在硬件加速渲染环境中,Android应用程序窗口的UI渲染是分两步进行的。第一步是构建Display List,发生在应用程序进程的Main Thread中;第二步是渲染Display List,发生在应用程序进程的Render Thread中。Display List的渲染不是简单地执行绘制命令,而是包含了一系列优化操作,例如绘制命令的合并执行。本文就详细分析Display List的渲染过程。
《Android系统源代码情景分析》一书正在进击的程序员网(http://0xcc0xcd.com)中连载,点击进入!
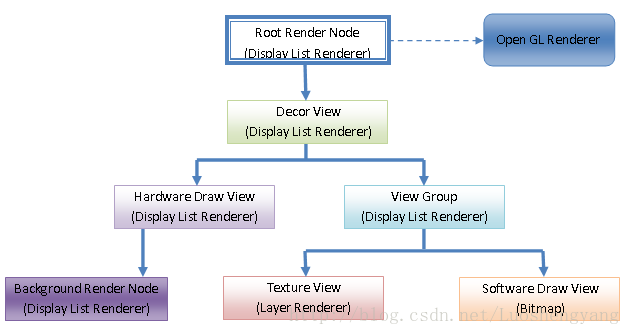
从前面Android应用程序UI硬件加速渲染的Display List构建过程分析一文可以知道,Android应用程序窗口的Root Render Node的Display List,包含了Android应用程序窗口所有的绘制命令,因此我们只要对Root Render Node的Display List进行渲染,就可以得到整个Android应用程序窗口的UI。
Android应用程序窗口的Display List的构建是通过Display List Renderer进行的,而渲染是通过Open GL Renderer进行的,如图1所示:
图1 Android应用程序窗口的Display List的渲染示意图
从图1可以知道,Open GL Renderer只作用在Android应用程序窗口的Root Render Node的Display List上,这是因为Root Render Node的Display List包含了Android应用程序窗口所有的绘制命令。
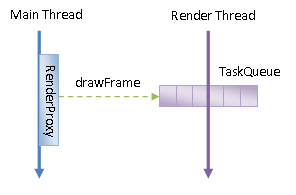
Android应用程序窗口的Display List的渲染是由Render Thread执行的,不过是由Main Thread通知Render Thread执行的,如图2所示:
图2 Main Thread向Render Thread发起渲染命令
从图2可以知道。Main Thread通过向Render Thread的TaskQueue添加一个drawFrame任务来通知Render Thread渲染Android应用程序窗口的UI。
从前面Android应用程序UI硬件加速渲染的Display List构建过程分析一文还可以知道,Android应用程序窗口的Display List构建完成之后,Main Thread就马上向Render Thread发出渲染命令,如下所示:
public class ThreadedRenderer extends HardwareRenderer {
......
@Override
void draw(View view, AttachInfo attachInfo, HardwareDrawCallbacks callbacks) {
......
updateRootDisplayList(view, callbacks);
......
if (attachInfo.mPendingAnimatingRenderNodes != null) {
final int count = attachInfo.mPendingAnimatingRenderNodes.size();
for (int i = 0; i < count; i++) {
registerAnimatingRenderNode(
attachInfo.mPendingAnimatingRenderNodes.get(i));
}
attachInfo.mPendingAnimatingRenderNodes.clear();
// We don't need this anymore as subsequent calls to
// ViewRootImpl#attachRenderNodeAnimator will go directly to us.
attachInfo.mPendingAnimatingRenderNodes = null;
}
int syncResult = nSyncAndDrawFrame(mNativeProxy, frameTimeNanos,
recordDuration, view.getResources().getDisplayMetrics().density);
if ((syncResult & SYNC_INVALIDATE_REQUIRED) != 0) {
attachInfo.mViewRootImpl.invalidate();
}
}
......
} 这个函数定义在文件frameworks/base/core/java/android/view/ThreadedRenderer.java中。
ThreadedRenderer类的成员函数draw主要执行三个操作:
1. 调用成员函数updateRootDisplayList构建或者更新应用程序窗口的Root Render Node的Display List。
2. 调用成员函数registerAnimationRenderNode注册应用程序窗口动画相关的Render Node。
3. 调用成员函数nSyncAndDrawFrame渲染应用程序窗口的Root Render Node的Display List。
其中,第一个操作在前面Android应用程序UI硬件加速渲染的Display List构建过程分析一文已经分析,第二个操作在接下来的一篇文章中分析,这篇文章主要关注第三个操作,即应用程序窗口的Root Render Node的Display List的渲染过程,即ThreadedRenderer类的成员函数nSyncAndDrawFrame的实现。
ThreadedRenderer类的成员函数nSyncAndDrawFrame是一个JNI函数,由Native层的函数android_view_ThreadedRenderer_syncAndDrawFrame实现,如下所示:
static int android_view_ThreadedRenderer_syncAndDrawFrame(JNIEnv* env, jobject clazz,
jlong proxyPtr, jlong frameTimeNanos, jlong recordDuration, jfloat density) {
RenderProxy* proxy = reinterpret_cast<RenderProxy*>(proxyPtr);
return proxy->syncAndDrawFrame(frameTimeNanos, recordDuration, density);
}这个函数定义在文件frameworks/base/core/jni/android_view_ThreadedRenderer.cpp中。
参数proxyPtr描述的是一个RenderProxy对象,这里调用它的成员函数syncAndDrawFrame渲染应用程序窗口的Display List。
RenderProxy类的成员函数syncAndDrawFrame的实现如下所示:
int RenderProxy::syncAndDrawFrame(nsecs_t frameTimeNanos, nsecs_t recordDurationNanos,
float density) {
mDrawFrameTask.setDensity(density);
return mDrawFrameTask.drawFrame(frameTimeNanos, recordDurationNanos);
}这个函数定义在文件frameworks/base/libs/hwui/renderthread/RenderProxy.cpp。
RenderProxy类的成员变量mDrawFrameTask指向的是一个DrawFrameTask对象。在前面Android应用程序UI硬件加速渲染环境初始化过程分析一文提到,这个DrawFrameTask对象描述的是一个用来执行渲染任务的Task,这里调用它的成员函数drawFrame渲染应用程序窗口的下一帧,也就是应用程序窗口的Display List。
DrawFrameTask的成员函数drawFrame的实现如下所示:
int DrawFrameTask::drawFrame(nsecs_t frameTimeNanos, nsecs_t recordDurationNanos) {
......
mSyncResult = kSync_OK;
......
postAndWait();
......
return mSyncResult;
}这个函数定义在文件frameworks/base/libs/hwui/renderthread/DrawFrameTask.cpp中。
DrawFrameTask的成员函数drawFrame最主要的操作就是调用另外一个成员函数postAndWait往Render Thread的Task Queue抛一个消息,并且进入睡眠状态,等待Render Thread在合适的时候唤醒。
DrawFrameTask的成员函数postAndWait的实现如下所示:
void DrawFrameTask::postAndWait() {
AutoMutex _lock(mLock);
mRenderThread->queue(this);
mSignal.wait(mLock);
}这个函数定义在文件frameworks/base/libs/hwui/renderthread/DrawFrameTask.cpp中。
由于DrawFrameTask类描述的就是一个可以添加到Render Thread的Task Queue的Task,因此DrawFrameTask的成员函数postAndWait就将当前正在处理的DrawFrameTask对象添加到由成员变量mRenderThread描述的Render Thread的Task Queue,并且在另外一个成员变量mSignal描述的一个条件变量上进行等待。
从前面Android应用程序UI硬件加速渲染环境初始化过程分析一文可以知道,添加到Render Thread的Task Queue的Task被处理时,它的成员函数run就会被调用,因此接下来DrawFrameTask类的成员函数run就会被调用,它的实现如下所示:
void DrawFrameTask::run() {
......
bool canUnblockUiThread;
bool canDrawThisFrame;
{
TreeInfo info(TreeInfo::MODE_FULL, mRenderThread->renderState());
canUnblockUiThread = syncFrameState(info);
canDrawThisFrame = info.out.canDrawThisFrame;
}
// Grab a copy of everything we need
CanvasContext* context = mContext;
// From this point on anything in "this" is *UNSAFE TO ACCESS*
if (canUnblockUiThread) {
unblockUiThread();
}
if (CC_LIKELY(canDrawThisFrame)) {
context->draw();
}
if (!canUnblockUiThread) {
unblockUiThread();
}
}这个函数定义在文件frameworks/base/libs/hwui/renderthread/DrawFrameTask.cpp中。
要理解这个函数首先要理解应用程序进程的Main Thread和Render Thread是如何协作的。从前面的分析可以知道,Main Thread请求Render Thread执行Draw Frame Task的时候,不能马上返回,而是进入等待状态。等到Render Thread从Main Thread同步完绘制所需要的信息之后,Main Thread才会被唤醒。
那么,Render Thread要从Main Thread同步什么信息呢?原来,Main Thread和Render Thread都各自维护了一份应用程序窗口视图信息。各自维护了一份应用程序窗口视图信息的目的,就是为了可以互不干扰,进而实现最大程度的并行。其中,Render Thread维护的应用程序窗口视图信息是来自于Main Thread的。因此,当Main Thread维护的应用程序窗口信息发生了变化时,就需要同步到Render Thread去。
应用程序窗口的视图信息包含图1所示的各个Render Node的Display List、Property以及Display List引用的Bitmap。在RenderNode类中,有六个成员变量是与Display List和Property相关的,如下所示:
class RenderNode : public VirtualLightRefBase {
public:
......
ANDROID_API void setStagingDisplayList(DisplayListData* newData);
......
const RenderProperties& stagingProperties() {
return mStagingProperties;
}
......
private:
......
uint32_t mDirtyPropertyFields;
RenderProperties mProperties;
RenderProperties mStagingProperties;
bool mNeedsDisplayListDataSync;
// WARNING: Do not delete this directly, you must go through deleteDisplayListData()!
DisplayListData* mDisplayListData;
DisplayListData* mStagingDisplayListData;
......
};这个类定义在文件frameworks/base/libs/hwui/RenderNode.h中。
其中,成员变量mStagingProperties描述的Render Properties和成员变量mStagingDisplayListData描述的Display List Data由Main Thread维护,而成员变量mProperties描述的Render Properties和成员变量mDisplayListData描述的Display List Data由Render Thread维护。
这一点可以从前面Android应用程序UI硬件加速渲染的Display List构建过程分析一文看出。当Main Thread构建完成应用程序窗口的Display List之后,就会调用RenderNode类的成员函数setStagingDisplayList将其设置到Root Render Node的成员变量mStagingDisplayListData中去。而当应用程序窗口某一个View的Property发生变化时,就会调用RenderNode类的成员函数mutateStagingProperties获得成员变量mStagingProperties描述的Render Properties,进而修改相应的Property。
当Main Thread维护的Render Properties发生变化时,成员变量mDirtyPropertyFields的值就不等于0,其中不等于0的位就表示是哪一个具体的Property发生了变化,而当Main Thread维护的Display List Data发生变化时,成员变量mNeedsDisplayListDataSync的值就等于true,表示要从Main Thread同步到Render Thread。
另外,在前面Android应用程序UI硬件加速渲染的Display List构建过程分析一文分析将一个Bitmap绘制命令转化为一个DrawBitmapOp记录在Display List时,Bitmap会被增加一个引用,如下所示:
status_t DisplayListRenderer::drawBitmap(const SkBitmap* bitmap, const SkPaint* paint) {
bitmap = refBitmap(bitmap);
paint = refPaint(paint);
addDrawOp(new (alloc()) DrawBitmapOp(bitmap, paint));
return DrawGlInfo::kStatusDone;
}这个函数定义在文件frameworks/base/libs/hwui/DisplayListRenderer.cpp中。
参数bitmap描述的SkBitmap通过调用DisplayListRenderer类的成员函数refBitmap进行使用,它的实现如下所示:
class ANDROID_API DisplayListRenderer: public StatefulBaseRenderer {
public:
......
inline const SkBitmap* refBitmap(const SkBitmap* bitmap) {
......
mDisplayListData->bitmapResources.add(bitmap);
mCaches.resourceCache.incrementRefcount(bitmap);
return bitmap;
}
......
};这个函数定义在文件frameworks/base/libs/hwui/DisplayListRenderer.h中。
DisplayListRenderer类的成员函数refBitmap在增加参数bitmap描述的一个SkBitmap的引用计数之前,会将它保存在成员变量mDisplayListData指向的一个DisplayListData对象的成员变量bitmapResources描述的一个Vector中。
上述情况是针对调用GLES20Canvas类的以下成员函数drawBitmap绘制一个Bitmap时发生的情况:
class GLES20Canvas extends HardwareCanvas {
......
@Override
public void drawBitmap(Bitmap bitmap, float left, float top, Paint paint) {
throwIfCannotDraw(bitmap);
final long nativePaint = paint == null ? 0 : paint.mNativePaint;
nDrawBitmap(mRenderer, bitmap.mNativeBitmap, bitmap.mBuffer, left, top, nativePaint);
}
......
}这个函数定义在文件frameworks/base/core/java/android/view/GLES20Canvas.java。
我们还可以调用GLES20Canvas类的另外一个重载版本的成员函数drawBitmap绘制一个Bitmap,如下所示:
class GLES20Canvas extends HardwareCanvas {
......
@Override
public void drawBitmap(int[] colors, int offset, int stride, float x, float y,
int width, int height, boolean hasAlpha, Paint paint) {
......
final long nativePaint = paint == null ? 0 : paint.mNativePaint;
nDrawBitmap(mRenderer, colors, offset, stride, x, y,
width, height, hasAlpha, nativePaint);
}
......
}这个函数定义在文件frameworks/base/core/java/android/view/GLES20Canvas.java。
GLES20Canvas类这个重载版本的成员函数drawBitmap通过一个int数组来指定要绘制的Bitmap。这个int数组是由应用程序自己管理的,并且会被封装成一个SkBitmap,最终由DisplayListRenderer类的成员函数drawBitmapData将该Bitmap绘制命令封装成一个DrawBitmapDataOp记录在Display List中,如下所示:
status_t DisplayListRenderer::drawBitmapData(const SkBitmap* bitmap, const SkPaint* paint) {
bitmap = refBitmapData(bitmap);
paint = refPaint(paint);
addDrawOp(new (alloc()) DrawBitmapDataOp(bitmap, paint));
return DrawGlInfo::kStatusDone;
}这个函数定义在文件frameworks/base/libs/hwui/DisplayListRenderer.cpp中。
DisplayListRenderer类的成员函数drawBitmapData通过另外一个成员函数refBitmapData来增加参数bitmap描述的SkBitmap的引用,如下所示:
class ANDROID_API DisplayListRenderer: public StatefulBaseRenderer {
public:
......
inline const SkBitmap* refBitmapData(const SkBitmap* bitmap) {
mDisplayListData->ownedBitmapResources.add(bitmap);
mCaches.resourceCache.incrementRefcount(bitmap);
return bitmap;
}
......
