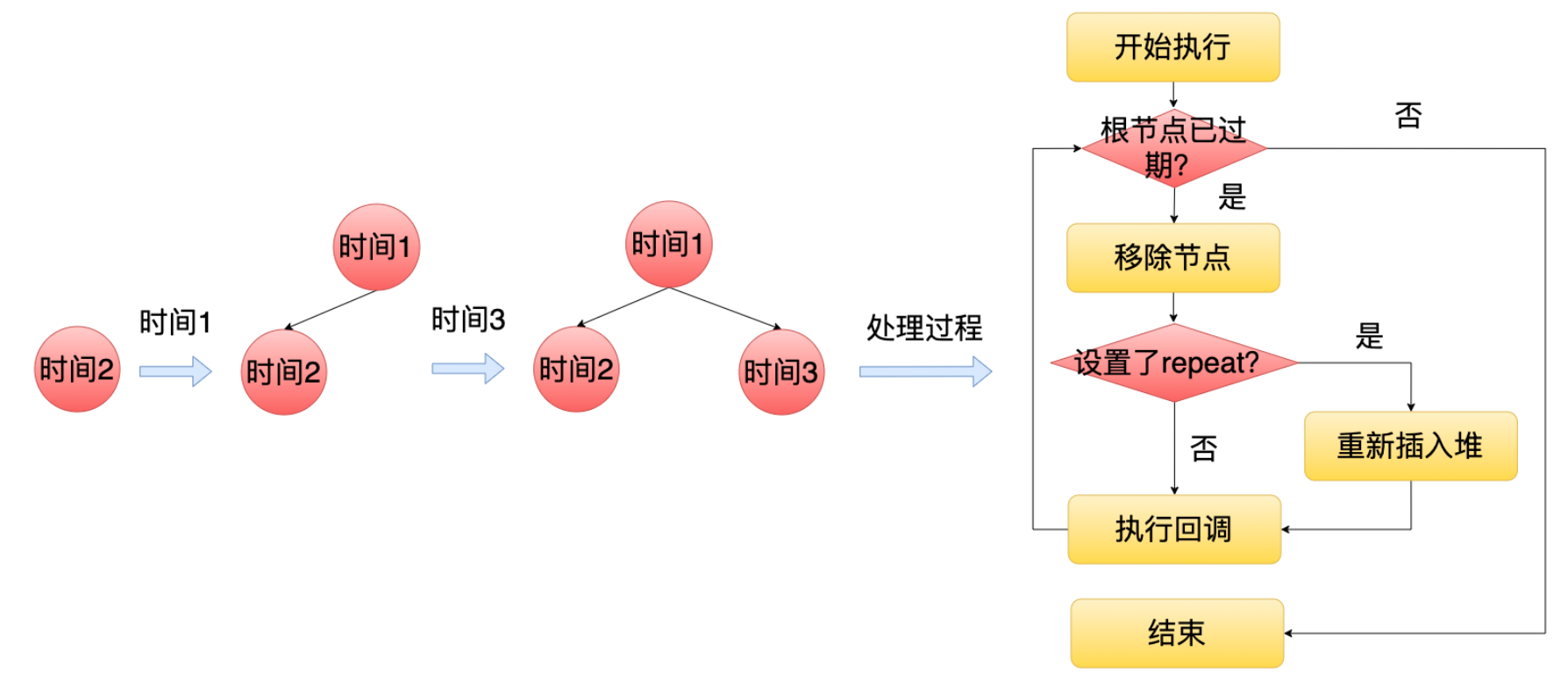 Libuv 在底层里面维护了一个最小堆,每个定时节点就是堆里面的一个节点(Node.js 只用了 Libuv 的一个定时器节点),越早超时的节点就在越上面。然后等到定时期阶段的时候, Libuv 就会从上往下去遍历这个最小堆判断当前节点有没有超时,如果没有到期的话,那么后面节点也不需要去判断了,因为最早到期的节点都没到期,那么它后面节点也显然不会到期。如果当前节点到期了,那么就会执行它的回调,并且把它移出这个最小堆。但是为了支持类似 setInterval 这种场景。如果这个节点设置了repeat 标记,那么这个节点它会被重新插入到最小堆中,等待下一次的超时。
Libuv 在底层里面维护了一个最小堆,每个定时节点就是堆里面的一个节点(Node.js 只用了 Libuv 的一个定时器节点),越早超时的节点就在越上面。然后等到定时期阶段的时候, Libuv 就会从上往下去遍历这个最小堆判断当前节点有没有超时,如果没有到期的话,那么后面节点也不需要去判断了,因为最早到期的节点都没到期,那么它后面节点也显然不会到期。如果当前节点到期了,那么就会执行它的回调,并且把它移出这个最小堆。但是为了支持类似 setInterval 这种场景。如果这个节点设置了repeat 标记,那么这个节点它会被重新插入到最小堆中,等待下一次的超时。 -
check、idle、prepare 阶段和 pending、close 阶段。
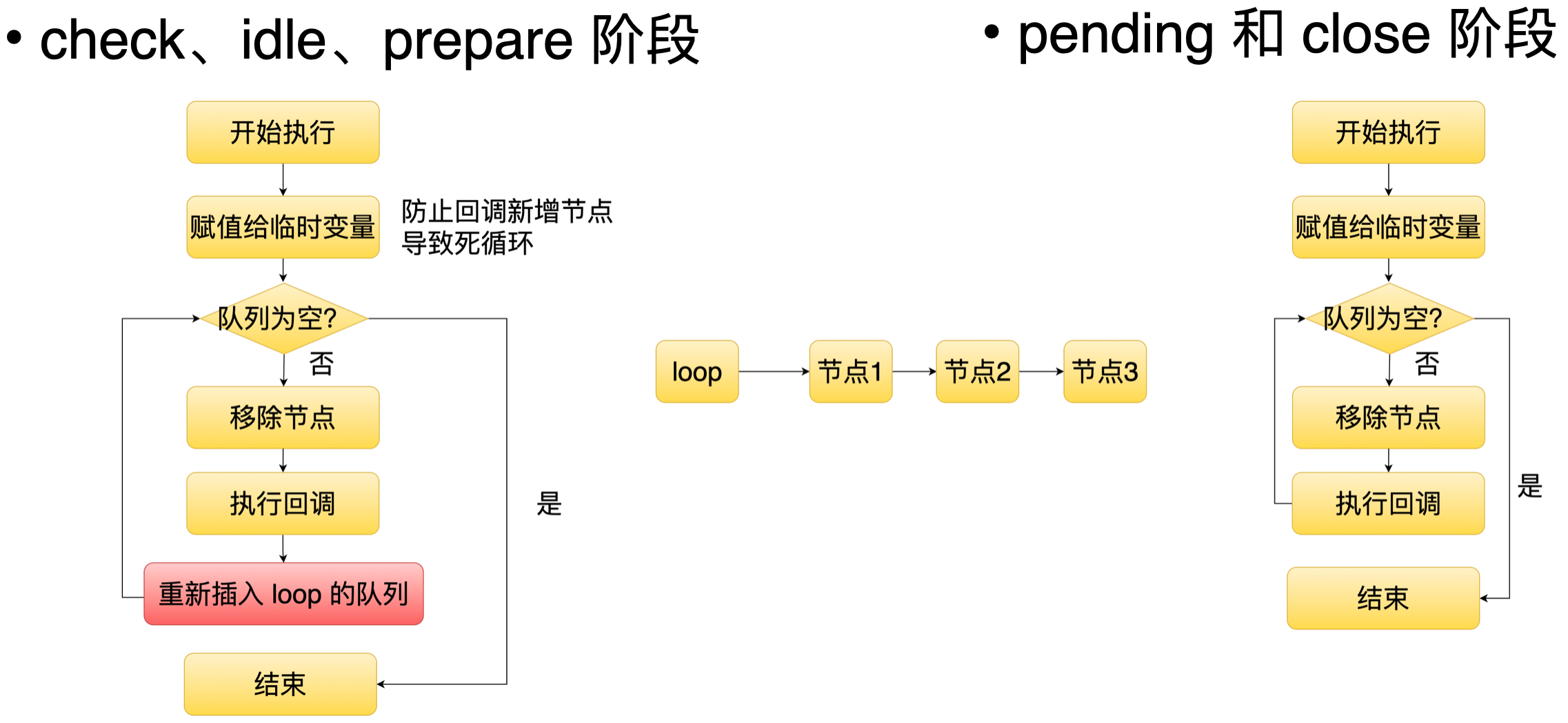 这五个阶段的实现其实类似的,它们都对应自己的一个任务队列。当产生任务的时候,它就会往这个队列里面插入一个节点,等到相应的阶段时,它就会去遍历这个队列里面的每个节点,并且执行它的回调。但是 check idle 还有 prepare 阶段有一个比较特别的地方,就是当这些阶段的节点回调被执行之后,它还会重新插入队列里面,也是说这三个阶段它对应的任务在每一轮的事件循环都会被执行。
这五个阶段的实现其实类似的,它们都对应自己的一个任务队列。当产生任务的时候,它就会往这个队列里面插入一个节点,等到相应的阶段时,它就会去遍历这个队列里面的每个节点,并且执行它的回调。但是 check idle 还有 prepare 阶段有一个比较特别的地方,就是当这些阶段的节点回调被执行之后,它还会重新插入队列里面,也是说这三个阶段它对应的任务在每一轮的事件循环都会被执行。 -
Poll IO 阶段 Poll IO 本质上是对前面讲的事件驱动模块的封装。下面来看一下整体的流程。

当我们订阅一个 fd 的事件时,Libuv 就会通过 epoll 去注册这个 fd 对应的事件。如果这时候事件没有就绪,那么进程就会阻塞在 epoll_wait 中。等到这事件触发的时候,进程就会被唤醒,唤醒之后,它就遍历 epoll 返回了事件列表,并执行上层回调。
现在有一个底层能力,那么这个底层能力是怎么暴露给上层的 JS 去使用呢?这种时候就需要用到 JS 引擎 V8了。
