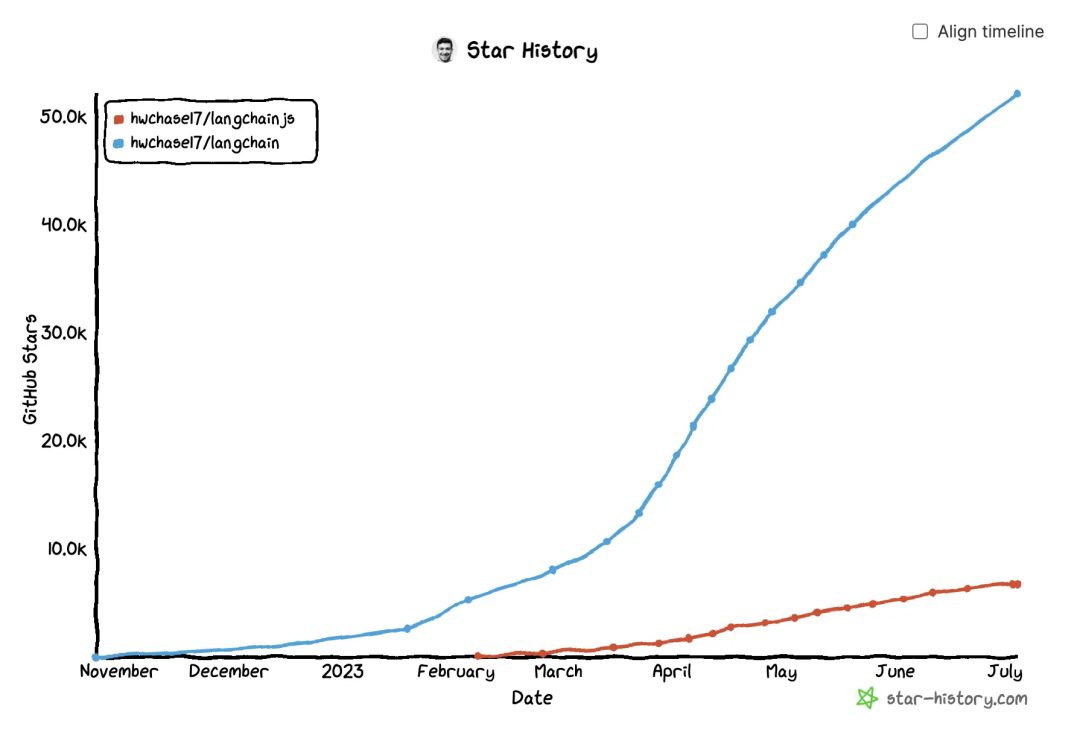
一图胜千言,LangChain已经成为当前 LLM 应用框架的事实标准,这篇文章就来对 LangChain 基本概念以及其具体使用场景做一个整理。
LangChain是一个基于大语言模型的应用开发框架,它主要通过两种方式规范和简化了使用LLM的方式:
LLM中;LLM通过决策与特定的环境交互,并由LLM协助决定下一步的操作。LangChain 的优点包括:
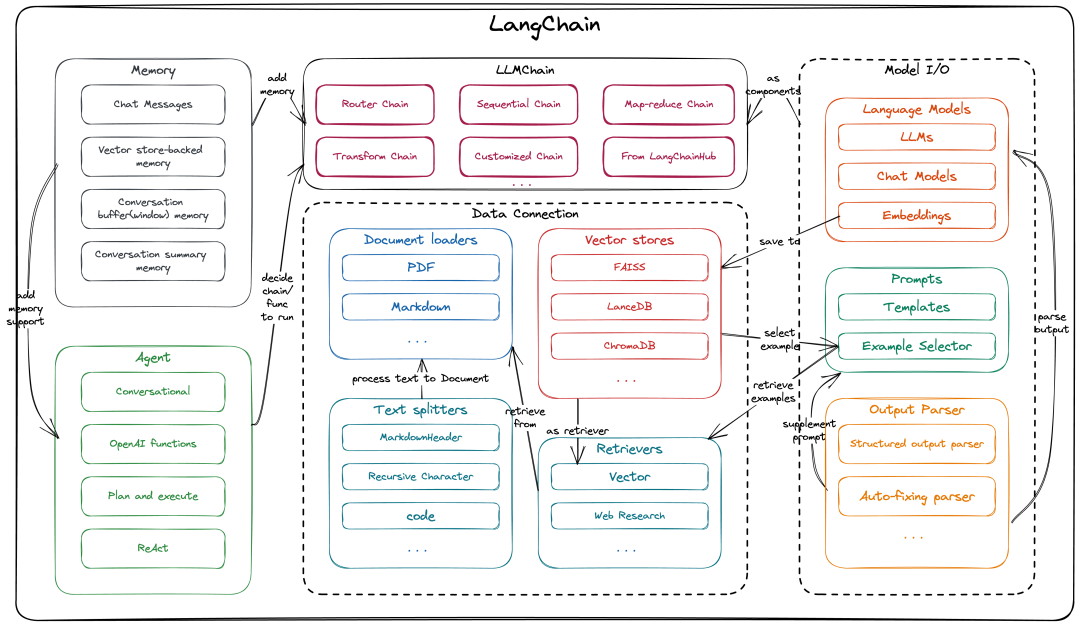
Chains的同时,支持自行继承 BaseChain 并实现相关逻辑以及各个阶段的callback handler等;Langchain团队迭代速度非常快,能快速使用最新的语言模型特性,该团队也有 langsmith, auto-evaluator 等其它优秀项目,并且开源社区也有相当多的支持。这是一张LangChain的组件与架构图(langchain python和langchain JS/TS的架构基本一致,本文中以langchain python来完成相关介绍),基本完整描述了LangChain的组件与抽象层(callback不在这张图中,在下方我们会另外介绍),以及它们之间的相关联系。
首先我们从最基本面的部分讲起,Model I/O 指的是和 LLM 直接进行交互的过程。
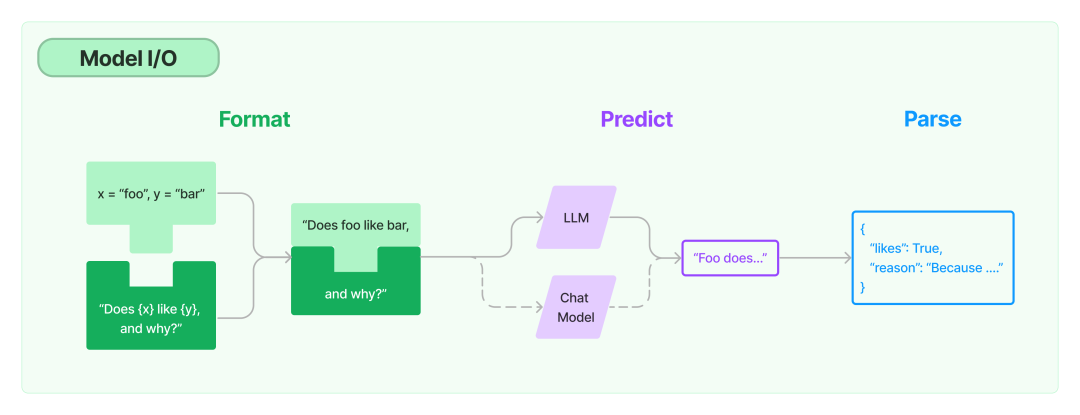
下面我们展开介绍一下
⚠️ 注:下面涉及的所有代码示例中的OPENAI_API_KEY和OPENAI_BASE_URL需要提前配置好,OPENAI_API_KEY指OpenAI/OpenAI 代理服务的API Key,OPENAI_BASE_URL指 OpenAI 代理服务的Base Url。
Language Model是真正与 LLM / ChatModel 进行交互的组件,它可以直接被当作普通的 openai client 来使用,在LangChain中,主要使用到的是LLM,Chat Model和Embedding三类 Language Model。
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-ada-001", openai_api_key=OPENAI_API_KEY, openai_api_base=OPENAI_BASE_URL)
llm("What day comes after Friday?")
# '\n\nSaturday.'LLM的变体,抽象了Chat这一场景下的使用模式,由“text in ➡️ text out”变成了“chat messages in ➡️ chat message out”,chat message是指**text + message type(System, Human, AI)**。from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage
chat = ChatOpenAI(model_name="gpt-4-0613", temperature=1, openai_api_key=OPENAI_API_KEY, openai_api_base=OPENAI_BASE_URL)
chat(
[
SystemMessage(content="You are an expert on large language models and can answer any questions related to large language models."),
HumanMessage(content="What’s the difference between Generic Language Models, Instruction Tuned Models and Dialog Tuned Models")
]
)