};这个函数定义在文件frameworks/base/libs/hwui/DisplayListRenderer.cpp中。
与前面分析的DisplayListRenderer类的成员函数refBitmap不同,DisplayListRenderer类的成员函数refBitmapData将参数bitmap描述的SkBitmap保存在成员变量mDisplayListData指向的一个DisplayListData对象的成员变量ownedBitmapResources描述的一个Vector中。这是由于前者引用的SkBitmap使用的底层存储是由应用程序提供和管理的,而后者引用的SkBitmap使用的底层存储是在SkBitmap内部创建和管理的。这个区别在接下来分析Bitmap的同步过程时会进一步得到体现。
Display List引用的Bitmap的同步方式与Display List和Render Property的同步方式有所不同。在同步Bitmap的时候,Bitmap将作为一个Open GL纹理上传到GPU去被Render Thread使用。
有了这些背景知识之后 ,再回到DrawFrameTask类的成员函数run中,它的执行逻辑如下所示:
1. 调用成员函数syncFrameState将应用程序窗口的Display List、Render Property以及Display List引用的Bitmap等信息从Main Thread同步到Render Thread中。注意,在这个同步过程中,Main Thread是处于等待状态的。
2. 如果成员函数syncFrameState能顺利地完成信息同步,那么它的返回值canUnblockUiThread就会等于true,表示在Render Thread渲染应用程序窗口的下一帧之前,就可以唤醒Main Thread了。否则的话,就要等到Render Thread渲染应用程序窗口的下一帧之后,才能唤醒Main Thread。唤醒Render Thread是通过调用成员函数unblockUiThread来完成的,如下所示:
void DrawFrameTask::unblockUiThread() {
AutoMutex _lock(mLock);
mSignal.signal();
}这个函数定义在frameworks/base/libs/hwui/renderthread/DrawFrameTask.cpp中。
前面Main Thread就刚好是等待在DrawFrameTask类的成员变量mSignal描述的一个条件变量之上的,所以现在Render Thread就通过这个条件变量来唤醒它。
3. 调用成员变量mContext描述的一个CanvasContext对象的成员函数draw渲染应用程序窗口的Display List,不过前提是当前帧能够进行绘制。什么时候当前帧不能够进行绘制呢?我们知道,应用程序进程绘制好一个窗口之后,得到的图形缓冲区要交给Surface Flinger进行合成,最后才能显示在屏幕上。Surface Flinger为每一个窗口都维护了一个图形缓冲区队列。当这个队列等待合成的图形缓冲区的个数大于等于2时,就表明Surface Flinger太忙了。因此这时候就最好不再向它提交图形缓冲区,这就意味着应用程序窗口的当前帧不能绘制了,也就是会被丢弃。
注意,Render Thread渲染应用程序窗口的Display List的时候,Main Thread有可能是处于等待状态,也有可能不是处于等待状态。这取决于前面的信息同步结果。信息同步结果是通过一个TreeInfo来描述的。当Main Thread不是处于等待状态时,它就可以马上处理其它事情了,例如构建应用程序窗口下一帧时使用的Display List。这样就可以做到Render Thread在绘制应用程序窗口的当前帧的同时,Main Thread可以并行地去构建应用程序窗口的下一帧的Display List。这一点也是Android 5.0引进Render Thread的好处所在。
接下来,我们就先分析应用程序窗口绘制信息的同步过程,即DrawFrameTask类的成员函数syncFrameState的实现,接着再分析应用程序窗口的Display List的渲染过程,即CanvasContext类的成员函数draw的实现。
DrawFrameTask类的成员函数syncFrameState的实现如下所示:
bool DrawFrameTask::syncFrameState(TreeInfo& info) {
......
Caches::getInstance().textureCache.resetMarkInUse();
for (size_t i = 0; i < mLayers.size(); i++) {
mContext->processLayerUpdate(mLayers[i].get());
}
......
mContext->prepareTree(info);
if (info.out.hasAnimations) {
if (info.out.requiresUiRedraw) {
mSyncResult |= kSync_UIRedrawRequired;
}
}
// If prepareTextures is false, we ran out of texture cache space
return info.prepareTextures;
}这个函数定义在文件frameworks/base/libs/hwui/renderthread/DrawFrameTask.cpp中。
应用程序进程有一个Caches单例。这个Caches单例有一个成员变量textureCache,它指向的是一个TextureCache对象。这个TextureCache对象用来缓存应用程序窗口在渲染过程中用过的Open GL纹理。在同步应用程序窗口绘制信息之前,DrawFrameTask类的成员函数syncFrameState首先调用这个TextureCache对象的成员函数resetMarkInUse将缓存的Open GL纹理标记为未使用状态。
在前面Android应用程序UI硬件加速渲染的Display List构建过程分析一文提到,当TextureView有更新时,Native层会将一个与它关联的DeferredLayerUpdater对象保存在DrawFrameTask类的成员变量mLayers描述的一个vector中。也就是说,保存在这个vector中的DeferredLayerUpdater对象,都是需要进一步处理的。需要做的处理就是从与TextureView关联的SurfaceTexture中读出下一个可用的图形缓冲区,并且将该图形缓冲区封装成一个Open GL纹理。这是通过调用DrawFrameTask类的成员变量mContext指向的一个CanvasContext对象的成员函数processLayerUpdate来实现的。
CanvasContext类的成员函数processLayerUpdate的实现如下所示:
void CanvasContext::processLayerUpdate(DeferredLayerUpdater* layerUpdater) {
bool success = layerUpdater->apply();
......
}这个函数定义在文件frameworks/base/libs/hwui/renderthread/CanvasContext.cpp中。
CanvasContext类的成员函数processLayerUpdate主要是调用参数layerUpdater描述的一个DeferredLayerUpdater对象的成员函数apply读出下一个可用的图形缓冲区,并且将该图形缓冲区封装成一个Open GL纹理,以便后面可以对它进行渲染。
DeferredLayerUpdater类的成员函数apply的实现如下所示:
bool DeferredLayerUpdater::apply() {
bool success = true;
......
if (mSurfaceTexture.get()) {
......
if (mUpdateTexImage) {
mUpdateTexImage = false;
doUpdateTexImage();
}
......
}
return success;
}这个函数定义在文件frameworks/base/libs/hwui/DeferredLayerUpdater.cpp中。
DeferredLayerUpdater类的成员变量mSurfaceTexture指向的一个是GLConsumer对象。这个GLConsumer对象用来描述与当前正在处理的DeferredLayerUpdater对象关联的TextureView对象所使用的一个SurfaceTexture对象的读端。也就是说,通过这个GLConsumer对象可以将关联的TextureView对象的下一个可用的图形缓冲区读取出来。
从前面Android应用程序UI硬件加速渲染的Display List构建过程分析一文可以知道,当一个TextureView有可用的图形缓冲区时,与它关联的DeferredLayerUpdater对象的成员变量mUpdateTexImage值会被设置为true。这时候如果当前正在处理的DeferredLayerUpdater对象的成员变量mSurfaceTexture指向了一个GLConsumer对象,那么现在就是时候去读取可用的图形缓冲区了。这是通过调用DeferredLayerUpdater类的成员函数doUpdateTexImage来实现的。
DeferredLayerUpdater类的成员函数doUpdateTexImage的实现如下所示:
void DeferredLayerUpdater::doUpdateTexImage() {
if (mSurfaceTexture->updateTexImage() == NO_ERROR) {
......
GLenum renderTarget = mSurfaceTexture->getCurrentTextureTarget();
LayerRenderer::updateTextureLayer(mLayer, mWidth, mHeight,
!mBlend, forceFilter, renderTarget, transform);
}
}这个函数定义在文件frameworks/base/libs/hwui/DeferredLayerUpdater.cpp中。
DeferredLayerUpdater类的成员函数doUpdateTexImage调用成员变量mSurfaceTexture指向的一个GLConsumer对象的成员函数updateTexImage读出可用的图形缓冲区,并且将该图形缓冲区封装成一个Open GL纹理。这个Open GL纹理可以通过调用上述的GLConsumer对象的成员函数getCurrentTextureTarget获得了。
接下来DeferredLayerUpdater类的成员函数doUpdateTexImage调用LayerRenderer类的静态成员函数updateTextureLayer将获得的Open GL纹理关联给成员变量mLayer描述的一个Layer对象。
LayerRenderer类的静态成员函数updateTextureLayer的实现如下所示:
void LayerRenderer::updateTextureLayer(Layer* layer, uint32_t width, uint32_t height,
bool isOpaque, bool forceFilter, GLenum renderTarget, float* textureTransform) {
if (layer) {
......
if (renderTarget != layer->getRenderTarget()) {
layer->setRenderTarget(renderTarget);
......
}
}
}这个函数定义在文件frameworks/base/libs/hwui/LayerRenderer.cpp中。
LayerRenderer类的静态成员函数updateTextureLayer主要就是将参数renderTarget描述的Open GL纹理设置给参数layer描述的Layer对象。这是通过调用Layer类的成员函数setRenderTarget实现的。一个Layer对象关联了Open GL纹理之后,以后就可以进行渲染了。
这一步执行完成之后,如果应用程序窗口存在需要更新的TextureView,那么这些TextureView就更新完毕,也就是这些TextureView下一个可用的图形缓冲区已经被读出,并且封装成了Open GL纹理。回到前面分析的DrawFrameTask类的成员函数syncFrameState中,接下来要做的事情是将Main Thread维护的Display List等信息同步到Render Thread中。这是通过调用DrawFrameTask类的成员变量mContext指向的一个CanvasContext对象的成员函数prepareTree实现的。
CanvasContext对象的成员函数prepareTree执行完毕之后,会通过参数info描述的一个TreeInfo对象返回一些同步结果:
1. 当这个TreeInfo对象的成员变量out指向的一个Out对象的成员变量hasAnimations等于true时,表示应用程序窗口存在未完成的动画。如果这些未完成的动画至少存在一个是非异步动画时,上述Out对象的成员变量requiresUiRedraw的值就会被设置为true。这时候DrawFrameTask类的成员变量mSyncResult的kSync_UIRedrawRequired位就会被设置为1。所谓非异步动画,就是那些在执行过程可以停止的动画。这个停止执行的逻辑是由Main Thread执行的,例如,Main Thread可以响应用户输入停止执行一个非异步动画。从前面分析可以知道,DrawFrameTask类的成员变量mSyncResult的值最后将会返回给Java层的ThreadedRenderer类的成员函数draw。ThreadedRenderer类的成员函数draw一旦发现该值的kSync_UIRedrawRequired位被设置为1,那么就会向Main Thread的消息队列发送一个INVALIDATE消息,以便在处理这个INVALIDATE消息的时候,可以响应停止执行非异步动画的请求。
接下来,我们就继续分析CanvasContext类的成员函数prepareTree的实现,以便可以了解应用程序窗口的Display List等信息的同步过程,如下所示:
void CanvasContext::prepareTree(TreeInfo& info) {
......
info.renderer = mCanvas;
......
mRootRenderNode->prepareTree(info);
......
int runningBehind = 0;
// TODO: This query is moderately expensive, investigate adding some sort
// of fast-path based off when we last called eglSwapBuffers() as well as
// last vsync time. Or something.
mNativeWindow->query(mNativeWindow.get(),
NATIVE_WINDOW_CONSUMER_RUNNING_BEHIND, &runningBehind);
info.out.canDrawThisFrame = !runningBehind;
if (info.out.hasAnimations || !info.out.canDrawThisFrame) {
if (!info.out.requiresUiRedraw) {
// If animationsNeedsRedraw is set don't bother posting for an RT anim
// as we will just end up fighting the UI thread.
mRenderThread.postFrameCallback(this);
}
}
}这个函数定义在文件frameworks/base/libs/hwui/RenderNode.cpp中。
CanvasContext类的成员变量mRootRenderNode指向的一个RenderNode对象描述的是应用程序窗口的Root Render Node,这里通过调用它的成员函数prepareTree开始对应用程序窗口的各个View的Display List进行同步。
在这个同步的过程中,如果某些View设置了动画,并且这些动还未执行完成,那么参数info指向的TreeInfo对象的成员变量hasAnimations的值就会等于true。这时候如果应用程序窗口的下一帧不可以渲染,即上述TreeInfo对象的成员变量canDrawThisFrame的值等于false,并且所有View设置的动画都是非异步的,即上述TreeInfo对象的成员变量requiresUiRedraw的值等于false,那么就需要解决一个问题,那些未执行完成的动画如何继续执行下去?因为等到当应用程序窗口的下一帧可以渲染时,这些未完成的动画还是需要继续执行的。
我们知道,当TreeInfo对象的成员变量requiresUiRedraw的值等于true时,Main Thread会自动发起渲染应用程序窗口的Display List的命令。在这个命令的执行过程中,未完成的动画是可以继续执行的。但是当TreeInfo对象的成员变量requiresUiRedraw的值等于false时,Main Thread不会自动发起渲染应用程序窗口的Display List的命令,这时候就需要向Render Thread注册一个IFrameCallback接口,这是通过调用CanvasContext类的成员变量mRenderThread指向的一个RenderThread对象的成员函数postFrameCallback实现的
从前面Android应用程序UI硬件加速渲染环境初始化过程分析一文可以知道,注册到Render Thread的IFrameCallback接口在下一个Vsync信号到来时,它的成员函数doFrame会被调用,这时候就可以执行渲染应用程序窗口的下一帧了。在渲染的过程中,就可以继续执行那些未完成的动画了。
CanvasContext类的成员变量mNativeWindow描述的就是当前绑定的应用程序窗口,通过调用它的成员函数query,并且将第二个参数设置为NATIVE_WINDOW_CONSUMER_RUNNING_BEHIND,可以查询到它提交了多少个图形缓冲区还未被处理。如果这些已提交了但是还没有被处理的图形缓冲区大于等于2,输出参数runningBehind就会等于true,这表明Surface Flinger太忙了,这时候应用程序窗口就应该丢弃当前帧,因此就将参数info指向的TreeInfo对象的成员变量canDrawThisFrame的值设置为false。
接下来我们继续分析RenderNode类的成员函数prepareTree的实现,以便可以了解对应用程序窗口的各个View的Display List的同步过程,如下所示:
void RenderNode::prepareTree(TreeInfo& info) {
......
prepareTreeImpl(info);
}这个函数定义在文件frameworks/base/libs/hwui/RenderNode.cpp中。
RenderNode类的成员函数prepareTree调用另外一个成员函数prepareTreeImpl来同步当前正在处理的Render Node的Display List等信息,后者的实现如下所示:
void RenderNode::prepareTreeImpl(TreeInfo& info) {
......
if (info.mode == TreeInfo::MODE_FULL) {
pushStagingPropertiesChanges(info);
}
uint32_t animatorDirtyMask = 0;
if (CC_LIKELY(info.runAnimations)) {
animatorDirtyMask = mAnimatorManager.animate(info);
}
......
if (info.mode == TreeInfo::MODE_FULL) {
pushStagingDisplayListChanges(info);
}
prepareSubTree(info, mDisplayListData);
pushLayerUpdate(info);
......
}这个函数定义在文件frameworks/base/libs/hwui/RenderNode.cpp中。
从前面分析的DrawFrameTask类的成员函数run可以知道,参数info指向的TreeInfo对象的成员变量mode的值等于TreeInfo::MODE_FULL,这意味着RenderNode类的成员函数prepareTreeImpl执行在同步模式中,这时候它将会执行以下五个操作:
1. 调用成员函数pushStagingPropertiesChanges同步当前正在处理的Render Node的Property。
2. 在参数info指向的TreeInfo对象的成员变量runAnitmations的值等于true的前提下,调用成员变量mAnimatorManager指向的一个AnimatorManager对象的成员函数animate执行动画相关的操作。
3. 调用成员函数pushStagingDisplayListChanges同步当前正在处理的Render Node的Display List。
4. 调用成员函数prepareSubTree同步当前正在处理的Render Node的Display List引用的Bitmap,以及当前正在处理的Render Node的子Render Node的Display List等信息。
5. 调用成员函数pushLayerUpdate检查当前正在处理的Render Node是否设置了Layer。如果设置了的话,就对这些Layer进行处理。
其中,第2个操作是与动画显示相关的,我们在接下来的一篇文章再详细分析。
与第1个操作相关的函数是RenderNode类的成员函数pushStagingPropertiesChanges,它的实现如下所示:
void RenderNode::pushStagingPropertiesChanges(TreeInfo& info) {
......
if (mDirtyPropertyFields) {
mDirtyPropertyFields = 0;
......
mProperties = mStagingProperties;
......