3. Node.js 中的 V8
下面从三个方面介绍 V8。
- 介绍 V8 在 Node.js 的作用和 V8 的一些基础概念
- 介绍如何通过 V8 执行 JS 和拓展 JS
- 介绍如何通过 V8 实现 JS 和 C++ 通信
3.1 V8 在 Node.js 的作用和基础概念
V8 在 Node.js 里面主要是有两个作用,第一个是负责解析和执行 JS。第二个是支持拓展 JS 能力,作为这个 JS 和 C++ 的桥梁。下面我们先来看一下 V8 里面那些重要的概念。
Isolate:首先第一个是 Isolate 它是代表一个 V8 的实例,它相当于这一个容器。通常一个线程里面会有一个这样的实例。比如说在 Node.js主线程里面,它就会有一个 Isolate 实例。
Context:Context 是代表我们执行代码的一个上下文,它主要是保存像 Object,Function 这些我们平时经常会用到的内置的类型。如果我们想拓展 JS 功能,就可以通过这个对象实现。
ObjectTemplate:ObjectTemplate 是用于定义对象的模板,然后我们就可以基于这个模板去创建对象。
FunctionTemplate:FunctionTemplate 和 ObjectTemplate 是类似的,它主要是用于定义一个函数的模板,然后就可以基于这个函数模板去创建一个函数。
FunctionCallbackInfo: 用于实现 JS 和 C++ 通信的对象。
Handle:Handle 是用管理在 V8 堆里面那些对象,因为像我们平时定义的对象和数组,它是存在 V8 堆内存里面的。Handle 就是用于管理这些对象。
HandleScope:HandleScope 是一个 Handle 容器,HandleScope 里面可以定义很多 Handle,它主要是利用自己的生命周期管理多个 Handle。
下面我们通过一个代码来看一下 HandleScope 和 Handle 它们之间的关系。
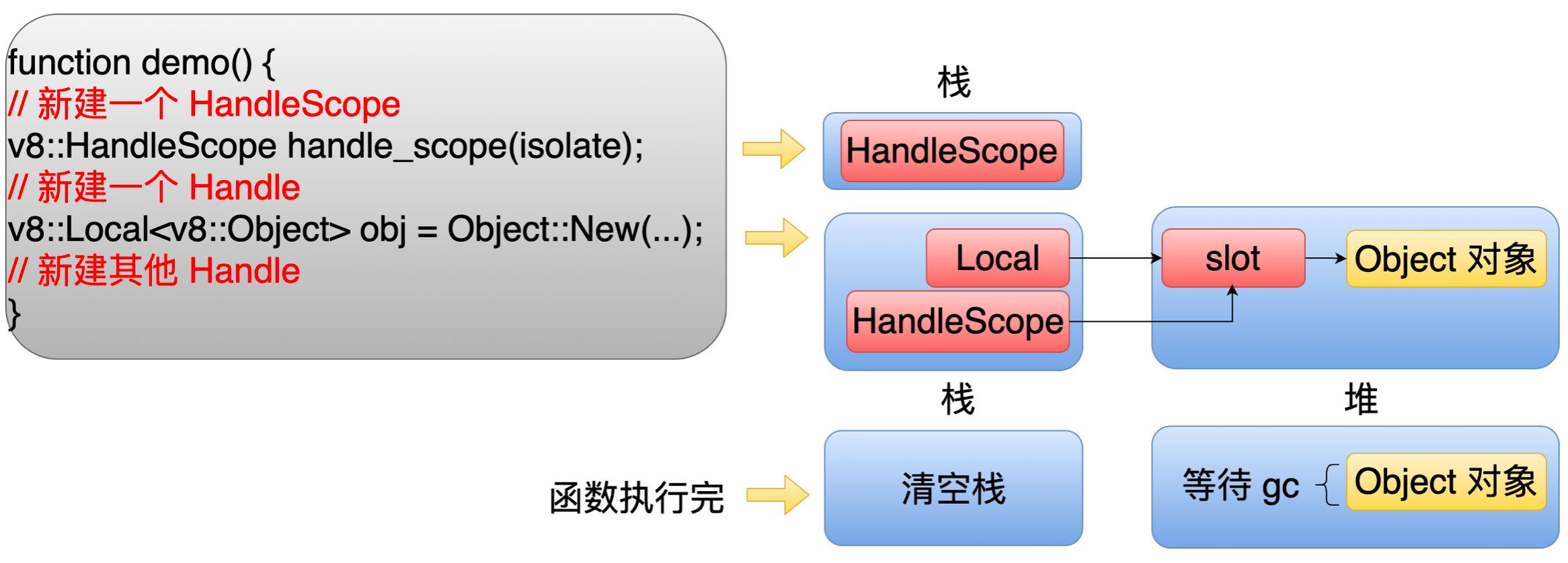 首先第一步新建一个 HandleScope,就会在一个栈里面定义一个 HandleScope 对象。然后第二步新建了一个 Handle 并且把它指向一个堆对象。这时候就会在栈里面分配一个叫 Local 对象,然后在堆里面分配一块 slot 所代表的内存和一个 Object 对象,并且建立关联关系。当执行完这个函数的时候,这个栈就会被清空,相应的这个 slot 代表的内存也会被释放,但是 Object 所代表这个对象,它是不会立马被释放的,它会等待 GC 的回收。
首先第一步新建一个 HandleScope,就会在一个栈里面定义一个 HandleScope 对象。然后第二步新建了一个 Handle 并且把它指向一个堆对象。这时候就会在栈里面分配一个叫 Local 对象,然后在堆里面分配一块 slot 所代表的内存和一个 Object 对象,并且建立关联关系。当执行完这个函数的时候,这个栈就会被清空,相应的这个 slot 代表的内存也会被释放,但是 Object 所代表这个对象,它是不会立马被释放的,它会等待 GC 的回收。