# AIMessage(content='Generic Language Models, Instruction-Tuned Models, and Dialog-Tuned Models are all various types of language models that have been trained according to different datasets and methodologies. They are used in different contexts according to their specific strengths. \n\n1. **Generic Language Models**: These models are trained on a broad range of internet text. They are typically not tuned to specific tasks and thus can be used across a wide variety of applications. GPT-3, used by OpenAI, is an example of a general language model.\n\n2. **Instruction-Tuned Models**: These are language models that are fine-tuned specifically to follow instructions given in a prompt. They are trained using a procedure called Reinforcement Learning from Human Feedback (RLHF), following an initial supervised fine-tuning which consists of human AI trainers providing conversations where they play both the user and an AI assistant. This model often includes comparison data - two or more model responses are ranked by quality.\n\n3. **Dialog-Tuned Models**: Like Instruction-Tuned Models, these models are also trained with reinforcement learning from human feedback, and especially shine in multi-turn conversations. However, these are specifically designed for dialog scenarios, resulting in an ability to maintain more coherent and context-aware conversations. \n\nIn essence, the difference among the three revolves around the breadth of their training and their specific use-cases. Generic Language Models are broad but may lack specificity; Instruction-Tuned Models are better at following specific instructions given in prompts; and Dialog-Tuned Models excel in carrying out more coherent and elongated dialogues.', additional_kwargs={}, example=False)另一方面,LangChain 也收录了大量的第三方 Chat Model
System - 告诉 AI 要做什么的背景信息上下文;
Human - 标识用户传入的消息类型;
AI - 标识 AI 返回的消息类型。以下是一个简单的Chat Model使用示例:
Embedding: Embedding将一段文字向量化为一个定长的向量,有了文本的向量化表示我们就可以做一些像语义搜索,聚类选择等来选择需要的文本片段,如下是将一个 embed 任意字符串的示例:
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY, openai_api_base=OPENAI_BASE_URL)
text_embedding = embeddings.embed_query("To embed text(it can have any length)")
print (f"Your embedding's length: {len(text_embedding)}")
print (f"Here's a sample: {text_embedding[:5]}...")