}
}这个函数定义在文件frameworks/base/libs/hwui/RenderNode.cpp中。
前面提到,当RenderNode类的成员变量mDirtyPropertyFields的值不等于0时,就表明Main Thread维护的Render Node的Property发生了变化,因此就需要将它同步到Render Thread去,也就是将成员变量mStagingProperties描述的RenderProperties对象转移到成员变量mProperties去。
与第3个操作相关的函数是RenderNode类的成员函数pushStagingDisplayListChanges,它的实现如下所示:
void RenderNode::pushStagingDisplayListChanges(TreeInfo& info) {
if (mNeedsDisplayListDataSync) {
mNeedsDisplayListDataSync = false;
......
deleteDisplayListData();
mDisplayListData = mStagingDisplayListData;
mStagingDisplayListData = NULL;
if (mDisplayListData) {
for (size_t i = 0; i < mDisplayListData->functors.size(); i++) {
(*mDisplayListData->functors[i])(DrawGlInfo::kModeSync, NULL);
}
}
......
}
}这个函数定义在文件frameworks/base/libs/hwui/RenderNode.cpp中。
前面提到,当RenderNode类的成员变量mNeedsDisplayListDataSync的值等于true时,就表明Main Thread维护的Render Node的Display List发生了变化,因此就需要将它同步到Render Thread去,也就是将成员变量mStagingDisplayListData描述的DisplayListData对象转移到成员变量mDisplayListData去。
在将成员变量mStagingDisplayListData描述的DisplayListData对象转移到成员变量mDisplayListData去之前,首先会调用成员函数deleteDisplayListData删除成员变量mDisplayListData原先描述的DisplayListData对象。
记录在Display List Data的绘制命令除了是一些普通的DrawOp之外,还可能是一些函数指针,这些函数指针保存在Display List Data的成员变量functors描述的一个Vector中。这些函数指针是做什么用的呢?有些绘制命令很复杂,是不能通过一个简单的DrawOp来描述的,例如它是由一系列简单的绘制命令以复杂方式组合在一起形成的。对于这些复杂的绘制命令,我们就可以通过一个函数指针来描述。当Render Thread渲染应用程序窗口的Display List遇到这些函数指针时,就会调用这些函数指针指向的函数,这样这些函数就可以在其内部实现复杂的绘制命令,或者说是完成自定义的绘制命令。
这些函数指针在应用程序窗口的Display List的渲染过程中,会被调用两次。第一次调用时,第一个参数指定为DrawGlInfo::kModeSync,表示这时候它可以执行一些同步相关的操作。第二次调用时,第二个参数指定为DrawGlInfo::kModeDraw,表示这时候可以执行一些与渲染相关的操作。
此外,我们还可以通过Java层的ThreadedRenderer类的静态成员函数invokeFunctor将一个函数指定在Render Thread执行。例如,我们希望在应用程序进程中执行一些Open GL相关的操作时,就可以将这些操作封装在一个函数中,并且将该函数的地址封装成一个Task发送到Render Thread的Task Queue中。当这个Task被Render Thread处理的时候,封装在这个Task里面的函数就会被执行。这时候传递给这些函数的第一个参数就为DrawGlInfo::kModeProcess或者DrawGlInfo::kModeProcessNoContext。其中,DrawGlInfo::kModeProcess表示Render Thread已经初好了Open GL环境,而DrawGlInfo::kModeProcessNoContext表示Render Thread还没有初始化Open GL环境。
将函数指针记录Display List中交给Main Thread和Render Thread执行以及将函数指针封装成Task交给Render Thread执行的设计主要是为了实现WebView功能的。Android系统从4.4开始,通过Chromium来实现WebView的功能。Chromium有一套非常复杂的网页渲染机制,当它通过WebView嵌入在应用程序进程执行时,就会需要利用Render Thread可以执行Open GL操作的能力来完成它自己的功能。由这些网页渲染操作很复杂,因此就最好是通过函数来描述,这样就产生了能够将函数指定在Render Thread执行的需求。以后如果有机会分析WebView然Chromium版实现,我们就会看到这一套机制是如何运行的。
回到RenderNode类的成员函数prepareTree中,与第4个操作相关的函数是RenderNode类的成员函数prepareSubTree,它的实现如下所示:
void RenderNode::prepareSubTree(TreeInfo& info, DisplayListData* subtree) {
if (subtree) {
TextureCache& cache = Caches::getInstance().textureCache;
......
if (subtree->ownedBitmapResources.size()) {
info.prepareTextures = false;
}
for (size_t i = 0; info.prepareTextures && i < subtree->bitmapResources.size(); i++) {
info.prepareTextures = cache.prefetchAndMarkInUse(subtree->bitmapResources[i]);
}
for (size_t i = 0; i < subtree->children().size(); i++) {
DrawRenderNodeOp* op = subtree->children()[i];
RenderNode* childNode = op->mRenderNode;
......
childNode->prepareTreeImpl(info);
.....
}
}
}这个函数定义在文件frameworks/base/libs/hwui/RenderNode.cpp中。
前面提到,Display List引用的Bitmap保存在它的成员变量ownedBitmapResources和bitmapResources的两个Vector中。其中,保存在Display List的成员变量ownedBitmapResources中的Bitmap的底层储存是由应用程序提供和管理的。这意味着很难维护该底层储存在Main Thread和Render Thread的一致性。例如,有可能应用程序自行修改了该底层储存的内容,但是又没有通知Render Thread进行同步。因此,当存在这样的Bitmap时,就不允许Render Thread在渲染完成应用程序窗口的一帧之前唤醒Main Thread,就是为了防止Main Thread会修改上述Bitmap的底层储存。为了达到这个目的,这时候就需要将参数info指向的一个TreeInfo对象的成员变量prepareTextures的值设置为false。
另一方面,保存在Display List的成员变量bitmapResources中的Bitmap的底层储存不是由应用程序提供和管理的,因此就能够保证它不会被随意修改而又不通知Render Thread进行同步。对于这些Bitmap,就可以将它们作为Open GL纹理上传到GPU去。这就相当于是将Bitmap从Main Thread同步到Render Thread中,因为Render Thread就通过已经上传到GPU的Open GL纹理来使用这些Bitmap。能够执行这样的同步操作的前提是Display List的成员变量ownedBitmapResources描述的Vector为空。因为当Display List的成员变量ownedBitmapResources描述的Vector不为空时,Main Thread和Render Thread在渲染应用程序窗口的一帧时是完全同步的,因此就没有必要将Bitmap从Main Thread同步到Render Thread去。
此外,对于保存在Display List的成员变量bitmapResources中的Bitmap,由于内存大小的限制,因此就不是所有的这些Bitmap都是能够作为Open GL纹理上传到GPU去的。一旦某一个Bitmap不能作为Open GL纹理上传到GPU去,那么也是需要完全同步Main Thread和Render Thread渲染应用程序窗口的一帧的。这时候就需要将参数info指向的一个TreeInfo对象的成员变量prepareTextures的值设置为false。
同步完成当前正在处理的Render Node的Display List引用的Bitmap之后,接下来RenderNode类的成员函数prepareSubTree就调用前面分析过的成员函数prepareTreeImpl来同步当前在处理的Render Node的子Render Node的Display List、Property和Display List引用的Bitmap等信息。这个过程是一直归递执行下去,直到应用程序窗口视图结构中的每一个Render Node的isplay List、Property和Display List引用的Bitmap等信息都从Main Thread同步到Render Thread为止。
上面提到的将Bitmap封装成Open GL纹理上传到GPU是通过调用TextureCache类的成员函数prefetchAndMarkInUse来实现的,如下所示:
bool TextureCache::prefetchAndMarkInUse(const SkBitmap* bitmap) {
Texture* texture = getCachedTexture(bitmap);
if (texture) {
texture->isInUse = true;
}
return texture;
}这个函数定义在文件frameworks/base/libs/hwui/TextureCache.cpp中。
TextureCache类的成员函数prefetchAndMarkInUse调用另外一个成员函数getCachedTexture将参数bitmap描述的Bitmap封装成Open Gl纹理上传到GPU中。如果能够上传成功,那么就可以获得一个Texture对象。TextureCache类的成员函数prefetchAndMarkInUse在将这个Texture对象返回给调用者之前,需要将它的成员变量isInUse设置为true,表示该Texture对象正在使用当中。
TextureCache类的成员函数getCachedTexture的实现如下所示:
Texture* TextureCache::getCachedTexture(const SkBitmap* bitmap) {
Texture* texture = mCache.get(bitmap->pixelRef());
if (!texture) {
if (!canMakeTextureFromBitmap(bitmap)) {
return NULL;
}
const uint32_t size = bitmap->rowBytes() * bitmap->height();
bool canCache = size < mMaxSize;
// Don't even try to cache a bitmap that's bigger than the cache
while (canCache && mSize + size > mMaxSize) {
Texture* oldest = mCache.peekOldestValue();
if (oldest && !oldest->isInUse) {
mCache.removeOldest();
} else {
canCache = false;
}
}
if (canCache) {
texture = new Texture();
texture->bitmapSize = size;
generateTexture(bitmap, texture, false);
mSize += size;
......
mCache.put(bitmap->pixelRef(), texture);
}
} else if (!texture->isInUse && bitmap->getGenerationID() != texture->generation) {
// Texture was in the cache but is dirty, re-upload
// TODO: Re-adjust the cache size if the bitmap's dimensions have changed
generateTexture(bitmap, texture, true);
}
return texture;
}这个函数定义在文件frameworks/base/libs/hwui/TextureCache.cpp中。
每一个Bitmap作为Open GL纹理上传到GPU后,都会为其创建一个Texture对象。这些Texture对象就保存在TextureCache类通过成员变量mCache指向的一个LruCache中。因此,当不能够在该LruCache中找到参数bitmap描述的Bitmap对应的Texture对象时,就说明该Bitmap还未作为Open GL纹理上传到过GPU中,因此接下来就需要将它作为Open GL纹理上传到GPU去。
但是参数bitmap描述的Bitmap却不一定能够成功作为Open GL纹理上传到GPU去,有两个原因:
1. Bitmap太大,超出预先设定的最大Open GL纹理的大小。这种情况通过调用TextureCache类的成员函数canMakeTextureFromBitmap进行判断。
2. 已经作为Open GL纹理上传到GPU的Bitmap太多,超出预先设定的最多可以上传到GPU的大小。
在第2种情况下,这时候TextureCache类的成员函数getCachedTexture会尝试删掉那些最早上传到GPU的现在还不处于使用状态的Open GL纹理,直到能满足将参数bitmap描述的Bitmap作为Open GL纹理上传到GPU为止。
一旦确定能够将参数bitmap描述的Bitmap作为Open GL纹理上传到GPU,那么就会调用TextureCache类的成员函数generateTexture执行具体的操作,并且创建为其创建一个Texture对象保存在成员变量mCache指向的一个LruCache中。
另一方面,如果参数bitmap描述的Bitmap之前已经作为Open GL纹理上传到过GPU中,由于现在它的内容可能已经发生了变化,因此也需要调用TextureCache类的成员函数generateTexture执行重新上传的操作。
回到RenderNode类的成员函数prepareTree中,与第5个操作相关的函数是RenderNode类的成员函数pushLayerUpdate,它的实现如下所示:
void RenderNode::pushLayerUpdate(TreeInfo& info) {
LayerType layerType = properties().layerProperties().type();
......
if (CC_LIKELY(layerType != kLayerTypeRenderLayer) || CC_UNLIKELY(!isRenderable())) {
if (CC_UNLIKELY(mLayer)) {
LayerRenderer::destroyLayer(mLayer);
mLayer = NULL;
}
return;
}
......
if (!mLayer) {
mLayer = LayerRenderer::createRenderLayer(info.renderState, getWidth(), getHeight());
......
} else if (mLayer->layer.getWidth() != getWidth() || mLayer->layer.getHeight() != getHeight()) {
if (!LayerRenderer::resizeLayer(mLayer, getWidth(), getHeight())) {
......
}
......
}
SkRect dirty;
info.damageAccumulator->peekAtDirty(&dirty);
......
if (dirty.intersect(0, 0, getWidth(), getHeight())) {
......
mLayer->updateDeferred(this, dirty.fLeft, dirty.fTop, dirty.fRight, dirty.fBottom);
}
......
if (info.renderer && mLayer->deferredUpdateScheduled) {
info.renderer->pushLayerUpdate(mLayer);
}
......
}这个函数定义在文件frameworks/base/libs/hwui/RenderNode.cpp中。
在分析RenderNode类的成员函数pushLayerUpdate的实现之前,我们首先要理解什么情况下一个Render Node会被设置为一个Layer。
当一个View的类型被设置为LAYER_TYPE_HARDWARE时,如果它的成员函数buildLayer被调用,那么与它关联的Render Node就会被设置为一个Layer。这意味着该View将会作为一个FBO(Frame Buffer Object)进行渲染。这样做主要是为了更流畅地显示一个View的动画。这一点我们在前面Android应用程序UI硬件加速渲染技术简要介绍和学习计划一文中曾经提到。
有了这个背景知识之后,我们就可以分析RenderNode类的成员函数pushLayerUpdate的实现了。
RenderNode类的成员函数pushLayerUpdate首先是判断当前正在处理的Render Node的Layer Type是否为kLayerTypeRenderLayer,也就是判断与它关联的View的类型是否设置为LAYER_TYPE_HARDWARE。如果不是,那么就不用往下执行了,因为这种情况当前正在处理的Render Node不可能设置为一个Layer。
另一方面,如果当前正在处理的Render Node的Display List还没有创建或者是空的,那么RenderNode类的成员函数pushLayerUpdate也不用往下执行了,因为这种情况当前正在处理的Render Node是无需要渲染的。判断当前正在处理的Render Node的Display List有没有创建或者是不是空的,可以通过调用RenderNode类的成员函数isRenderable来实现。
在上述两种情况下,RenderNode类的成员函数pushLayerUpdate在返回之前,会判断一下之前是否已经为当前正在处理的Render Node创建过Layer。如果创建过,那么就会调用LayerRenderer类的静态成员函数destroyLayer来销毁该Layer。
接下来就是当前正在处理的Render Node需要设置为一个Layer的情况了。如果当前正在处理的Render Node还没有设置过Layer,也就是它的成员变量mLayer的值等于NULL,那么就调用LayerRenderer类的静态成员函数createRenderLayer为它设置一个,也就是创建一个Layer对象,并且保存在它的成员变量mLayer中。
另一方面,如果当前正在处理的Render Node之前已经设置过Layer,但是该Layer的大小与当前正在处理的Render Node的大小不一致,那么就需要调用LayerRenderer类的静态成员函数resizeLayer调整廖Layer的大小。
再接下来是计算当前正在处理的Render Node是否在应用程序窗口当前要更新的脏区域中。如果在的话,那么就需要调用与它关联的Layer对象的成员函数updateDeferred来标记与它关联的Layer对象是需要进行更新处理的。
Layer类的成员函数updateDeferred的实现如下所示:
void Layer::updateDeferred(RenderNode* renderNode, int left, int top, int right, int bottom) {
requireRenderer();
this->renderNode = renderNode;
const Rect r(left, top, right, bottom);
dirtyRect.unionWith(r);
deferredUpdateScheduled = true;
}这个函数定义在文件frameworks/base/libs/hwui/Layer.cpp中。
Layer类的成员函数updateDeferred首先是调用另外一个成员函数requireRenderer检查当前正在处理的Layer对象是否已经创建有一个LayerRenderer对象了。这个LayerRenderer对象就是负责渲染当前正在处理的Layer对象的。如果还没有创建,那么就需要创建。如下所示:
void Layer::requireRenderer() {
if (!renderer) {
renderer = new LayerRenderer(renderState, this);
......