3.2 通过 V8 执行 JS 和拓展 JS
了解了 V8 的基础概念之后,来看一下怎么通过 V8 执行一段 JS 的代码。
 首先第一步新建一个 Isolate,它这表示一个隔离的实例。第二步定义一个 HandleScope 对象,因为我们下面需要定义 Handle。第三步定义一个 Context,这是代码执行所在的上下文。第四步定义一些需要被执行的 JS 代码。第五步通过 Script 对象的 Compile 函数编译 JS 代码。编译完之后,我们会得到一个 Script 对象,然后执行这个对象的 Run 函数就可以完成代码的执行。
首先第一步新建一个 Isolate,它这表示一个隔离的实例。第二步定义一个 HandleScope 对象,因为我们下面需要定义 Handle。第三步定义一个 Context,这是代码执行所在的上下文。第四步定义一些需要被执行的 JS 代码。第五步通过 Script 对象的 Compile 函数编译 JS 代码。编译完之后,我们会得到一个 Script 对象,然后执行这个对象的 Run 函数就可以完成代码的执行。
接下来再看一下怎么去拓展 JS 原有的一些能力。
 首先第一步是通过 Context 上下文对象拿到一个全局的对象,类似于在前端里面的 window 对象。第二步通过 ObjectTemplate 新建一个对象的模板,然后接着会给这个对象模板设置一个 test 属性, 值是函数。接着通过这个对象模板新建一个对象,并且把这个对象设置到一个全局变量里面去。这样我们就可以在 JS 层去访问这个全局对象。
首先第一步是通过 Context 上下文对象拿到一个全局的对象,类似于在前端里面的 window 对象。第二步通过 ObjectTemplate 新建一个对象的模板,然后接着会给这个对象模板设置一个 test 属性, 值是函数。接着通过这个对象模板新建一个对象,并且把这个对象设置到一个全局变量里面去。这样我们就可以在 JS 层去访问这个全局对象。
下面我们通过使用刚才定义那个全局对象来看一下 JS 和 C++ 是怎么通信的。
3.3 通过 V8 实现 JS 和 C++ 层通信

现在有了底层能力,有了这一层的接口,但是我们是怎么去加载后执行 JS 代码呢?这时候就需要模块加载器。
4 Node.js 中的模块加载器
Node.js 中有五种模块加载器。
- JSON 模块加载器
- 用户 JS 模块加载器
- 原生 JS 模块加载器
- 内置 C++ 模块加载器
- Addon 模块加载器
现在来看下每种模块加载器。
4.1 JSON 模块加载器
JSON 模块加载器实现比较简单,Node.js 从硬盘里面把 JSON 文件读到内存里面去,然后通过 JSON.parse 函数进行解析,就可以拿到里面的数据。
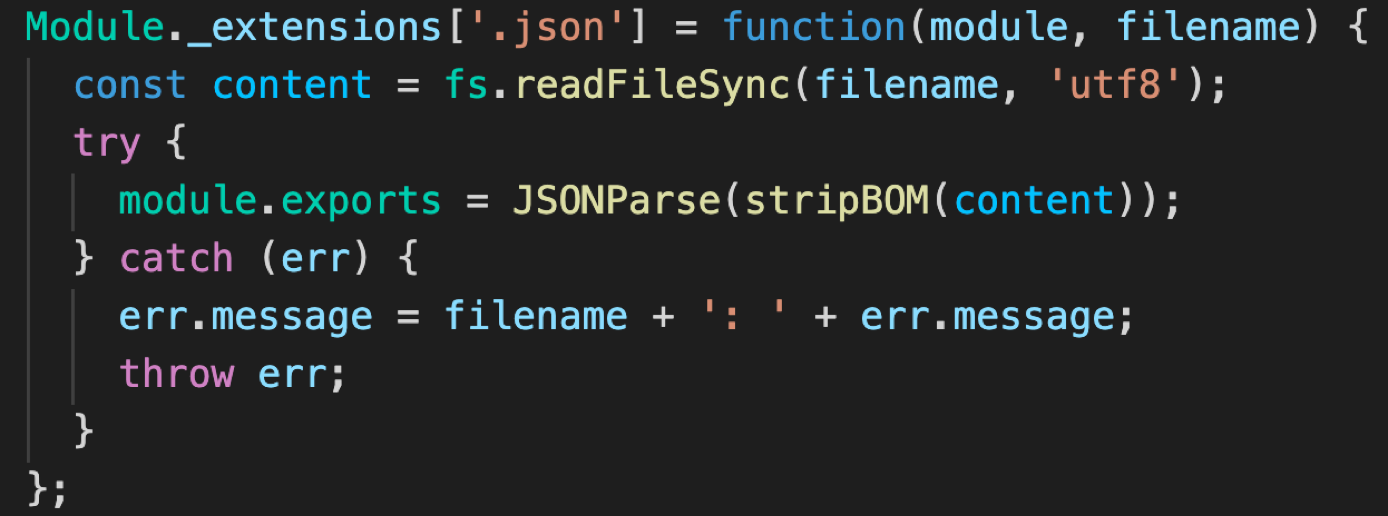
4.2 用户 JS 模块
