机器学习初学者教程
Common natural language processing tasks and techniques
For most natural language processing tasks, the text to be processed, must be broken down, examined, and the results stored or cross referenced with rules and data sets. These tasks, allows the programmer to derive the meaning or intent or only the frequency of terms and words in a text.
Pre-lecture quiz
Let's discover common techniques used in processing text. Combined with machine learning, these techniques help you to analyse large amounts of text efficiently. Before applying ML to these tasks, however, let's understand the problems encountered by an NLP specialist.
Tasks common to NLP
There are different ways to analyse a text you are working on. There are tasks you can perform and through these tasks you are able to gauge an understanding of the text and draw conclusions. You usually carry out these tasks in a sequence.
Tokenization
Probably the first thing most NLP algorithms have to do is to split the text into tokens, or words. While this sounds simple, having to account for punctuation and different languages' word and sentence delimiters can make it tricky. You might have to use various methods to determine demarcations.
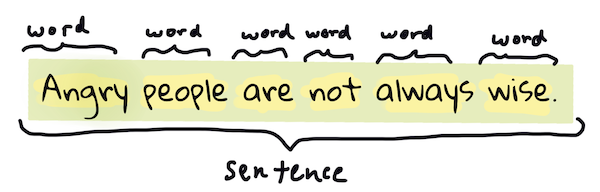
Tokenizing a sentence from Pride and Prejudice. Infographic by Jen Looper
Embeddings
Word embeddings are a way to convert your text data numerically. Embeddings are done in a way so that words with a similar meaning or words used together cluster together.

"I have the highest respect for your nerves, they are my old friends." - Word embeddings for a sentence in Pride and Prejudice. Infographic by Jen Looper
✅ Try this interesting tool to experiment with word embeddings. Clicking on one word shows clusters of similar words: 'toy' clusters with 'disney', 'lego', 'playstation', and 'console'.
Parsing & Part-of-speech Tagging
Every word that has been tokenized can be tagged as a part of speech - a noun, verb, or adjective. The sentence the quick red fox jumped over the lazy brown dog might be POS tagged as fox = noun, jumped = verb.

Parsing a sentence from Pride and Prejudice. Infographic by Jen Looper
Parsing is recognizing what words are related to each other in a sentence - for instance the quick red fox jumped is an adjective-noun-verb sequence that is separate from the lazy brown dog sequence.
Word and Phrase Frequencies
A useful procedure when analyzing a large body of text is to build a dictionary of every word or phrase of interest and how often it appears. The phrase the quick red fox jumped over the lazy brown dog has a word frequency of 2 for the.
Let's look at an example text where we count the frequency of words. Rudyard Kipling's poem The Winners contains the following verse:
What the moral? Who rides may read.
When the night is thick and the tracks are blind
A friend at a pinch is a friend, indeed,
But a fool to wait for the laggard behind.
Down to Gehenna or up to the Throne,
He travels the fastest who travels alone.As phrase frequencies can be case insensitive or case sensitive as required, the phrase a friend has a frequency of 2 and the has a frequency of 6, and travels is 2.
N-grams
A text can be split into sequences of words of a set length, a single word (unigram), two words (bigrams), three words (trigrams) or any number of words (n-grams).
For instance the quick red fox jumped over the lazy brown dog with a n-gram score of 2 produces the following n-grams:
- the quick
- quick red
- red fox
- fox jumped
- jumped over
- over the
- the lazy
- lazy brown
- brown dog
It might be easier to visualize it as a sliding box over the sentence. Here it is for n-grams of 3 words, the n-gram is in bold in each sentence:
- the quick red fox jumped over the lazy brown dog
- the quick red fox jumped over the lazy brown dog
- the quick red fox jumped over the lazy brown dog
- the quick red fox jumped over the lazy brown dog
- the quick red fox jumped over the lazy brown dog
- the quick red fox jumped over the lazy brown dog
- the quick red fox jumped over the lazy brown dog
- the quick red fox jumped over the lazy brown dog