}
}这个函数定义在文件frameworks/base/libs/hwui/Layer.cpp中。
Layer类的成员函数updateDeferred接下来再记录当前正在处理的Layer对象关联的Render Node,并且更新它的脏区域,最后将成员变量deferredUpdateScheduled设置为true,表示当前正在处理的Layer对象后面还需要执行真正的更新操作,而这里只是记录了相关的更新状态信息而已。
这一步执行完成后,回到RenderNode类的成员函数pushLayerUpdate中,这时候成员变量mLayer指向的Layer对象的成员变量deferredUpdateScheduled的值是等于true的,并且参数info指向的一个TreeInfo对象的成员变量renderer的值不为空,它指向了一个OpenGLRenderer对象,因此接下来就会调用该OpenGLRenderer对象的成员函数pushLayerUpdate来将成员变量mLayer指向的Layer对象记录在内部的一个待更新的Layer列表中,如下所示:
void OpenGLRenderer::pushLayerUpdate(Layer* layer) {
if (layer) {
......
for (int i = mLayerUpdates.size() - 1; i >= 0; i--) {
if (mLayerUpdates.itemAt(i) == layer) {
return;
}
}
mLayerUpdates.push_back(layer);
......
}
}这个函数定义在文件frameworks/base/libs/hwui/OpenGLRenderer.cpp中。
OpenGLRenderer类将需要进行更新处理的Layer对象保存在成员变量mLayerUpdates描述的一个Vector中,保存在这个Vector中的Layer对象在渲染应用程序窗口的Display List的时候,就是需要进行更新处理的。
这一步执行完成之后,应用程序窗口的Display List等信息就从Main Thread同步到Render Thread了,回到DrawFrameTask类的成员函数run中,接下来就可以调用CanvasContext类的成员函数draw渲染应用程序窗口的Display List了。
CanvasContext类的成员函数draw的实现如下所示:
void CanvasContext::draw() {
......
SkRect dirty;
mDamageAccumulator.finish(&dirty);
......
status_t status;
if (!dirty.isEmpty()) {
status = mCanvas->prepareDirty(dirty.fLeft, dirty.fTop,
dirty.fRight, dirty.fBottom, mOpaque);
} else {
status = mCanvas->prepare(mOpaque);
}
Rect outBounds;
status |= mCanvas->drawRenderNode(mRootRenderNode.get(), outBounds);
......
mCanvas->finish();
......
if (status & DrawGlInfo::kStatusDrew) {
swapBuffers();
}
......
}这个函数定义在文件frameworks/base/libs/hwui/OpenGLRenderer.cpp中。
CanvasContext类的成员函数draw的执行过程如下所示:
1. 获得应用程序窗口要更新的脏区域之后,调用成员变量mCanvas指向的一个OpenGLRenderer对象的成员函数prepareDirty或者prepare执行一些初始化工作,取决于脏区域是不是空的。
2, 调用成员变量mCanvas指向的一个OpenGLRenderer对象的成员函数drawRenderNode渲染成员变量mRootRenderNode描述的应用程序窗口的Root Render Node的Display List。
4. 调用另外一个成员函数swapBuffers将前面已经绘制好的图形缓冲区提交给Surface Flinger合成和显示。
在上述四个步骤中,最重要的是第1步和第2步,因此接下来我们就分别对它们进行分析。
我们假设第1步得到的应用程序窗口要更新的脏区域不为空,因此这一步执行的就是OpenGLRenderer类的成员函数prepareDirty,它的实现如下所示:
status_t OpenGLRenderer::prepareDirty(float left, float top,
float right, float bottom, bool opaque) {
setupFrameState(left, top, right, bottom, opaque);
......
if (currentSnapshot()->fbo == 0) {
......
updateLayers();
} else {
return startFrame();
}
return DrawGlInfo::kStatusDone;
}这个函数定义在文件frameworks/base/libs/hwui/OpenGLRenderer.cpp中。
OpenGLRenderer类的成员函数prepareDirty首先是调用另外一个成员函数setupFrameState设置帧状态,它的实现如下所示:
void OpenGLRenderer::setupFrameState(float left, float top,
float right, float bottom, bool opaque) {
......
initializeSaveStack(left, top, right, bottom, mLightCenter);
......
}这个函数定义在文件frameworks/base/libs/hwui/OpenGLRenderer.cpp中。
OpenGLRenderer类的成员函数setupFrameState最主要的操作是调用另外一个成员函数initializeSaveStack初始化一个Save Stack。
OpenGLRenderer类的成员函数initializeSaveStack是从父类StatefulBaseRenderer继承下来的,它的实现如下所示:
void StatefulBaseRenderer::initializeSaveStack(float clipLeft, float clipTop,
float clipRight, float clipBottom, const Vector3& lightCenter) {
mSnapshot = new Snapshot(mFirstSnapshot,
SkCanvas::kMatrix_SaveFlag | SkCanvas::kClip_SaveFlag);
mSnapshot->setClip(clipLeft, clipTop, clipRight, clipBottom);
mSnapshot->fbo = getTargetFbo();
mSnapshot->setRelativeLightCenter(lightCenter);
mSaveCount = 1;
}这个函数定义在文件frameworks/base/libs/hwui/StatefulBaseRenderer.cpp中。
StatefulBaseRenderer类内部维护有一个Save Stack。这个Save Stack由一系列的Snapshot组成,其中最顶端的Snapshot,也就是当前使用的Snapshot,保存成员变量mSnapshot中。每一个Snapshot都是用来描述当前的一个渲染状态,例如偏移位置、裁剪区间、灯光位置等。
Snapshot有一个重要的成员变量fbo。当它的值大于0的时候,就表示要将UI渲染在一个FBO上。涉及到渲染UI的Renderer有两个,一个是LayerRenderer,另外一个是OpenGLRenderer。从前面的分析可以知道,LayerRenderer主要负责用来渲染类型为LAYER_TYPE_HARDWARE的View。这些View将会渲染在一个FBO上。OpenGLRenderer负责渲染应用程序窗口的Display List。这个Display List是直接渲染在Frame Buffer上的,也就是直接渲染在从Surface Flinger请求回来的图形缓冲区上。
LayerRenderer类继承于OpenGLRenderer类,OpenGLRenderer类又继承于StatefulBaseRenderer类。StatefulBaseRenderer类的成员函数getTargetFbo是一个虚函数,LayerRenderer类和OpenGLRenderer类都重写了它。
其中,OpenGLRenderer类的成员函数getTargetFbo的实现如下所示:
class OpenGLRenderer : public StatefulBaseRenderer {
......
virtual GLuint getTargetFbo() const {
return 0;
}
......
}这个函数定义在文件frameworks/base/libs/hwui/OpenGLRenderer.h。
从这里就可以看到,OpenGLRenderer类的成员函数getTargetFbo的返回值总是0,也就是说,OpenGLRenderer类总是直接将UI渲染在Frame Buffer上。
LayerRenderer类的成员函数getTargetFbo的实现如下所示:
GLuint LayerRenderer::getTargetFbo() const {
return mLayer->getFbo();
}这个函数定义在文件frameworks/base/libs/hwui/LayerRenderer.cpp。
LayerRenderer类的成员变量mLayer描述的是一个Layer对象。这个Layer对象关联有一个FBO对象,可以通过调用它的成员函数getFbo获得。获得FBO被LayerRenderer类的成员函数getTargetFbo返回给调用者。
回到前面分析的StatefulBaseRenderer类的成员函数initializeSaveStack中,从前面的调用过程可以知道,当前正在处理的是一个OpenGLRenderer对象,因此,成员变量mSnapshot指向的一个Snapshot对象的成员变量fbo的值等于0。
StatefulBaseRenderer类的成员函数initializeSaveStack执行完成后,回到OpenGLRenderer类的成员函数prepareDirty中,它调用另外一个成员函数currentSnapshot获得的就是父类StatefulBaseRenderer的成员变量mSnapshot描述的Snapshot对象。这个Snapshot对象的成员变量fbo的值是等于0的,因此接下来就会继续调用OpenGLRenderer类的成员函数updateLayers更新那些待更析的Layer对象。
另一方面,如果当前正在处理的是一个LayerRenderer对象,那么OpenGLRenderer类的成员函数prepareDirty调用的是另外一个成员函数startFrame执行一些Open GL初始化工作,例如设置View Port等基本操作。
由于当前正在处理的是一个OpenGLRenderer对象,因此我们接下来继续分析OpenGLRenderer类的成员函数updateLayers的实现,如下所示:
void OpenGLRenderer::updateLayers() {
......
int count = mLayerUpdates.size();
if (count > 0) {
......
for (int i = 0; i < count; i++) {
Layer* layer = mLayerUpdates.itemAt(i);
updateLayer(layer, false);
......
}
......
}
}这个函数定义在文件frameworks/base/libs/hwui/OpenGLRenderer.cpp中。
前面提到,OpenGLRenderer类的成员变量mLayerUpdates描述的一个Vector保存的都是那些需要更新的Layer对象。每一个Layer对象的更新是通过调用OpenGLRenderer类的另外一个成员函数updateLayer实现的。
OpenGLRenderer类的成员函数updateLayer的实现如下所示:
bool OpenGLRenderer::updateLayer(Layer* layer, bool inFrame) {
if (layer->deferredUpdateScheduled && layer->renderer
&& layer->renderNode.get() && layer->renderNode->isRenderable()) {
......
if (CC_UNLIKELY(inFrame || mCaches.drawDeferDisabled)) {
layer->render(*this);
} else {
layer->defer(*this);
}
......
return true;
}
return false;
}这个函数定义在文件frameworks/base/libs/hwui/OpenGLRenderer.cpp中。
从前面的分析可以知道,保存在OpenGLRenderer类的成员变量mLayerUpdates描述的一个Vector中的Layer对象,它的成员变量deferredUpdateScheduled的值是等于true的。当这些Layer对象设置有自己的Renderer,以及关联有Render Node,并且这个Render Node是可渲染的时候,就会调用它们的成员函数render进行直接更新,或者调用它们的成员函数defer进行延迟更新。
当参数inFrame的值等于true,或者OpenGLRenderer类的成员变量mCaches指向的一个Caches对象的成员变量drawDeferDisabled的值等于true时,就会调用Layer类的成员函数render进行直接更新。其中,Caches类的成员变量drawDeferDisabled用来描述是否要对Open GL操作进行合并。当它的值等于true时,就表示不要合并;否则就表示需要合并。关于Open GL操作的合并,我们在前面Android应用程序UI硬件加速渲染的预加载资源地图集服务(Asset Atlas Service)分析一文中有提到。
我们假设Open GL操作需要进行合并,即OpenGLRenderer类的成员变量mCaches指向的一个Caches对象的成员变量drawDeferDisabled等于false。从前面的调用过程可以知道,参数inFrame的值也是等于false,因此接下来OpenGLRenderer类的成员函数updateLayer就会调用Layer类的成员函数defer对参数layer描述的一个Layer对象进行更新。
Layer类的成员函数defer的实现如下所示:
void Layer::defer(const OpenGLRenderer& rootRenderer) {
......
delete deferredList;
deferredList = new DeferredDisplayList(dirtyRect);
DeferStateStruct deferredState(*deferredList, *renderer,
RenderNode::kReplayFlag_ClipChildren);
......
renderNode->computeOrdering();
renderNode->defer(deferredState, 0);
deferredUpdateScheduled = false;
}这个函数定义在文件frameworks/base/libs/hwui/Layer.cpp中。
Layer类的成员函数defer的主要工作是创建一个DeferredDisplayList对象,保存在成员变量deferredList中,然后再将该DeferredDisplayList对象封装成一个DeferStateStruct对象中。同时被封装成这个DeferStateStruct对象还有Layer类的成员变量renderer描述的一个LayerRenderer对象。
Layer类的成员变量renderNode描述的是当前正在处理的Layer对象所关联的Render Node。Layer类的成员函数defer接下来就分别调用这个Render Node的成员函数computeOrdering和defer。其中,调用Render Node的成员函数defer的时候,会将前面创建的DeferStateStruct对象作为参数传递进去。
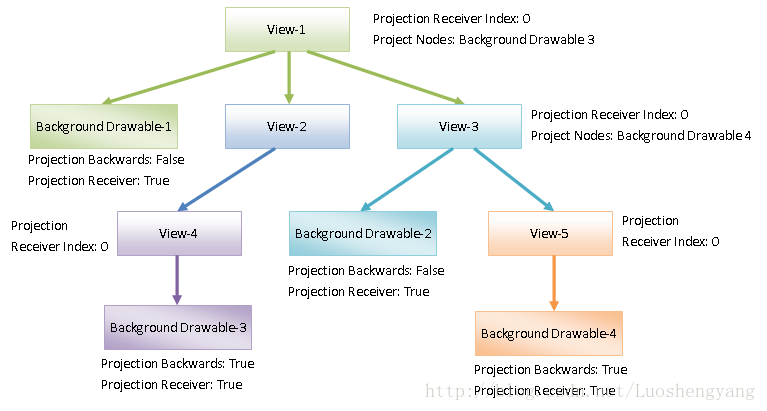
调用一个Render Node的成员函数computeOrdering,是为了找出那些需要投影到它的Background进行渲染的子Render Node。这些子Render Node称为Projected Node,如下所示:
图3 Projection Nodes
Projection Node的解释可以参考前面Android应用程序UI硬件加速渲染的Display List构建过程分析一文,RenderNode类的成员函数computeOrdering的实现我们也留给读者自己去分析。最终如果一个Rende Node具有Projected Node,那么这些Projected Node就会保存在它的成员变量mProjectedNodes中。
回到前面分析的Layer类的成员函数defer中,接下来它要调用的是RenderNode类的成员函数defer,它的实现如下所示:
void RenderNode::defer(DeferStateStruct& deferStruct, const int level) {
DeferOperationHandler handler(deferStruct, level);
issueOperations<DeferOperationHandler>(deferStruct.mRenderer, handler);
}这个函数定义在文件frameworks/base/libs/hwui/RenderNode.cpp中。
RenderNode类的成员函数defer调用另外一个成员函数issueOperations对当前正在处理的Render Node的Display List的绘制命令进行处理,具体的处理是由第二个参数指定的一个DeferOperationHandler对象的操作符重载函数()执行的,如下所示:
class DeferOperationHandler {
public:
DeferOperationHandler(DeferStateStruct& deferStruct, int level)
: mDeferStruct(deferStruct), mLevel(level) {}
inline void operator()(DisplayListOp* operation, int saveCount, bool clipToBounds) {
operation->defer(mDeferStruct, saveCount, mLevel, clipToBounds);
}
......
private:
DeferStateStruct& mDeferStruct;
const int mLevel;
};这个函数定义在文件frameworks/base/libs/hwui/RenderNode.cpp中。
参数operation指向的就是当前正在处理的Render Node的Display List的一个绘制命令,这里调用它的成员函数defer执行我们在前面Android应用程序UI硬件加速渲染的预加载资源地图集服务(Asset Atlas Service)分析一文提到的绘制命令合并操作。
接下来,我们首先分析RenderNode类的成员函数issueOperations,然后再分析一个典型的DisplayListOp的成员函数defer的实现。
RenderNode类的成员函数issueOperations的实现如下所示:
template <class T>
void RenderNode::issueOperations(OpenGLRenderer& renderer, T& handler) {
......
const bool drawLayer = (mLayer && (&renderer != mLayer->renderer));
......
bool quickRejected = properties().getClipToBounds()
&& renderer.quickRejectConservative(0, 0, properties().getWidth(), properties().getHeight());
if (!quickRejected) {
......
if (drawLayer) {
handler(new (alloc) DrawLayerOp(mLayer, 0, 0),
renderer.getSaveCount() - 1, properties().getClipToBounds());
} else {
......
for (size_t chunkIndex = 0; chunkIndex < mDisplayListData->getChunks().size(); chunkIndex++) {
const DisplayListData::Chunk& chunk = mDisplayListData->getChunks()[chunkIndex];
Vector<ZDrawRenderNodeOpPair> zTranslatedNodes;
buildZSortedChildList(chunk, zTranslatedNodes);
issueOperationsOf3dChildren(kNegativeZChildren,
initialTransform, zTranslatedNodes, renderer, handler);
for (int opIndex = chunk.beginOpIndex; opIndex < chunk.endOpIndex; opIndex++) {
DisplayListOp *op = mDisplayListData->displayListOps[opIndex];
......
handler(op, saveCountOffset, properties().getClipToBounds());
if (CC_UNLIKELY(!mProjectedNodes.isEmpty() && opIndex == projectionReceiveIndex)) {
issueOperationsOfProjectedChildren(renderer, handler);
}
}
issueOperationsOf3dChildren(kPositiveZChildren,
initialTransform, zTranslatedNodes, renderer, handler);
}
}
}
......