 用户 JS 模块就是我们平时写的一些 JS 代码。当通过 require 函数加载一个用户 JS 模块时,Node.js 就会从硬盘读取这个模块的内容到内存中,然后通过 V8 提供了一个函数叫 CompileFunctionInContext 把读取的代码封装成一个函数,接着新建立一个 Module 对象。这个对象里面有两个属性叫 exports 和 require 函数,这两个对象就是我们平时在代码里面所使用的变量,接着会把这个对象作为函数的参数,并且执行这个函数,执行完这个函数的时候,就可以通过 module.exports 拿到这个函数(模块)里面导出的内容。这里需要注意的是这里的 require 函数是可以加载原生 JS 模块和用户模块的,所以我们平时在我们代码里面,可以通过require 加载我们自己写的模块,或者 Node.js 本身提供的 JS 模块。
用户 JS 模块就是我们平时写的一些 JS 代码。当通过 require 函数加载一个用户 JS 模块时,Node.js 就会从硬盘读取这个模块的内容到内存中,然后通过 V8 提供了一个函数叫 CompileFunctionInContext 把读取的代码封装成一个函数,接着新建立一个 Module 对象。这个对象里面有两个属性叫 exports 和 require 函数,这两个对象就是我们平时在代码里面所使用的变量,接着会把这个对象作为函数的参数,并且执行这个函数,执行完这个函数的时候,就可以通过 module.exports 拿到这个函数(模块)里面导出的内容。这里需要注意的是这里的 require 函数是可以加载原生 JS 模块和用户模块的,所以我们平时在我们代码里面,可以通过require 加载我们自己写的模块,或者 Node.js 本身提供的 JS 模块。
4.3 原生 JS 模块
 接下来看下原生 JS 模块加载器。原生JS 模块是 Node.js 本身提供了一些 JS 模块,比如经常使用的 http 和 fs。当通过 require 函数加载 http 这个模块的时候,Node.js 就会从内存里读取这个模块所对应内容。因为原生 JS 模块默认是打包进内存里面的,所以直接从内存里面读就可以了,不需要从硬盘里面去读。然后还是通过 V8 提供的 CompileFunctionInContext 这个函数把读取的代码封装成一个函数,接着新建一个 NativeModule 对象,同样这个对象里面也是有个 exports 属性,接着它会把这个对象传到这个函数里面去执行,执行完这函数之后,就可以通过 module.exports 拿到这个函数里面导出的内容。需要注意是这里传入的 require 函数是一个叫 NativeModuleRequire 函数,这个函数它就只能加载原生 JS 模块。另外这里还传了另外一个 internalBinding 函数,这个函数是用于加载 C++ 模块的,所以在原生 JS 模块里面,是可以加载 C++ 模块的。