N-gram value of 3: Infographic by Jen Looper
Noun phrase Extraction
In most sentences, there is a noun that is the subject, or object of the sentence. In English, it is often identifiable as having 'a' or 'an' or 'the' preceding it. Identifying the subject or object of a sentence by 'extracting the noun phrase' is a common task in NLP when attempting to understand the meaning of a sentence.
✅ In the sentence "I cannot fix on the hour, or the spot, or the look or the words, which laid the foundation. It is too long ago. I was in the middle before I knew that I had begun.", can you identify the noun phrases?
In the sentence the quick red fox jumped over the lazy brown dog there are 2 noun phrases: quick red fox and lazy brown dog.
Sentiment analysis
A sentence or text can be analysed for sentiment, or how positive or negative it is. Sentiment is measured in polarity and objectivity/subjectivity. Polarity is measured from -1.0 to 1.0 (negative to positive) and 0.0 to 1.0 (most objective to most subjective).
✅ Later you'll learn that there are different ways to determine sentiment using machine learning, but one way is to have a list of words and phrases that are categorized as positive or negative by a human expert and apply that model to text to calculate a polarity score. Can you see how this would work in some circumstances and less well in others?
Inflection
Inflection enables you to take a word and get the singular or plural of the word.
Lemmatization
A lemma is the root or headword for a set of words, for instance flew, flies, flying have a lemma of the verb fly.
There are also useful databases available for the NLP researcher, notably:
WordNet
WordNet is a database of words, synonyms, antonyms and many other details for every word in many different languages. It is incredibly useful when attempting to build translations, spell checkers, or language tools of any type.
NLP Libraries
Luckily, you don't have to build all of these techniques yourself, as there are excellent Python libraries available that make it much more accessible to developers who aren't specialized in natural language processing or machine learning. The next lessons include more examples of these, but here you will learn some useful examples to help you with the next task.
Exercise - using TextBlob library
Let's use a library called TextBlob as it contains helpful APIs for tackling these types of tasks. TextBlob "stands on the giant shoulders of NLTK and pattern, and plays nicely with both." It has a considerable amount of ML embedded in its API.
Note: A useful Quick Start guide is available for TextBlob that is recommended for experienced Python developers
When attempting to identify noun phrases, TextBlob offers several options of extractors to find noun phrases.
-
Take a look at
ConllExtractor.from textblob import TextBlob from textblob.np_extractors import ConllExtractor # import and create a Conll extractor to use later extractor = ConllExtractor() # later when you need a noun phrase extractor: user_input = input("> ") user_input_blob = TextBlob(user_input, np_extractor=extractor) # note non-default extractor specified np = user_input_blob.noun_phrasesWhat's going on here? ConllExtractor is "A noun phrase extractor that uses chunk parsing trained with the ConLL-2000 training corpus." ConLL-2000 refers to the 2000 Conference on Computational Natural Language Learning. Each year the conference hosted a workshop to tackle a thorny NLP problem, and in 2000 it was noun chunking. A model was trained on the Wall Street Journal, with "sections 15-18 as training data (211727 tokens) and section 20 as test data (47377 tokens)". You can look at the procedures used here and the results.
Challenge - improving your bot with NLP
In the previous lesson you built a very simple Q&A bot. Now, you'll make Marvin a bit more sympathetic by analyzing your input for sentiment and printing out a response to match the sentiment. You'll also need to identify a noun_phrase and ask about it.
Your steps when building a better conversational bot:
- Print instructions advising the user how to interact with the bot
- Start loop
- Accept user input
- If user has asked to exit, then exit
- Process user input and determine appropriate sentiment response
- If a noun phrase is detected in the sentiment, pluralize it and ask for more input on that topic
- Print response
- loop back to step 2
Here is the code snippet to determine sentiment using TextBlob. Note there are only four gradients of sentiment response (you could have more if you like):
if user_input_blob.polarity <= -0.5:
response = "Oh dear, that sounds bad. "
elif user_input_blob.polarity <= 0:
response = "Hmm, that's not great. "
elif user_input_blob.polarity <= 0.5:
response = "Well, that sounds positive. "
elif user_input_blob.polarity <= 1:
response = "Wow, that sounds great. "Here is some sample output to guide you (user input is on the lines with starting with >):
Hello, I am Marvin, the friendly robot.
You can end this conversation at any time by typing 'bye'
After typing each answer, press 'enter'
How are you today?
> I am ok
Well, that sounds positive. Can you tell me more?
> I went for a walk and saw a lovely cat
Well, that sounds positive. Can you tell me more about lovely cats?
> cats are the best. But I also have a cool dog
Wow, that sounds great. Can you tell me more about cool dogs?
> I have an old hounddog but he is sick
Hmm, that's not great. Can you tell me more about old hounddogs?
> bye
It was nice talking to you, goodbye!One possible solution to the task is here
✅ Knowledge Check
- Do you think the sympathetic responses would 'trick' someone into thinking that the bot actually understood them?
- Does identifying the noun phrase make the bot more 'believable'?
- Why would extracting a 'noun phrase' from a sentence a useful thing to do?
Implement the bot in the prior knowledge check and test it on a friend. Can it trick them? Can you make your bot more 'believable?'
🚀Challenge
Take a task in the prior knowledge check and try to implement it. Test the bot on a friend. Can it trick them? Can you make your bot more 'believable?'
Post-lecture quiz
Review & Self Study
In the next few lessons you will learn more about sentiment analysis. Research this interesting technique in articles such as these on KDNuggets