}这个函数定义在文件frameworks/base/libs/hwui/RenderNode.cpp中。
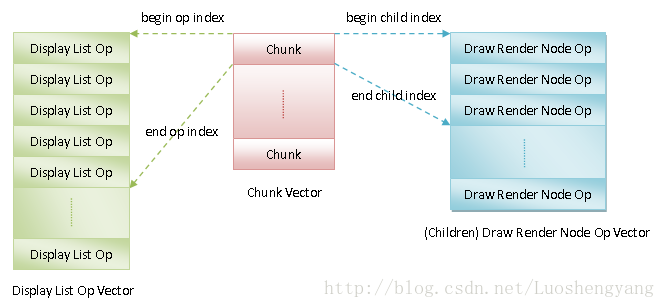
RenderNode类的成员函数issueOperations执行的操作就是对当前正在处理的Render Node的Display List的绘制命令进行重排。为什么需要重排呢?在前面Android应用程序UI硬件加速渲染的Display List构建过程分析一文中,我们分析Display List的结构,如图4所示:
图4 Display List
Display List的绘制命令以Chunk为单位进行保存。每一个Chunk通过begin op index和end op index描述的一系列Display List Op对应的就是一个Render Node包含绘制命令。此外,每一个Chunk还通过begin child index和end child index描述的一系列Draw Render Node Op对应的就是一个Render Node的子Render Node相关的绘制命令。这些子Render Node的Z轴位置相对父Render Node有可能是负的,也有可能是正的。对于Z轴位置为负的子Render Node的绘制命令,它们应该先于父Render Node的绘制命令执行。而对于Z轴位置为正的子Render Node的绘制命令,它们应该后于父Render Node的绘制命令执行。因此,每一个Chunk描述的绘制命令的排列顺序就如下所示:
Z轴位置为负的子Render Node的绘制命令。
父Render Node的绘制命令。
Z轴位置为正的子Render Node的绘制命令。
此外,如果一个Render Node的的某一个Display List Op恰好是一个图3所示的Projection Receiver,那么还需要Render Node的所有Projected Node的绘制命令排列在该Projection Receiver的后面。
如果一个Render Node设置了Layer,那么就意味着这个Render Node的所有绘制命令都是作为一个整体进行执行的。也就是说,对于设置了Layer的Render Node,我们首先需要将它的Display List的所有绘制命令合成一个整体的绘制命令,目的就是为了得到一个FBO,然后渲染这个FBO就可以得一个Render Node的UI。
对于设置了Layer的Render Node来说,它的成员函数defer会被调用两次。第一次调用的时候,就是为了将它的Display List的所有绘制命令合成一个FBO。第二次调用的时候,就是为了将合成后的FBO渲染到应用程序窗口的UI上。
这时候RenderNode类的成员函数defer属于第一次执行。那么RenderNode类的成员函数issueOperations是如何区分它是被第一次调用的成员函数defer调用,还是第二次调用的成员函数defer调用呢?主要是通过比较参数renderer描述的OpenGLRender对象和成员变量mLayer指向的一个Layer对象的成员变量renderer描述折一个OpenGLRender对象来区分。如果这两个OpenGLRenderer对象是同一个,就意味着是被第一次调用的成员函数defer调用;否则的话,就是被第二次调用的成员函数defer调用。
当RenderNode类的成员函数issueOperations是被第二次调用的成员函数defer调用的时候,该Render Node的Display List的所有绘制命令已经被合成在一个FBO里面,并且这个FBO是由它所关联的Layer对象维护的,因此这时候只需要将该Layer对象封装成一个DrawLayerOp交给参数handler描述的一个DeferOperationHandler对象处理即可。
我们再确认一下现在RenderNode类的成员函数issueOperations是被第一次调用的成员函数defer调用。它的参数renderer指向的一个OpenGLRenderer对象是从Layer类的成员函数defer传递进行的,而Layer类的成员函数defer传递进行的这个OpenGLRenderer对象就正好是与Render Node关联的Layer对象的成员变量renderer描述折一个OpenGLRender对象,因此它们就是相同的。从前面的分析可以知道,这个OpenGLRenderer对象的实际类型是LayerRenderer。
后面我们会看到,当Render Node的成员函数issueOperations是被第二次调用的成员函数defer调用的时候,它的参数renderer指向的一个OpenGLRenderer对象的实际类型就是OpenGLRenderer,它与当前正在处理的Render Node关联的Layer对象的成员变量描述折一个OpenGLRender对象不可能是相同的,因为后者的实际类型是LayerRenderer。
接下来我们就继续分析RenderNode类的成员函数issueOperations是被第一次调用的成员函数defer调用时的执行情况,这时候得到的本地变量drawLayer的值为false。
RenderNode类的成员函数issueOperations首先是判断当前正在处理的Render Node的占据的屏幕位置在应用程序窗口的当前帧中是否是可见的。如果不可见,那么得到的本地变量quickRejected的值就等于true。在这种情况下就不用做任何事情。
当本地变量quickRejected的值就等于false,并且本地变量drawLayer的值也等于false的时候,RenderNode类的成员函数issueOperations就对当前正在处理的Render Node的Display List的所有绘制命令按照我们上面描述的规则进行排序。
RenderNode类的成员函数issueOperations通过一个for循环对当前正在处理的Render Node的Display List的绘制命令按Chunk进行处理。对于每一个Chunk:
1. 调用成员函数buildZSortedChildList对其子Render Node相关的Draw Render Node Op按照Z轴位置从小到大的顺序排列在本地变量zTranslatedNodes描述的一个Vector中。
2. 调用成员函数issueOperationsOf3dChildren将Z轴位置为负的子Render Node相关的Draw Render Node Op交给参数handler描述的一个DeferOperationHandler对象处理。
3. 通过一个for循环依次将当前正在处理的Render Node相关的Display List Op交给参数handler描述的一个DeferOperationHandler对象处理。如果其中的某一个Display List Op是一个Projection Receiver,那么就继续调用成员函数issueOperationsOfProjectedChildren将当前正在处理的Render Node的Projected Node交给参数handler描述的一个DeferOperationHandler对象处理。
接下来我们继续分析RenderNode类的成员函数issueOperationsOf3dChildren和issueOperationsOfProjectedChildren的实现。
RenderNode类的成员函数issueOperationsOf3dChildren的实现如下所示:
template <class T>
void RenderNode::issueOperationsOf3dChildren(ChildrenSelectMode mode,
const Matrix4& initialTransform, const Vector<ZDrawRenderNodeOpPair>& zTranslatedNodes,
OpenGLRenderer& renderer, T& handler) {
const int size = zTranslatedNodes.size();
......
const size_t nonNegativeIndex = findNonNegativeIndex(zTranslatedNodes);
size_t drawIndex, shadowIndex, endIndex;
if (mode == kNegativeZChildren) {
drawIndex = 0;
endIndex = nonNegativeIndex;
shadowIndex = endIndex; // draw no shadows
} else {
drawIndex = nonNegativeIndex;
endIndex = size;
shadowIndex = drawIndex; // potentially draw shadow for each pos Z child
}
......
while (shadowIndex < endIndex || drawIndex < endIndex) {
......
DrawRenderNodeOp* childOp = zTranslatedNodes[drawIndex].value;
......
childOp->mSkipInOrderDraw = false; // this is horrible, I'm so sorry everyone
handler(childOp, renderer.getSaveCount() - 1, properties().getClipToBounds());
childOp->mSkipInOrderDraw = true;
......
drawIndex++;
}
......
}这个函数定义在文件frameworks/base/libs/hwui/RenderNode.cpp中。
RenderNode类的成员函数issueOperationsOf3dChildren既用来处理Z轴位置为负的子Render Node相关的Draw Render Node Op,也用来处理Z轴位置为正的子Render Node相关的Draw Render Node Op,因此它就需要根据参数mode以及参数zTranslatedNodes描述的一个Vector中Z轴位置为非负的子Render Node相关的Draw Render Node Op的索引nonNegativeIndex来确定当前需要处理的子Render Node相关的Draw Render Node Op。
由于参数zTranslatedNodes描述的一个Vector中的Draw Render Node Op是按照它们对应的子Render Node的Z轴位置由小到大的顺序排列的,因此如果参数mode的值等于kNegativeZChildren,那么当前需要处理的Draw Render Node Op在参数zTranslatedNodes描述的一个Vector中的索引范围就为[0, nonNegativeIndex)。另一方面,如果参数mode的值等于kPositiveZChildren,,那么当前需要处理的Draw Render Node Op在参数zTranslatedNodes描述的一个Vector中的索引范围就为[nonNegativeIndex, size),其中,size为参数zTranslatedNodes描述的一个Vector的大小。
确定了要处理的Draw Render Node Op在参数zTranslatedNodes描述的一个Vector的范围之后,就可以通过一个while循环对它们进行处理了,处理的方式就将它们交给参数handler描述的一个DeferOperationHandler对象。
在将要处理的Draw Render Node Op交给参数handler描述的一个DeferOperationHandler对象处理之前,有一个小Hack,这些Draw Render Node Op的成员变量mSkipInOrderDraw的值设置为false,处理完成之后再恢复为true。这样做的目的是为了当前正在处理的Render Node以相同的方式递归处理其子Render Node的Display List的绘制命令。我们在后面将会看到这一点。
我们再来看RenderNode类的成员函数issueOperationsOfProjectedChildren的实现,如下所示:
template <class T>
void RenderNode::issueOperationsOfProjectedChildren(OpenGLRenderer& renderer, T& handler) {
......
// draw projected nodes
for (size_t i = 0; i < mProjectedNodes.size(); i++) {
DrawRenderNodeOp* childOp = mProjectedNodes[i];
......
childOp->mSkipInOrderDraw = false; // this is horrible, I'm so sorry everyone
handler(childOp, renderer.getSaveCount() - 1, properties().getClipToBounds());
childOp->mSkipInOrderDraw = true;
......
}
......
}这个函数定义在文件frameworks/base/libs/hwui/RenderNode.cpp中。
RenderNode类的成员函数issueOperationsOfProjectedChildren主要就是将成员变量mProjectedNodes描述的一个Vector中的所有Draw Render Node Op都交给参数handler描述的一个DeferOperationHandler对象处理。其中,RenderNode类的成员变量mProjectedNodes描述的一个Vector应该包含哪些Projected Node就是在Layer类的成员函数defer中调用当前正在处理的Render Node的成员函数computeOrdering来计算得到的。
同样,在将要处理的Draw Render Node Op交给参数handler描述的一个DeferOperationHandler对象处理之前,这些Draw Render Node Op的成员变量mSkipInOrderDraw的值设置为false,处理完成之后再恢复为true。这样做的目的是为了当前正在处理的Render Node以相同的方式递归处理它的Projected Node的Display List的绘制命令。我们在后面将会看到这一点。
这一步执行完成之后,回到RenderNode类的成员函数issueOperations中,现在当前正在处理的Render Node的Display List的所有绘制命令都按照我们前面描述的顺序交给参数handler描述的一个DeferOperationHandler对象处理了,也就是调用该DeferOperationHandler对象的操作符重载函数()进行处理。以一个类型为DrawOp的Display List Op为例,DeferOperationHandler对象的操作符重载函数()会调用它的成员函数defer进行处理。
DrawOp类的成员函数defer的实现如下所示:
class DrawOp : public DisplayListOp {
......
virtual void defer(DeferStateStruct& deferStruct, int saveCount, int level,
bool useQuickReject) {
......
deferStruct.mDeferredList.addDrawOp(deferStruct.mRenderer, this);
}
......
};这个函数定义在文件frameworks/base/libs/hwui/DisplayListOp.h中。
DrawOp类的成员函数defer调用了参数deferStruct描述的一个DeferStateStruct对象的成员变量mDeferredList指向的一个DeferredDisplayList对象的成员函数addDrawOp检查当前正在处理的一个DrawOp是否可以与其它DrawOp进行合并,它的实现如下所示:
void DeferredDisplayList::addDrawOp(OpenGLRenderer& renderer, DrawOp* op) {
/* 1: op calculates local bounds */
DeferredDisplayState* const state = createState();
if (op->getLocalBounds(state->mBounds)) {
if (state->mBounds.isEmpty()) {
.......
return;
}
} else {
state->mBounds.setEmpty();
}
/* 2: renderer calculates global bounds + stores state */
if (renderer.storeDisplayState(*state, getDrawOpDeferFlags())) {
......
return; // quick rejected
}
/* 3: ask op for defer info, given renderer state */
DeferInfo deferInfo;
op->onDefer(renderer, deferInfo, *state);
// complex clip has a complex set of expectations on the renderer state - for now, avoid taking
// the merge path in those cases
deferInfo.mergeable &= !recordingComplexClip();
deferInfo.opaqueOverBounds &= !recordingComplexClip() && mSaveStack.isEmpty();
if (CC_LIKELY(mAvoidOverdraw) && mBatches.size() &&
state->mClipSideFlags != kClipSide_ConservativeFull &&
deferInfo.opaqueOverBounds && state->mBounds.contains(mBounds)) {
// avoid overdraw by resetting drawing state + discarding drawing ops
discardDrawingBatches(mBatches.size() - 1);
......
}
if (CC_UNLIKELY(renderer.getCaches().drawReorderDisabled)) {
// TODO: elegant way to reuse batches?