接下来看下原生 JS 模块加载器。原生JS 模块是 Node.js 本身提供了一些 JS 模块,比如经常使用的 http 和 fs。当通过 require 函数加载 http 这个模块的时候,Node.js 就会从内存里读取这个模块所对应内容。因为原生 JS 模块默认是打包进内存里面的,所以直接从内存里面读就可以了,不需要从硬盘里面去读。然后还是通过 V8 提供的 CompileFunctionInContext 这个函数把读取的代码封装成一个函数,接着新建一个 NativeModule 对象,同样这个对象里面也是有个 exports 属性,接着它会把这个对象传到这个函数里面去执行,执行完这函数之后,就可以通过 module.exports 拿到这个函数里面导出的内容。需要注意是这里传入的 require 函数是一个叫 NativeModuleRequire 函数,这个函数它就只能加载原生 JS 模块。另外这里还传了另外一个 internalBinding 函数,这个函数是用于加载 C++ 模块的,所以在原生 JS 模块里面,是可以加载 C++ 模块的。
4.4 C++ 模块
 Node.js 在初始化的时候会注册 C++ 模块,并且形成一个 C++ 模块链表。当加载 C++ 模块时,Node.js 就通过模块名,从这个链表里面找到对应的节点,然后去执行它里面的钩子函数,执行完之后就可以拿到 C++ 模块导出的内容。
Node.js 在初始化的时候会注册 C++ 模块,并且形成一个 C++ 模块链表。当加载 C++ 模块时,Node.js 就通过模块名,从这个链表里面找到对应的节点,然后去执行它里面的钩子函数,执行完之后就可以拿到 C++ 模块导出的内容。
4.5 Addon 模块
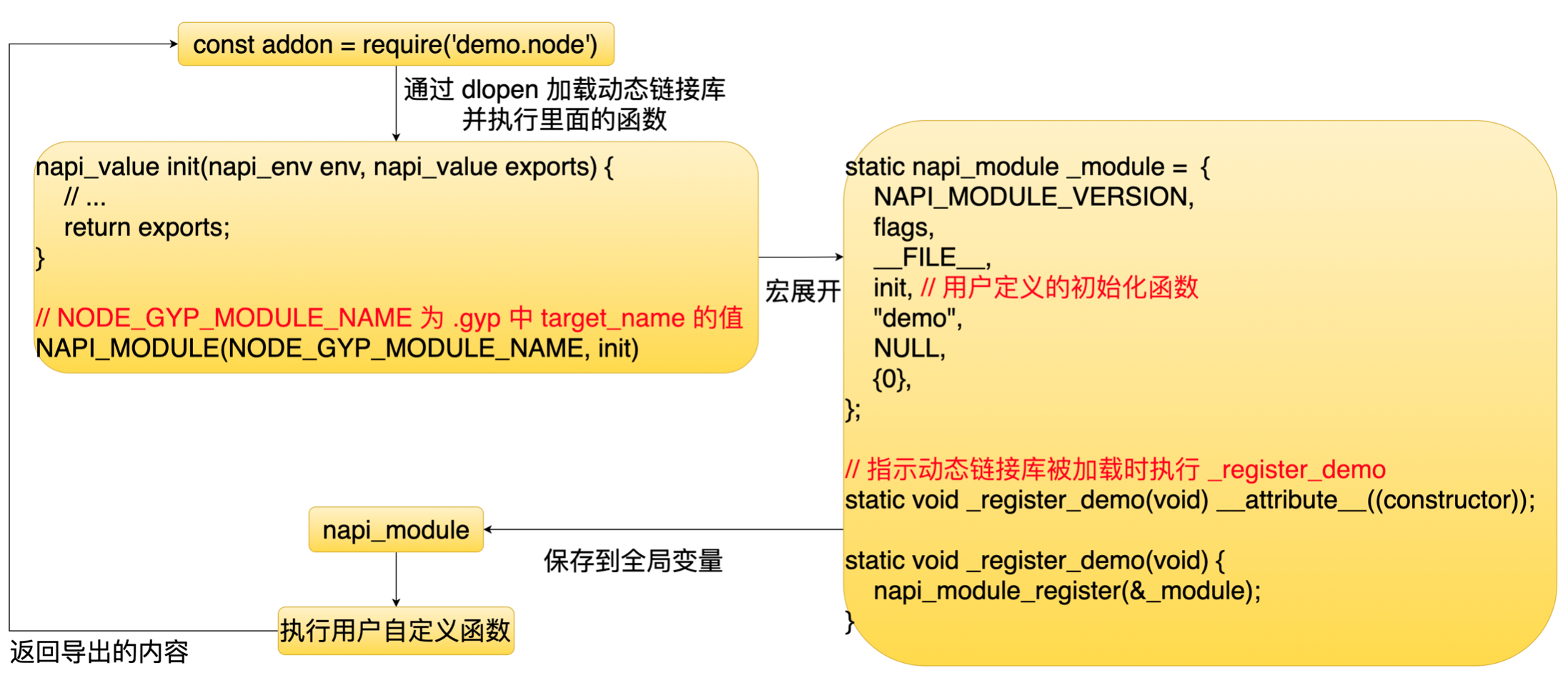 接着再来看一下 Addon 模块, Addon 模块本质上是一个动态链接库。当通过 require 加载Addon 模块的时候,Node.js 会通过 dlopen 这个函数去加载这个动态链接库。
下图是我们定义一个 Addon 模块时的一个标准格式。
接着再来看一下 Addon 模块, Addon 模块本质上是一个动态链接库。当通过 require 加载Addon 模块的时候,Node.js 会通过 dlopen 这个函数去加载这个动态链接库。
下图是我们定义一个 Addon 模块时的一个标准格式。
 它里面有一些 C语言宏,宏展开之后里面内容像下图所示。
它里面有一些 C语言宏,宏展开之后里面内容像下图所示。
 里面主要定义了一个结构体和一个函数,这个函数会把这个结构体赋值给 Node.js 的一个全局变量,然后 Nodejs 它就可以通过全局变量拿到这个结构体,并且执行它里面的一个钩子函数,执行完之后就可以拿到它里面要导出的一些内容。
里面主要定义了一个结构体和一个函数,这个函数会把这个结构体赋值给 Node.js 的一个全局变量,然后 Nodejs 它就可以通过全局变量拿到这个结构体,并且执行它里面的一个钩子函数,执行完之后就可以拿到它里面要导出的一些内容。
现在有了底层的能力,也有了这一次层的接口,也有了代码加载器。最后我们来看一下 Node.js 作为一个服务器的时候,它的架构是怎么样的?