DrawBatch* b = new DrawBatch(deferInfo);
b->add(op, state, deferInfo.opaqueOverBounds);
mBatches.add(b);
return;
}
// find the latest batch of the new op's type, and try to merge the new op into it
DrawBatch* targetBatch = NULL;
// insertion point of a new batch, will hopefully be immediately after similar batch
// (eventually, should be similar shader)
int insertBatchIndex = mBatches.size();
if (!mBatches.isEmpty()) {
if (state->mBounds.isEmpty()) {
// don't know the bounds for op, so add to last batch and start from scratch on next op
DrawBatch* b = new DrawBatch(deferInfo);
b->add(op, state, deferInfo.opaqueOverBounds);
mBatches.add(b);
......
return;
}
if (deferInfo.mergeable) {
// Try to merge with any existing batch with same mergeId.
if (mMergingBatches[deferInfo.batchId].get(deferInfo.mergeId, targetBatch)) {
if (!((MergingDrawBatch*) targetBatch)->canMergeWith(op, state)) {
targetBatch = NULL;
}
}
} else {
// join with similar, non-merging batch
targetBatch = (DrawBatch*)mBatchLookup[deferInfo.batchId];
}
if (targetBatch || deferInfo.mergeable) {
// iterate back toward target to see if anything drawn since should overlap the new op
// if no target, merging ops still interate to find similar batch to insert after
for (int i = mBatches.size() - 1; i >= mEarliestBatchIndex; i--) {
DrawBatch* overBatch = (DrawBatch*)mBatches[i];
if (overBatch == targetBatch) break;
// TODO: also consider shader shared between batch types
if (deferInfo.batchId == overBatch->getBatchId()) {
insertBatchIndex = i + 1;
if (!targetBatch) break; // found insert position, quit
}
if (overBatch->intersects(state->mBounds)) {
// NOTE: it may be possible to optimize for special cases where two operations
// of the same batch/paint could swap order, such as with a non-mergeable
// (clipped) and a mergeable text operation
targetBatch = NULL;
......
break;
}
}
}
}
if (!targetBatch) {
if (deferInfo.mergeable) {
targetBatch = new MergingDrawBatch(deferInfo,
renderer.getViewportWidth(), renderer.getViewportHeight());
mMergingBatches[deferInfo.batchId].put(deferInfo.mergeId, targetBatch);
} else {
targetBatch = new DrawBatch(deferInfo);
mBatchLookup[deferInfo.batchId] = targetBatch;
}
......
mBatches.insertAt(targetBatch, insertBatchIndex);
}
targetBatch->add(op, state, deferInfo.opaqueOverBounds);
}这个函数定义在文件frameworks/base/libs/hwui/DeferredDisplayList.cpp中。
在分析DeferredDisplayList类的成员函数addDrawOp的实现之前,我们首先要了解它的三个成员变量mBatches、mBatchLookup和mMergingBatches,如下所示:
class DeferredDisplayList {
friend class DeferStateStruct; // used to give access to allocator
public:
......
enum OpBatchId {
kOpBatch_None = 0, // Don't batch
kOpBatch_Bitmap,
kOpBatch_Patch,
kOpBatch_AlphaVertices,
kOpBatch_Vertices,
kOpBatch_AlphaMaskTexture,
kOpBatch_Text,
kOpBatch_ColorText,
kOpBatch_Count, // Add other batch ids before this
};
......
private:
......
Vector<Batch*> mBatches;
// Maps batch ids to the most recent *non-merging* batch of that id
Batch* mBatchLookup[kOpBatch_Count];
......
/**
* Maps the mergeid_t returned by an op's getMergeId() to the most recently seen
* MergingDrawBatch of that id. These ids are unique per draw type and guaranteed to not
* collide, which avoids the need to resolve mergeid collisions.
*/
TinyHashMap<mergeid_t, DrawBatch*> mMergingBatches[kOpBatch_Count];
......
};这三个成员变量定义在文件frameworks/base/libs/hwui/DeferredDisplayList.h中。
可以批量进行处理的绘制命令,也就是DrawOp,放在同一个Batch中,这些Batch按照绘制先后顺序保存在DeferredDisplayList类的成员变量mBatches描述的一个Vector中。注意,这里说的批量处理,有两种含义。第一种含义是在同一个Batch中的每一个DrawOp都是单独执行的,不过它们是按顺序执行的。第二种含义是在在同一个Batch中的所有DrawOp都是一次性执行的。其中,第二种含义才称为合并执行。
两个DrawOp可以合并执行的必要条件是它们具有相同的Batch ID和Merge ID。注意,这不是充分条件。也就是说,具有相同Batch ID和Merge ID的两个Draw Op不一定能够合并执行。例如,当它们重叠,或者在它们之间存在另外的DrawOp与它们重叠。这些都会造成两个具有相同Batch ID和Merge ID的Draw Op不能合并执行。
对于具有相同Batch ID但是不同的Merge ID的两个Draw Op,我们希望它们将放在相邻的位置,因为Batch ID描述的是一种绘制类型。这些绘制类型由枚举类型OpBatchId定义。这样GPU在执行这些Draw Op时,在内部就不需要进行状态切换,这样可以提高效率。当然,也并不是所有具有相同Batch ID的DrawOp都能够放在相邻的位置,因为它们之间可能存在其它的Draw Op与它们重叠。
基于以上的分析,当给出一个DrawOp时,我们希望:
1. 在DeferredDisplayList类的成员变量mBatches描述的一个Vector中快速找可以与它进行合并执行的DrawOp所在的Batch。这时候就需要用到DeferredDisplayList类的成员变量mMergingBatches描述的是一个TinyHashMap数组了。这个数组的大小为kOpBatch_Count,这意味着每一个Batch ID在这个数组中都有一个TinyHashMap。因此,给出一个DrawOp,我们根据它的Batch ID就可以快速得到一个TinyHashMap。有了这个TinyHashMap,我们再以给出的Draw Op的Merge ID作为键值,快速找到一个Batch。接着再根据其它条件判断给出的DrawOp与在找到的Batch中已经存在的DrawOp是否能够合并。如果能够合并,就将给出的DrawOp添加到找到的Batch去就行了。
2. 如果不能在DeferredDisplayList类的成员变量mBatches描述的一个Vector中可以让它合并的Batch时,我们希望可以快速找到另外一个Batch,这个Batch的所有DrawOp都是依次地单独执行。这时候就需要用到DeferredDisplayList类的成员变量mBatchLookup描述的一个Batch数组了。这个数组的大小同样为kOpBatch_Count,这也意味着每一个Batch ID在这个数组中都有一个Batch。因此,给出一个DrawOp,我们根据它的Batch ID就可以快速得到一个Batch。接着再根据其它条件判断给出的DrawOp与在找到的Batch中已经存在的DrawOp是否能够合并。如果能够合并,就将给出的DrawOp添加到找到的Batch去就行了。
3. 如果通过上面的两个方法还是不能找到一个Batch,那么就需要创建一个新的Batch来存放给出的Draw Op。但是我们希望可以将这个新创建的Batch放在与它具有相同Batch ID的Batch相邻的位置上。
了解了DeferredDisplayList类的三个成员变量mBatches、mBatchLookup和mMergingBatches的作用之后,我们再来看另外一个结构体DeferInfo,如下所示:
struct DeferInfo {
public:
DeferInfo() :
batchId(DeferredDisplayList::kOpBatch_None),
mergeId((mergeid_t) -1),
mergeable(false),
opaqueOverBounds(false) {
};
int batchId;
mergeid_t mergeId;
bool mergeable;
bool opaqueOverBounds; // opaque over bounds in DeferredDisplayState - can skip ops below
};这个结构体定义在文件frameworks/base/libs/hwui/DeferredDisplayList.h中。
结构体DeferInfo有四个成员变量,分别是:
1. batchId:描述一个DrawOp的Batch ID。
2. mergeId:描述一个DrawOp的Merge ID。
3. mergeable:描述一个DrawOp是否具有与其它DrawOp进行合并的条件,最终能不能合并还要取决于其它条件。
4. opaqueOverBounds:描述的一个DrawOp是不是不透明绘制。如果是的话,就会可能覆盖在它前面的DrawOp,但是最终能不能覆盖同样还要取决于其它条件。
每一个DrawOp都定义有一个成员函数onDefer,用来设置一个DeferInfo结构体的各个成员变量,以便调用者可以知道它的Batch ID和Merge ID,以及它的合并和覆盖绘制信息。具体的例子可以参考前面Android应用程序UI硬件加速渲染的预加载资源地图集服务(Asset Atlas Service)分析一文。
有了上面这些知识之后,我们就开始分析上面列出的DrawOp类的成员函数defer的代码。为了描述分便,我们分段来阅读:
/* 1: op calculates local bounds */
DeferredDisplayState* const state = createState();
if (op->getLocalBounds(state->mBounds)) {
if (state->mBounds.isEmpty()) {
.......
return;
}
} else {
state->mBounds.setEmpty();
}这段代码是获得参数op描述的DrawOp的绘制区域,保存在本地变量state指向的一个DeferDisplayState结构体的成员变量mBounds中。通过调用这个DrawOp的成员函数getLocalBounds可以获得它的绘制区域。
如果这个DrawOp设置了一个空区域,那么就不会对它进行处理了。另一方面,如果这个DrawOp没有设置绘制区载,调用它的成员函数getLocalBounds得到的返回值为false,这时候会将本地变量const_state指向的一个DeferDisplayState结构体的成员变量mBounds描述的区域设置为空,但是其实想表达的意思是未设置绘制区域。
/* 2: renderer calculates global bounds + stores state */
if (renderer.storeDisplayState(*state, getDrawOpDeferFlags())) {
......
return; // quick rejected
}这段代码调用参数renderer描述的一个OpenGLRender对象的成员函数storeDisplayState设置参数op描述的DrawOp的裁剪区域。如果参数op描述的DrawOp描述的绘制区域与当前的裁剪区域没有交集,那么就说明该DrawOp是不可见的,因此就不用对它进行绘制了,于是就不用往下处理了。
/* 3: ask op for defer info, given renderer state */
DeferInfo deferInfo;
op->onDefer(renderer, deferInfo, *state);
// complex clip has a complex set of expectations on the renderer state - for now, avoid taking
// the merge path in those cases
deferInfo.mergeable &= !recordingComplexClip();
deferInfo.opaqueOverBounds &= !recordingComplexClip() && mSaveStack.isEmpty();
这段代码调用参数op描述的DrawOp获得一个初始好的DeferInfo结构体,也就是获得参数op描述的DrawOp的Batch ID和Merge ID,以及合并和覆盖绘制信息。
如果参数op描述的DrawOp表明自己可以与其它具有相同Batch ID和Merge ID的DrawOp合并,但是如果当前的裁剪区域是一个复杂的裁剪区域,也就是由一系列正则的矩形组合形成的复杂区域,那么就会禁止op描述的DrawOp与其它具有相同Batch ID和Merge ID的DrawOp合并。
同样,如果参数op描述的DrawOp表明自己的绘制会覆盖前面的DrawOp,但是如果当前的裁剪区域是一个复杂的裁剪区域,或者当前是绘制在一个Layer上,那么就会禁止op描述的DrawOp覆盖前面的DrawOp。
复杂的裁剪区域会导致具有相同Batch ID和Merge ID的DrawOp不能正确地合并,同时也会导致不透明的DrawOp不能正确地覆盖前面的DrawOp。另外,如果参数op描述的DrawOp是绘制在一个Layer之上,也就是在它之前有一个saveLayer操作,该操作会创建一个Layer,那么后面会有一个对应的restore/restoreToCount操作。当执行restore/restoreToCount操作的时候,前面绘制出来的Layer会被合并在前一个Layer或者Frame Buffer之上。这个合并的操作导致参数op描述的DrawOp不能直接就覆盖前面的DrawOp,也就是丢弃前面的DrawOp。
if (CC_LIKELY(mAvoidOverdraw) && mBatches.size() &&
state->mClipSideFlags != kClipSide_ConservativeFull &&
deferInfo.opaqueOverBounds && state->mBounds.contains(mBounds)) {
// avoid overdraw by resetting drawing state + discarding drawing ops
discardDrawingBatches(mBatches.size() - 1);
......
}这段代码综合判断参数op描述的DrawOp是否能够覆盖排在前面的DrawOp。如果以下条件都能满足,那么参数op描述的DrawOp是否能够覆盖排在前面的DrawOp:
1. 当前设置了禁止过度绘制,即DeferredDisplayList类的成员变量mAvoidOverdraw的值等于true。在启用过度绘制的情况下,即使是被覆盖的区域,也要进行绘制。这样才能将看到过度绘制。
2. 在参数op描述的DrawOp之前,已经存在其它的DrawOp,也就是DeferredDisplayList类的成员变量mBatches描述的一个Vector不为空,这样才有DrawOp被覆盖。
3. 参数op描述的DrawOp明确设置有绘制区域。如果参数op描述的DrawOp没有设置绘制区域,那么本地变量state指向的一个state指向的一个DeferDisplayState结构体的成员变量mClipSideFlags的值会被设置为kClipSide_ConservativeFull。未设置绘制区域的DrawOp,我们就不能明确地知道它会不会覆盖之前的DrawOp。
参数op描述的DrawOp表明自己是不透明绘制,即本地变量deferInfo描述的一个DeferInfo结构体的成员变量opaqueOverBounds的值等于ture。
参数op描述的DrawOp的绘制区域包含了之前的DrawOp合并起来的绘制区域。
这些排在前面的DrawOp就保存在DeferredDisplayList类的成员变量mBatches描述的一个Vector中。如果能够覆盖,那么就可以丢弃它们,实际上就是调用DeferredDisplayList类的成员函数discardDrawingBatches清空上述Vector。
if (CC_UNLIKELY(renderer.getCaches().drawReorderDisabled)) {
// TODO: elegant way to reuse batches?
DrawBatch* b = new DrawBatch(deferInfo);
b->add(op, state, deferInfo.opaqueOverBounds);
mBatches.add(b);
return;
}如果参数renderer描述的一个OpenGLRenderer表明自己禁止重新排序它的DrawOp,也就是禁止执行DrawOp的合并操作,这时候就会直接为参数op描述的DrawOp创建一个Batch,并且保存在DeferredDisplayList类的成员变量mBatches描述的一个Vector中。这意味着每一个DrawOp都会有独立保存一个Batch中,这样就可以避免出现合并操作。
// find the latest batch of the new op's type, and try to merge the new op into it
DrawBatch* targetBatch = NULL;
// insertion point of a new batch, will hopefully be immediately after similar batch
// (eventually, should be similar shader)
int insertBatchIndex = mBatches.size();
if (!mBatches.isEmpty()) {
if (state->mBounds.isEmpty()) {
// don't know the bounds for op, so add to last batch and start from scratch on next op
DrawBatch* b = new DrawBatch(deferInfo);
b->add(op, state, deferInfo.opaqueOverBounds);
mBatches.add(b);
......
return;
}这段代码判断在参籹op描述的DrawOp之前,是否已经存在其它的DrawOp。如果存在,但是参籹op描述的DrawOp又没有设置绘制区域,那么即使前面的DrawOp能够与它进行合并,那么也是禁止的。这时候就单独为它创建一个Batch,并且保存在DeferredDisplayList类的成员变量mBatches描述的一个Vector中。
if (deferInfo.mergeable) {
// Try to merge with any existing batch with same mergeId.
if (mMergingBatches[deferInfo.batchId].get(deferInfo.mergeId, targetBatch)) {
if (!((MergingDrawBatch*) targetBatch)->canMergeWith(op, state)) {
targetBatch = NULL;
}
}
} else {
// join with similar, non-merging batch
targetBatch = (DrawBatch*)mBatchLookup[deferInfo.batchId];
}如果参数op描述的DrawOp表明自己可以与其它具有相同Batch ID和Merge ID的DrawOp进行合并,那么这段代码就按照我们前面描述的,通过DeferredDisplayList类的成员变量mMergingBatches描述的一个TinyHashMap数组,快速找到一个具有相同Batch ID和Merge ID的Batch。如果能找到这样的Batch,还需要调用这个Batch的成员函数canMergeWith判断已经存在该Batch的DrawOp是否能够真的与参数op描述的DrawOp进行合并。例如,对于Batch ID等于kOpBatch_Text的两个文字绘制DrawOp,如果文字的颜色不一样,那么这两个DrawOp合并。
如果参数op描述的DrawOp表明自己不可以与其它DrawOp进行合并,那么这段代码也是按照我们前面描述的,通过DeferredDisplayList类的成员变量mBatchLookup描述的一个Batch数组,找到一个与它具有相同的Batch ID的Batch,以便将参数op描述的DrawOp加入到这个Batch去进行依次的独立绘制。
if (targetBatch || deferInfo.mergeable) {
// iterate back toward target to see if anything drawn since should overlap the new op
// if no target, merging ops still interate to find similar batch to insert after
for (int i = mBatches.size() - 1; i >= mEarliestBatchIndex; i--) {
DrawBatch* overBatch = (DrawBatch*)mBatches[i];
if (overBatch == targetBatch) break;
// TODO: also consider shader shared between batch types
if (deferInfo.batchId == overBatch->getBatchId()) {
insertBatchIndex = i + 1;
if (!targetBatch) break; // found insert position, quit
}
if (overBatch->intersects(state->mBounds)) {
// NOTE: it may be possible to optimize for special cases where two operations
// of the same batch/paint could swap order, such as with a non-mergeable
// (clipped) and a mergeable text operation
targetBatch = NULL;
......