5 Node.js 的服务器架构
下面从两个方面介绍 Node.js 的服务器架构
- 介绍服务器处理 TCP 连接的模型
- 介绍 Node.js 中的实现和存在的问题
5.1 处理 TCP 连接的模型
首先来看一下网络编程中怎么去创建一个 TCP 服务器。
int fd = socket(…);
bind(fd, 监听地址);
listen(fd);首先建一个 socket, 然后把需要监听的地址绑定到这个 socket 中,最后通过 listen 函数启动服务器。启动服务器之后,那么怎么去处理 TCP 连接呢?
-
串行处理(accept 和 handle 都会引起进程阻塞)
 第一种处理方式是串行处理,串行方式就是在一个 while 循环里面,通过 accept 函数不断地摘取 TCP 连接,然后处理它。这种方式的缺点就是它每次只能处理一个连接,处理完一个连接之后,才能继续处理下一个连接。
第一种处理方式是串行处理,串行方式就是在一个 while 循环里面,通过 accept 函数不断地摘取 TCP 连接,然后处理它。这种方式的缺点就是它每次只能处理一个连接,处理完一个连接之后,才能继续处理下一个连接。 -
多进程/多线程
 第二种方式是多进程或者多线程的方式。这种方式主要是利用多个进程或者线程同时处理多个连接。但这种模式它的缺点就是当流量非常大的时候,进程数或者线程数它会成为这种架构下面的一个瓶颈,因为我们不能无限的创建进程或者线程,像 Apache 还有 PHP 就是这种架构的。
第二种方式是多进程或者多线程的方式。这种方式主要是利用多个进程或者线程同时处理多个连接。但这种模式它的缺点就是当流量非常大的时候,进程数或者线程数它会成为这种架构下面的一个瓶颈,因为我们不能无限的创建进程或者线程,像 Apache 还有 PHP 就是这种架构的。 -
单进程单线程 + 事件驱动( Reactor & Proactor ) 第三种就是单线程 + 事件驱动的模式。这种模式下有两种类型,第一种叫 Reactor, 第二种叫 Proactor。 Reactor 模式就是应用程序可以通过事件驱动模块注册 fd 的读写事件,然后事件触发的时候,它就会通过事件驱动模块回调上层的代码。
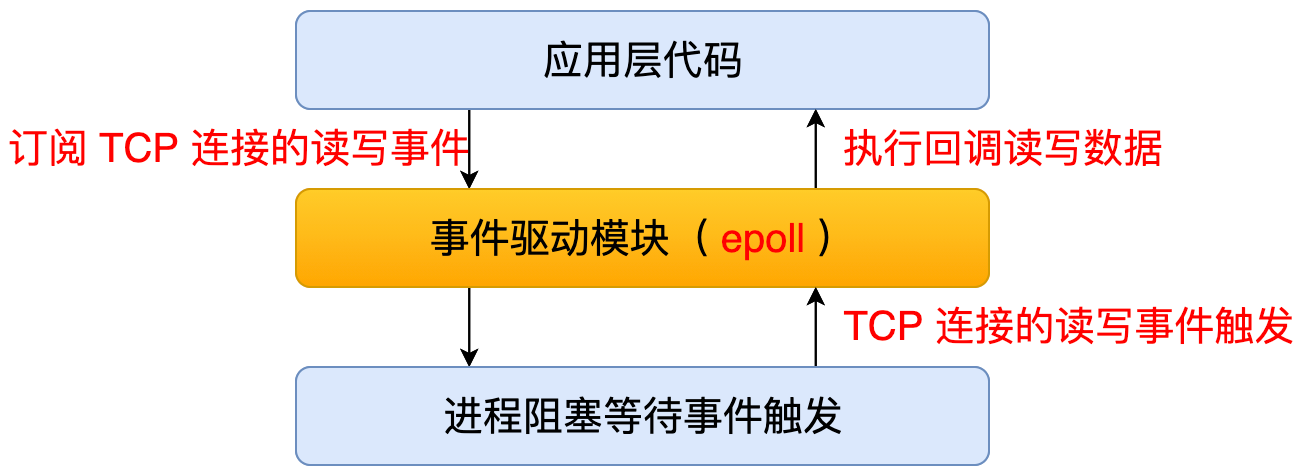 Proactor 模式就是应用程序可以通过事件驱动模块注册 fd 的读写完成事件,然后这个读写完成事件后就会通过事件驱动模块回调上层代码。
Proactor 模式就是应用程序可以通过事件驱动模块注册 fd 的读写完成事件,然后这个读写完成事件后就会通过事件驱动模块回调上层代码。