break;
}
}
}
}这段代码判断参数op描述的DrawOp是否真的能加入到前面找到的Batch去,主要就是判断参数op描述的DrawOp与找到的Batch里面的DrawOp之间,是否存在其它的DrawOp与它重叠。如果存在,那么就不能够将参数op描述的DrawOp是否真的能加入到前面找到的Batch去了。这意味着要为参数op描述的DrawOp创建一个独立的Batch。这个Batch也是按照我们前面描述的,尽可能放在前面与它具有相同Batch ID的Batch的相邻位置。这个位置就通过设置本地变量insertBatchIndex的值得到。
if (!targetBatch) {
if (deferInfo.mergeable) {
targetBatch = new MergingDrawBatch(deferInfo,
renderer.getViewportWidth(), renderer.getViewportHeight());
mMergingBatches[deferInfo.batchId].put(deferInfo.mergeId, targetBatch);
} else {
targetBatch = new DrawBatch(deferInfo);
mBatchLookup[deferInfo.batchId] = targetBatch;
}
......
mBatches.insertAt(targetBatch, insertBatchIndex);
}
targetBatch->add(op, state, deferInfo.opaqueOverBounds);这段代码判断本地变量targetBatch的值。如果等于NULL,那么就表明前面不能在DeferredDisplayList类的成员变量mBatches描述的一个Vector中找到一个能够用来保存参数op描述的DrawOp的Batch。这时候就需要为参数op描述的DrawOp创建一个Batch了。这个Batch的具体类型要么是MergingDrawBatch,要么是DrawBatch,取决于参数op描述的DrawOp是否表明自己是可合并的,即本地变量deferInfo描述的一个DeferInfo结构体的成员变量mergeable的值是否为true。
如果参数op描述的DrawOp表明自己是可合并的,那么就为它创建一个MergingDrawBatch,并且保存在DeferredDisplayList类的成员变量mMergingBatches描述的一个TinyHashMap数组中,使得它后面的与它具有相同Batch ID和Merge ID的DrawOp能够快速找到它。
如果参数op描述的DrawOp表明自己是不可以合并的,那么就为它创建一个DrawBatch,并且保存在DeferredDisplayList类的成员变量mBatchLookup描述的一个Batch数组中,以便它后面的与它具有相同Batch ID的DrawOp能够快速找到它。
这意味着保存在同一个MergingDrawBatch的DrawOp,在渲染的时候是可以进合并绘制的,而保存在同一个rawBatch的DrawOp,在渲染的时候是可以连续地进行独立绘制的。
最后,新创建的Batch就根据前面得到的本地变量insertBatchIndex的值保存在DeferredDisplayList类的成员变量mBatches描述的一个Vector中,使得该Batch尽可能地与它具有同的Batch ID的Batch放在一起。
另一方面,如果本地变量targetBatch的值不等于NULL,那么就表明前面找到了一个Batch,这个Batch可以用来保存参数op描述的DrawOp。
这样,当DeferredDisplayList类的成员addDrawOp执行完成之后,当前正在处理的所有DrawOp都经过合并等处理了,并且处理后得到的DrawOp以Batch为单位保存在DeferredDisplayList类的成员变量mBatches描述的一个Vector中。
上面描述的是一个普通的DrawOp的成员函数defer被调用时所执行的绘制命令重排和合并操作。还有另外一种特殊的Display List Op,即DrawRenderNodeOp。从前面的分析可以知道,当一个Render Node包含有子Render Node时,它的Display List包含有一个对应的DrawRenderNodeOp。此外,当一个Render Node具有Projected Node时,每一个Projected Node都有一个对应的DrawRenderNodeOp保存该Render Node的成员变量mProjectedNodes描述的一个Vector。所有的这些DrawRenderNodeOp也像DrawOp一样,会被DeferOperationHandler类的操作符重载函数()调用它们的成员函数defer。
DrawRenderNodeOp类的成员函数defer的实现如下所示:
class DrawRenderNodeOp : public DrawBoundedOp {
......
virtual void defer(DeferStateStruct& deferStruct, int saveCount, int level,
bool useQuickReject) {
if (mRenderNode->isRenderable() && !mSkipInOrderDraw) {
mRenderNode->defer(deferStruct, level + 1);
}
}
......
};这个函数定义在文件frameworks/base/libs/hwui/DisplayListOp.h中。
DrawRenderNodeOp类的成员变量mRenderNode描述的是当前正在处理的DrawRenderNodeOp所关联的一个Render Node。当这个Render Node的Display List不为空时,就表示这个Render Node的Display List的绘制命令需要执行重排和合并操作。
此外,DrawRenderNodeOp类还有另外一个成员变量mSkipInOrderDraw。当它的值等于true时,就表示当前正在处理的DrawRenderNodeOp所关联的Render Node要跳过顺序绘制。这是什么意思呢?其实这是针对我们前面提到的Ripple Drawable的。我们知道,Ripple Drawable有可能不是按照它们在视图结构的顺序绘制的,因为它们有可能会被投影到最近一个父Render Node的Backround去绘制。这样当它们对应的Render Node在顺序绘制中就应该跳过处理。
在我们这个情景中,这里的DrawRenderNodeOp类的成员函数defer并不是在顺序绘制过程中被调用的,而是在重排和合并一个Render Node的Display List的绘制命令的过程中调用的,也就是在前面分析的RenderNode类的成员函数issueOperationsOf3dChildren和issueOperationsOfProjectedChildren中调用的。这两个成员函数需要强制DrawRenderNodeOp类的成员函数defer重排和合并当前正在处理的DrawRenderNodeOp所关联的一个Render Node的Display List的绘制命令,因此就会强制当前正在处理的DrawRenderNodeOp的成员变量mSkipInOrderDraw设置为false。
这样,当一个DrawRenderNodeOp的成员变量mSkipInOrderDraw的值为false,并且它关联的Render Node的Display List不为空,这个Render Node的成员函数defer就会被调用。这意味着通过DrawRenderNodeOp类的成员函数defer,一个Render Node及其所有的子Render Node和Projected Node的Display List的绘制命令都会得到归递重排和合并处理。
这一步执行完成之后,回到CanvasContext类的成员函数draw中,这时候所有设置了Layer的Render Node的Display List包含的Display List Op都已经得到了重排和合并等处理,接下来要做的事情就是调用OpenGLRenderer类的成员函数drawRenderNode渲染应用程序窗口的Root Render Node的Display List。
OpenGLRenderer类的成员函数drawRenderNode的实现如下所示:
status_t OpenGLRenderer::drawRenderNode(RenderNode* renderNode, Rect& dirty, int32_t replayFlags) {
status_t status;
// All the usual checks and setup operations (quickReject, setupDraw, etc.)
// will be performed by the display list itself
if (renderNode && renderNode->isRenderable()) {
// compute 3d ordering
renderNode->computeOrdering();
if (CC_UNLIKELY(mCaches.drawDeferDisabled)) {
status = startFrame();
ReplayStateStruct replayStruct(*this, dirty, replayFlags);
renderNode->replay(replayStruct, 0);
return status | replayStruct.mDrawGlStatus;
}
bool avoidOverdraw = !mCaches.debugOverdraw && !mCountOverdraw; // shh, don't tell devs!
DeferredDisplayList deferredList(*currentClipRect(), avoidOverdraw);
DeferStateStruct deferStruct(deferredList, *this, replayFlags);
renderNode->defer(deferStruct, 0);
flushLayers();
status = startFrame();
return deferredList.flush(*this, dirty) | status;
}
// Even if there is no drawing command(Ex: invisible),
// it still needs startFrame to clear buffer and start tiling.
return startFrame();
}这个函数定义在文件frameworks/base/libs/hwui/OpenGLRenderer.cpp。
参数renderNode描述的是应用程序窗口的Root Render Node,如果它的值不等于NULL,并且它是可渲染的,即调用它的成员函数isRenderable的返回值为true,那么接下来就开始渲染的它的Display List。
在渲染应用程序窗口的Root Render Node之前,OpenGLRenderer类的成员函数drawRenderNode首先调用它的成员函数computeOrdering计算它的Projected Node。这一步与前面LayerRenderer类渲染设置了Layer的Render Node的Display List的过程是一样的,都是为重排那些Projected Node,使得它们的渲染顺序位于要投影到的Render Node的后面。
OpenGLRenderer类的成员函数drawRenderNode接下来判断当前是否禁止重排应用程序窗口的Root Render Node的Display List的绘制命令,也就是不允许对这些绘制命令进行合并。如果是禁止的话,那么OpenGLRenderer类的成员变量mCaches指向的一个Caches对象的成员变量drawDeferDisabled的值就会等于true。在这种情况下,就会跳过应用程序窗口的Root Render Node的Display List的绘制命令的重排阶段,而直接对它们进行执行。这是通过调用RenderNode类的成员函数replay实现的。
如果当前不禁止重排应用程序窗口的Root Render Node的Display List的绘制命令,那么OpenGLRenderer类的成员函数drawRenderNode接下来做的事情就是调用前面分析过的RenderNode类的成员函数defer对应用程序窗口的Root Render Node及其子Render Node和Projected Node的的Display List的绘制命令进行合并操作。合并后得到的绘制命令,也就是DrawOp,就以Batch为单位保存在本地变量deferredList描述的一个DeferredDisplayList对象的成员变量mBatches描述的一个Vector中。
这里有一点需要注意的是,在调用RenderNode类的成员函数defer合并应用程序窗口的Root Render Node的Display List的绘制命令的时候,传递进去的DeferStateStruct结构体封装的Renderer是一个OpenGLRenderer。这意味着如果应用程序窗口的Root Render Node包含了一个设置了Layer的子RenderNode,那么当调用到RenderNode类的成员函数issueOperations递归处理该子RenderNode时候,这个子RenderNode就直接以一个DrawLayerOp进行绘制。这是由于这时候这个子RenderNode的成员变量renderer指向的OpenGLRenderer对象的实际类型是LayerRenderer,而参数renderer指向OpenGLRenderer对象的实际类型就是OpenGLRenderer。这两个OpenGLRenderer对象的不相等,就使得本地变量drawLayer的值等于true,于是该子RenderNode的绘制命令就被封装为一个DrawLayerOp。这样做是合理的,因为这个子RenderNode的Display List的绘制命令之前已经被重排和合并过了。
重排和合并完成应用程序窗口的Root Render Node及其子Render Node和Projected Node的Display List的绘制命令之后,本来就可以执行它们了。但是在执行它们之前,还有一件事情需要做,就是先执行那些设置了Layer的子Render Node的绘制命令,以便得到一个对应的FBO。这些FBO就代表了那些设置了Layer的子Render Node的UI。这一步是通过调用OpenGLRenderer类的成员函数flush来完成的。
OpenGLRenderer类的成员函数flush的实现如下所示:
void OpenGLRenderer::flushLayers() {
int count = mLayerUpdates.size();
if (count > 0) {
......
// Note: it is very important to update the layers in order
for (int i = 0; i < count; i++) {
......
Layer* layer = mLayerUpdates.itemAt(i);
layer->flush();
......
}
......
mRenderState.bindFramebuffer(getTargetFbo());
......
}
}这个函数定义在文件frameworks/base/libs/hwui/OpenGLRenderer.cpp。
从前面的分析可以知道,OpenGLRenderer类的成员变量mLayerUpdates描述的一个Vector里面存放的都是设置了Layer的Render Node关联的Layer,并且这些Render Noder的Display List的绘制命令都是已经经过了重排和合并等操作的。
对于保存在上述Vector中的每一个Layer,OpenGLRenderer类的成员函数flushLayers都会调用它的成员函数flush,目的就是执行这些Layer关联的Render Node的Display List经过重排和合并后的绘制命令。
Layer类的成员函数flush的实现如下所示:
void Layer::flush() {
// renderer is checked as layer may be destroyed/put in layer cache with flush scheduled
if (deferredList && renderer) {
......
renderer->prepareDirty(dirtyRect.left, dirtyRect.top, dirtyRect.right, dirtyRect.bottom,
!isBlend());
deferredList->flush(*renderer, dirtyRect);
......
}
}这个函数定义在文件frameworks/base/libs/hwui/Layer.cpp中。
从前面的分析可以知道,这时候正在处理的Layer对象的成员变量renderer和deferredList的值均不等于NULL,它们分别指向了一个LayerRenderer对象和一个DeferredDisplayList对象,因此Layer类的成员函数flush接下来就分别调用了这两个对象的成员函数prepareDirty和flush。
LayerRenderer类的成员函数prepareDirty的实现如下所示:
status_t LayerRenderer::prepareDirty(float left, float top, float right, float bottom,
bool opaque) {
......
renderState().bindFramebuffer(mLayer->getFbo());
......
return OpenGLRenderer::prepareDirty(dirty.left, dirty.top, dirty.right, dirty.bottom, opaque);
}这个函数定义在文件frameworks/base/libs/hwui/LayerRenderer.cpp中。
LayerRenderer类的成员函数prepareDirty做了一件很重要的事情,就是在从成员变量mLayer指向的一个Layer对象获得一个FBO,并且将该FBO设置当前Open GL环境的渲染对象,这意味着后续的Open GL绘制命令都是将UI渲染在该FBO上。
LayerRenderer类的成员函数prepareDirty最后还调用了父类OpenGLRenderer的成员函数prepareDirty。前面我们在分析OpenGLRenderer类的成员函数prepareDirty的时候提到,如果当前正在处理的一个LayerRenderer对象,那么它所做的事情是调用OpenGLRenderer类的另外一个成员函数startFrame。OpenGLRenderer类的成员函数startFrame仅仅是负责执行一些诸如清理颜色绘冲区等基本操作。当然,这里清理的是从成员变量mLayer指向的一个Layer对象获得一个FBO的颜色绘冲区。
这一步执行完成之后,回到Layer类的成员函数flush中,它接下来调用DeferredDisplayList类的成员函数flush,目的是为了将当前正在处理的Layer关联的Render Node的Display List渲染在上述的FBO上。
DeferredDisplayList类的成员函数flush的实现如下所示:
status_t DeferredDisplayList::flush(OpenGLRenderer& renderer, Rect& dirty) {
......
status |= replayBatchList(mBatches, renderer, dirty);
......
return status;
}这个函数定义在文件frameworks/base/libs/hwui/DeferredDisplayList.cpp中。
前面提到,DeferredDisplayList类的成员变量mBatches描述的一个Vector存放的就是一个设置了Layer的Render Node的Display List经过重排和合并后的绘制命令,这些绘制命令通过DeferredDisplayList类的另外一个成员函数replayBatchList执行。
DeferredDisplayList类的成员函数replayBatchList的实现如下所示:
static status_t replayBatchList(const Vector<Batch*>& batchList,
OpenGLRenderer& renderer, Rect& dirty) {
status_t status = DrawGlInfo::kStatusDone;
for (unsigned int i = 0; i < batchList.size(); i++) {
if (batchList[i]) {
status |= batchList[i]->replay(renderer, dirty, i);
}
}
......
return status;
}这个函数定义在文件frameworks/base/libs/hwui/DeferredDisplayList.cpp中。
DeferredDisplayList类的成员函数replayBatchList依次调用参数batchList描述的一个Vector中的每一个Batch对象的成员函数replay。从前面分析的DeferredDisplayList类的成员函数addDrawOp可以知道,参数batchList描述的一个Vector中的每一个Batch对象的实际类型要么是DrawBatch,要么是MergingDrawBatch,因此我们接下来就继续分析DrawBatch类和MergingDrawBatch类的成员函数replay的实现。
DrawBatch类的成员函数replay的实现如下所示:
class DrawBatch : public Batch {
public:
......
virtual status_t replay(OpenGLRenderer& renderer, Rect& dirty, int index) {
......
status_t status = DrawGlInfo::kStatusDone;
......
for (unsigned int i = 0; i < mOps.size(); i++) {
DrawOp* op = mOps[i].op;
......
status |= op->applyDraw(renderer, dirty);
.....
}
return status;
}
......
};这个函数定义在文件frameworks/base/libs/hwui/DeferredDisplayList.cpp中。
DrawBatch类的成员函数replay依次调用存放在成员变量mOps描述的一个Vector中的每一个DrawOp的成员函数applyDraw,以便这些DrawOp可以转化为Open GL绘制命令进行执行。
以一个具体的DrawRectOp为例,它的成员函数applyDraw的实现如下所示:
class DrawRectOp : public DrawStrokableOp {
public:
......
virtual status_t applyDraw(OpenGLRenderer& renderer, Rect& dirty) {
return renderer.drawRect(mLocalBounds.left, mLocalBounds.top,
mLocalBounds.right, mLocalBounds.bottom, getPaint(renderer));
}
......
};这个函数定义在文件frameworks/base/libs/hwui/DisplayListOp.h中。
DrawRectOp类的成员函数applyDraw调用了参数renderer描述的一个OpenGLRenderer对象的成员函数drawRect来渲染当前正在处理的一个DrawRectOp。参数renderer描述的一个OpenGLRenderer对象的实际类型为LayerRenderer,不过LayerRenderer类的成员函数drawRect是从父类OpenGLRenderer继承下来的。因此,当前正在处理的一个DrawRectOp最终是通过OpenGLRenderer类的成员函数drawRect转化Open GL绘制命令进行执行的。这一点我们就留给读者自己去分析了。
还有一种特殊的DrawOp,即DrawRenderNodeOp,当它们的成员函数applyDraw被调用时,它所做的工作实际上递归地将它的子Render Node或者Projected Node的Display List包含的DrawOp转化为Open GL命令来执行,它的实现如下所示:
class DrawRenderNodeOp : public DrawBoundedOp {
......
virtual void replay(ReplayStateStruct& replayStruct, int saveCount, int level,
bool useQuickReject) {
if (mRenderNode->isRenderable() && !mSkipInOrderDraw) {
mRenderNode->replay(replayStruct, level + 1);
}
}
......
};这个函数定义在文件frameworks/base/libs/hwui/DisplayListOp.h中。
这一点与前面我们分析的DrawRenderNodeOp类的成员函数applyDraw的逻辑是类似的,因此我们就不再详述。
接下来我们再来看MergingDrawBatch类的成员函数replay的实现,如下所示:
class MergingDrawBatch : public DrawBatch {
public:
......
virtual status_t replay(OpenGLRenderer& renderer, Rect& dirty, int index) {
......
DrawOp* op = mOps[0].op;
......
status_t status = op->multiDraw(renderer, dirty, mOps, mBounds);
......
return status;
}
......
};这个函数定义在文件frameworks/base/libs/hwui/DeferredDisplayList.cpp中。
MergingDrawBatch类的成员函数replay只调用了保存在成员变量mOps描述的一个Vector中的第一个DrawOp的成员函数multiDraw,但是会将其余的DrawOp作为参数传递给它。
以一个具体的DrawPatchOp为例,它的成员函数multiDraw的实现如下所示:
class DrawPatchOp : public DrawBoundedOp {
public:
......
virtual status_t multiDraw(OpenGLRenderer& renderer, Rect& dirty,
const Vector<OpStatePair>& ops, const Rect& bounds) {
const DeferredDisplayState& firstState = *(ops[0].state);
renderer.restoreDisplayState(firstState, true); // restore all but the clip
// Batches will usually contain a small number of items so it's
// worth performing a first iteration to count the exact number
// of vertices we need in the new mesh
uint32_t totalVertices = 0;
for (unsigned int i = 0; i < ops.size(); i++) {
totalVertices += ((DrawPatchOp*) ops[i].op)->getMesh(renderer)->verticesCount;
}
const bool hasLayer = renderer.hasLayer();
uint32_t indexCount = 0;
TextureVertex vertices[totalVertices];
TextureVertex* vertex = &vertices[0];
// Create a mesh that contains the transformed vertices for all the
// 9-patch objects that are part of the batch. Note that onDefer()
// enforces ops drawn by this function to have a pure translate or
// identity matrix
for (unsigned int i = 0; i < ops.size(); i++) {
DrawPatchOp* patchOp = (DrawPatchOp*) ops[i].op;
const DeferredDisplayState* state = ops[i].state;
const Patch* opMesh = patchOp->getMesh(renderer);
uint32_t vertexCount = opMesh->verticesCount;
if (vertexCount == 0) continue;
// We use the bounds to know where to translate our vertices
// Using patchOp->state.mBounds wouldn't work because these
// bounds are clipped
const float tx = (int) floorf(state->mMatrix.getTranslateX() +
patchOp->mLocalBounds.left + 0.5f);
const float ty = (int) floorf(state->mMatrix.getTranslateY() +
patchOp->mLocalBounds.top + 0.5f);
// Copy & transform all the vertices for the current operation
TextureVertex* opVertices = opMesh->vertices;
for (uint32_t j = 0; j < vertexCount; j++, opVertices++) {
TextureVertex::set(vertex++,
opVertices->x + tx, opVertices->y + ty,
opVertices->u, opVertices->v);
}
// Dirty the current layer if possible. When the 9-patch does not
// contain empty quads we can take a shortcut and simply set the
// dirty rect to the object's bounds.
if (hasLayer) {
if (!opMesh->hasEmptyQuads) {
renderer.dirtyLayer(tx, ty,
tx + patchOp->mLocalBounds.getWidth(),
ty + patchOp->mLocalBounds.getHeight());
} else {
const size_t count = opMesh->quads.size();
for (size_t i = 0; i < count; i++) {
const Rect& quadBounds = opMesh->quads[i];
const float x = tx + quadBounds.left;
const float y = ty + quadBounds.top;
renderer.dirtyLayer(x, y,
x + quadBounds.getWidth(), y + quadBounds.getHeight());
}
}
}
indexCount += opMesh->indexCount;
}
return renderer.drawPatches(mBitmap, getAtlasEntry(),
&vertices[0], indexCount, getPaint(renderer));
}
......
}; 这个函数定义在文件frameworks/base/libs/hwui/DisplayListOp.h中。
在前面Android应用程序UI硬件加速渲染的预加载资源地图集服务(Asset Atlas Service)分析一文中,我们有分析过DrawPatchOp类的成员函数multiDraw的实现,它所做的事情就是首先计算出当前正在处理的DrawPatchOp和参数ops描述的DrawPatchOp的纹理坐标,并且将这些纹理坐标保存一个数组中传递给参数renderer描述的一个OpenGLRenderer对象的成员函数drawPatches,使得后者可以一次性地将N个DrawPatchOp合并在一起转化为Open GL绘制命令执行。这之所以是可行的,是因为这些DrawPatchOp是以纹理方式进行渲染的,它们使用的是同一个纹理。
这一步执行完成之后,回到OpenGLRenderer类的成员函数flushLayers中,这时候所有设置了Layer的Render Noder及其子Render Node和Projected Node的Display List均已渲染到了自己的FBO之上,接下来就要将这些FBO以及其它没有设置Layer的Render Node的Display List渲染在Frame Buffer上,也就是渲染在从Surface Flinger请求回来的一个图形缓冲区之上。由于前面每调用一个Layer对象的成员函数flush的时候,都会将一个FBO设置为当前的渲染对象,而接下来的渲染对象是Frame Buffer,因此就需要调用成员变量mRenderState描述的一个RenderState对象的成员函数bindFramebuffer将Frame Buffer设置为当前的渲染对象。前面提到,OpenGLRenderer类的成员函数getTargetFbo的返回值等于0,当我们将一个值为0的FBO设置为当前的渲染对象时,起到的效果实际上解除前面设置的值为非0的FBO作为当前的渲染对象,并且将当前的渲染对象还原回Frame Buffer的效果。
OpenGLRenderer类的成员函数flushLayers执行完成后,回到OpenGLRenderer类的成员函数drawRenderNode中,这时候可以渲染应用程序窗口的Root Render Node的Display List了。在渲染之前,同样是先调用OpenGLRenderer类的成员函数startFrame执行一些诸如清理颜色绘冲区等基本操作。注意,这里清理的是Frame Buffer的颜色绘冲区。这时候应用程序窗口的Root Render Node及其子Render Node和Projected Node的Display List经过重排和合并后的绘制命令就存放在本地变量deferredList描述的一个DeferredDisplayList的成员变量mBatches描述的一个Vector中,因此OpenGLRenderer类的成员函数drawRenderNode就可以调用前面已经分析过的DeferredDisplayList类的成员函数flush来执行它们。这里同样是需要注意,这些绘制命令的执行是作用在Frame Buffer之上的。
至此,应用程序窗口的Display List的渲染过程就分析完成了。整个过程比较复杂,但是总结来说,核心逻辑就是:
1. 将Main Thread维护的Display List同步到Render Thread维护的Display List去。这个同步过程由Render Thread执行,但是Main Thread会被阻塞住。
2. 如果能够完全地将Main Thread维护的Display List同步到Render Thread维护的Display List去,那么Main Thread就会被唤醒,此后Main Thread和Render Thread就互不干扰,各自操作各自内部维护的Display List;否则的话,Main Thread就会继续阻塞,直到Render Thread完成应用程序窗口当前帧的渲染为止。
第2步能够完全将Main Thread维护的Display List同步到Render Thread维护的Display List去很关键,它使得Main Thread和Render Thread可以并行执行,这意味着Render Thread在渲染应用程序窗口当前帧的Display List的同时,Main Thread可以去准备应用程序窗口下一帧的Display List,这样就使得应用程序窗口的UI更流畅。
Android 5.0引入Render Thread的作用除了可以获得上面描述的效果之外,还可以使得应用程序窗口动画显示更加流畅。在接下来的一篇文章中,我们就继续分析在硬件加速渲染的环境下,应用程序窗口的动画显示框架,敬请关注!更多的信息也可以关注老罗的新浪微博:http://weibo.com/shengyangluo。
京东创始人刘强东和其妻子章泽天最近成为了互联网舆论关注的焦点。有关他们“移民美国”和在美国购买豪宅的传言在互联网上广泛传播。然而,京东官方通过微博发言人发布的消息澄清了这些传言,称这些言论纯属虚假信息和蓄意捏造。
日前,据博主“@超能数码君老周”爆料,国内三大运营商中国移动、中国电信和中国联通预计将集体采购百万台规模的华为Mate60系列手机。
据报道,荷兰半导体设备公司ASML正看到美国对华遏制政策的负面影响。阿斯麦(ASML)CEO彼得·温宁克在一档电视节目中分享了他对中国大陆问题以及该公司面临的出口管制和保护主义的看法。彼得曾在多个场合表达了他对出口管制以及中荷经济关系的担忧。
今年早些时候,抖音悄然上线了一款名为“青桃”的 App,Slogan 为“看见你的热爱”,根据应用介绍可知,“青桃”是一个属于年轻人的兴趣知识视频平台,由抖音官方出品的中长视频关联版本,整体风格有些类似B站。
日前,威马汽车首席数据官梅松林转发了一份“世界各国地区拥车率排行榜”,同时,他发文表示:中国汽车普及率低于非洲国家尼日利亚,每百户家庭仅17户有车。意大利世界排名第一,每十户中九户有车。
近日,一项新的研究发现,维生素 C 和 E 等抗氧化剂会激活一种机制,刺激癌症肿瘤中新血管的生长,帮助它们生长和扩散。
据媒体援引消息人士报道,苹果公司正在测试使用3D打印技术来生产其智能手表的钢质底盘。消息传出后,3D系统一度大涨超10%,不过截至周三收盘,该股涨幅回落至2%以内。
9月2日,坐拥千万粉丝的网红主播“秀才”账号被封禁,在社交媒体平台上引发热议。平台相关负责人表示,“秀才”账号违反平台相关规定,已封禁。据知情人士透露,秀才近期被举报存在违法行为,这可能是他被封禁的部分原因。据悉,“秀才”年龄39岁,是安徽省亳州市蒙城县人,抖音网红,粉丝数量超1200万。他曾被称为“中老年...
9月3日消息,亚马逊的一些股东,包括持有该公司股票的一家养老基金,日前对亚马逊、其创始人贝索斯和其董事会提起诉讼,指控他们在为 Project Kuiper 卫星星座项目购买发射服务时“违反了信义义务”。
据消息,为推广自家应用,苹果现推出了一个名为“Apps by Apple”的网站,展示了苹果为旗下产品(如 iPhone、iPad、Apple Watch、Mac 和 Apple TV)开发的各种应用程序。
特斯拉本周在美国大幅下调Model S和X售价,引发了该公司一些最坚定支持者的不满。知名特斯拉多头、未来基金(Future Fund)管理合伙人加里·布莱克发帖称,降价是一种“短期麻醉剂”,会让潜在客户等待进一步降价。
据外媒9月2日报道,荷兰半导体设备制造商阿斯麦称,尽管荷兰政府颁布的半导体设备出口管制新规9月正式生效,但该公司已获得在2023年底以前向中国运送受限制芯片制造机器的许可。
近日,根据美国证券交易委员会的文件显示,苹果卫星服务提供商 Globalstar 近期向马斯克旗下的 SpaceX 支付 6400 万美元(约 4.65 亿元人民币)。用于在 2023-2025 年期间,发射卫星,进一步扩展苹果 iPhone 系列的 SOS 卫星服务。
据报道,马斯克旗下社交平台𝕏(推特)日前调整了隐私政策,允许 𝕏 使用用户发布的信息来训练其人工智能(AI)模型。新的隐私政策将于 9 月 29 日生效。新政策规定,𝕏可能会使用所收集到的平台信息和公开可用的信息,来帮助训练 𝕏 的机器学习或人工智能模型。
9月2日,荣耀CEO赵明在采访中谈及华为手机回归时表示,替老同事们高兴,觉得手机行业,由于华为的回归,让竞争充满了更多的可能性和更多的魅力,对行业来说也是件好事。
《自然》30日发表的一篇论文报道了一个名为Swift的人工智能(AI)系统,该系统驾驶无人机的能力可在真实世界中一对一冠军赛里战胜人类对手。
近日,非营利组织纽约真菌学会(NYMS)发出警告,表示亚马逊为代表的电商平台上,充斥着各种AI生成的蘑菇觅食科普书籍,其中存在诸多错误。
社交媒体平台𝕏(原推特)新隐私政策提到:“在您同意的情况下,我们可能出于安全、安保和身份识别目的收集和使用您的生物识别信息。”
2023年德国柏林消费电子展上,各大企业都带来了最新的理念和产品,而高端化、本土化的中国产品正在不断吸引欧洲等国际市场的目光。
罗永浩日前在直播中吐槽苹果即将推出的 iPhone 新品,具体内容为:“以我对我‘子公司’的了解,我认为 iPhone 15 跟 iPhone 14 不会有什么区别的,除了序(列)号变了,这个‘不要脸’的东西,这个‘臭厨子’。