 我们看到这两种模式的区别是,数据读写是由内核完成的,还是由应用程序完成的。很显然,通过内核去完成是更高效的,但是因为 Proactor 这种模式它兼容性还不是很好,所以目前用的还不算太多,主要目前主流的一些服务器,它用的都是 Reactor 模式。比方说像 Node.js、Redis 和 Nginx 这些服务器用的都是这种模式。
我们看到这两种模式的区别是,数据读写是由内核完成的,还是由应用程序完成的。很显然,通过内核去完成是更高效的,但是因为 Proactor 这种模式它兼容性还不是很好,所以目前用的还不算太多,主要目前主流的一些服务器,它用的都是 Reactor 模式。比方说像 Node.js、Redis 和 Nginx 这些服务器用的都是这种模式。
刚才提到 Node.js 是单进程单线程加事件驱动的架构。那么单线程的架构它怎么去利用多核呢?这种时候就需要用到多进程的这种模式了,每一个进程里面会包含一个Reactor 模式。但是引入多进程之后,它会带来一个问题,就是多进程之间它怎么去监听同一个端口。
5.2 Node.js 的实现和问题
下面来看下针对多进程监听同一个端口的一些解决方式。
- 主进程监听端口并接收请求,轮询分发(轮询模式)
- 子进程竞争接收请求(共享模式)
- 子进程负载均衡处理连接(SO_REUSEPORT 模式)
第一种方式就是主进程去监听这个端口,并且接收连接。它接收连接之后,通过一定的算法(比如轮询)分发给各个子进程。这种模式。它的一个缺点就是当流量非常大的时候,这个主进程就会成为瓶颈,因为它可能都来不及接收或者分发这个连接给子进程去处理。

第二种就是主进程创建监听 socket, 然后子进程通过 fork 的方式继承这个监听的 socket, 当有一个连接到来的时候,操作系统就唤醒所有的子进程,所有子进程会以竞争的方式接收连接。这种模式,它的缺点主要是有两个,第一个就是负载均衡的问题,因为操作系统唤醒了所有的进程,可能会导致某一个进程一直在处理连接,其他其它进程都没机会处理连接。然后另外一个问题就是惊群的问题,因为操作系统唤起了所有的进程,但是只有一个进程它会处理这个连接,然后剩下进程就会被无效地唤醒。这种方式会造成一定的性能的损失。
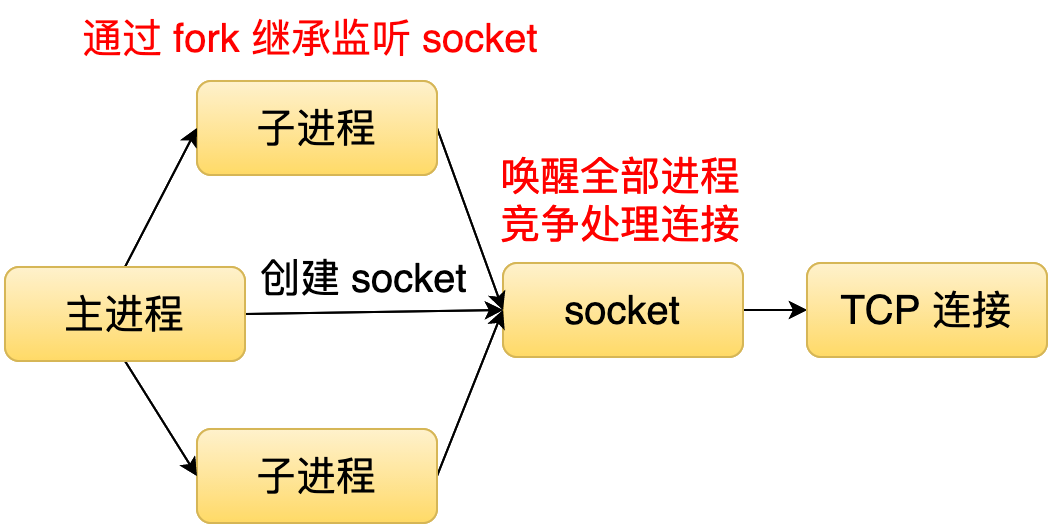
第三种通过 SO_REUSEPORT 这个标记来解决刚才提到的两个问题。在这种模式下,每个子进程都会有一个独立的监听 socket 和连接队列。当有一个连接到来的时候,操作系统会把这个连接分发给某一个子进程并且唤醒它。这样就可以解决惊群的问题,因为它只会唤醒一个子进程。又因为操作系统分发这个连接的时候,内部是有一个负载均衡的算法。所以这样的话又可以解决负载均衡的问题。
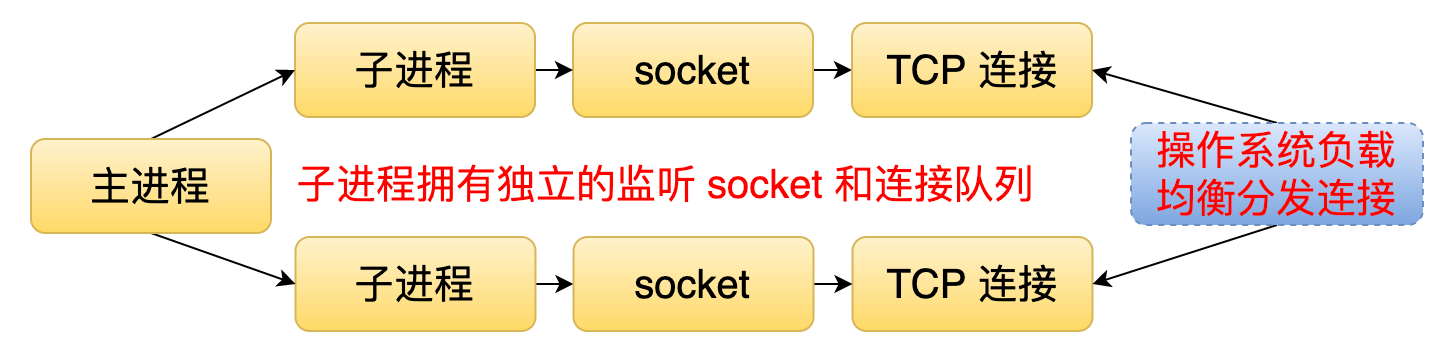
接下来我们看一下 Node.js 中的实现。
- 轮询模式。
在这种模式下,主进程会 fork 多个子进程,然后每个子进程里面都会调用 listen 函数。但是 listen 函数不会监听一个端口,它会请求主进程监听这个端口,当有连接到来的时候,这个主进程就会接收这个连接,然后通过文件描述符的方式传给各个子进程去处理。
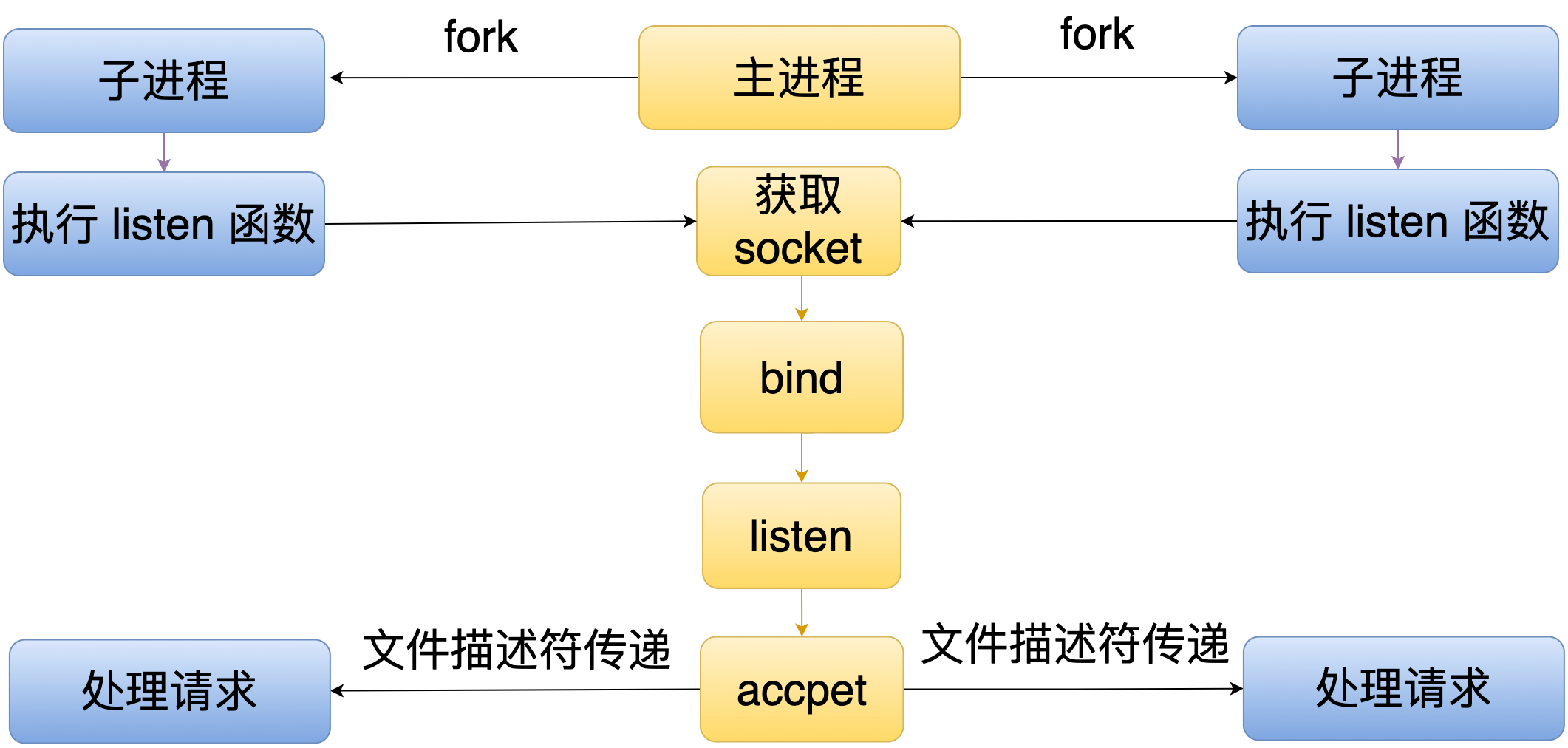
- 共享模式
共享模式下,主进程同样还是会 fork 多个子进程,然后每个子进程里面还是会执行 listen 函数,但同样的这个 listen 函数不会监听一个端口,它会请求主进程创建一个 socket 并绑定到一个需要监听的地址,接着主进程会把这个 socket 通过文件描述符传递的方式传给多个子进程,这样就可以达到多个子进程同时监听同一个端口的效果。
 通过刚才介绍,我们可以知道 Node.js 的服务器架构存在的问题。如果我们使用轮询模式,当流量比较大的时候,那么这个主进程就会成为系统瓶颈。如果我们使用共享模式,就会存在惊群和负载均衡的问题。不过在 Libuv 里面,可以通过设置 UV_TCP_SINGLE_ACCEPT 环境变量来一定程度缓解这个问题。当我们设置了这个环境变量。Libuv 在接收完一个连接的时候,它就会休眠一会,让其它进程也有接收连接的机会。
通过刚才介绍,我们可以知道 Node.js 的服务器架构存在的问题。如果我们使用轮询模式,当流量比较大的时候,那么这个主进程就会成为系统瓶颈。如果我们使用共享模式,就会存在惊群和负载均衡的问题。不过在 Libuv 里面,可以通过设置 UV_TCP_SINGLE_ACCEPT 环境变量来一定程度缓解这个问题。当我们设置了这个环境变量。Libuv 在接收完一个连接的时候,它就会休眠一会,让其它进程也有接收连接的机会。
最后来总结一下,本文的内容。Node.js 里面通过 Libuv 解决了操作系统相关的问题。通过 V8 解决了执行 JS 和拓展 JS 功能的问题。通过模块加载器解决了代码加载还有组织的问题。通过多进程的服务器架构,使得 Node.js 可以利用多核,并且解决了多个进程监听同一个端口的问题。
下面是一些资料,有兴趣的同学也可以看一下。
- 基于 epoll + V8 的JS 运行时 Just: https://github.com/theanarkh/read-just-0.1.4-code
- 基于 io_uring+ V8 的 JS 运行时 No.js: https://github.com/theanarkh/No.js
- 理解 Node.js 原理: https://github.com/theanarkh/understand-nodejs