'''
Your embedding's length: 1536
Here's a sample: [-0.03194352, 0.009228715, 0.00807182, 0.0077545005, 0.008256923]...
'''Prompt指用户的一系列指令和输入,是决定Language Model输出内容的唯一输入,主要用于帮助模型理解上下文并生成相关和连贯的输出,如回答问题、拓写句子和总结问题。在LangChain中的相关组件主要有Prompt Template和Example selectors,以及后面会提到的辅助/补充Prompt的一些其它组件。
Prompt Template: 预定义的一系列指令和输入参数的prompt模版,支持更加灵活的输入,如支持**output instruction(输出格式指令), partial input(提前指定部分输入参数), examples(输入输出示例)**等;LangChain提供了大量方法来创建Prompt Template,有了这一层组件就可以在不同Language Model和不同Chain下大量复用Prompt Template了,Prompt Template中也会有下面将提到的Example selectors, Output Parser的参与。
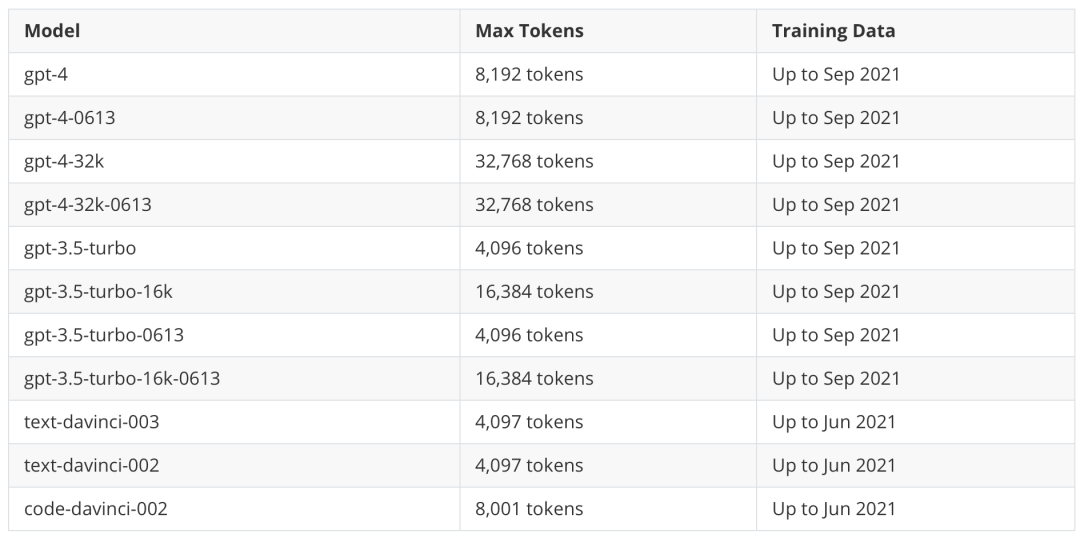
Example selectors: 在很多场景下,单纯的instruction + input的prompt不足以让LLM完成高质量的推理回答,这时候我们就还需要为prompt补充一些针对具体问题的示例,LangChain 将这一功能抽象为了Example selectors这一组件,我们可以基于关键字,相似度(通常使用MMR/cosine similarity/ngram来计算相似度, 在后面的向量数据库章节中会提到)。为了让最终的prompt不超过Language Model的 token 上限(各个模型的 token 上限见下表),LangChain还提供了LengthBasedExampleSelector,根据长度来限制 example 数量,对于较长的输入,它会选择包含较少示例的提示,而对于较短的输入,它会选择包含更多示例。
通常我们希望Language Model的输出是固定的格式,以支持我们解析其输出为结构化数据,LangChain将这一诉求所需的功能抽象成了Output Parser这一组件,并提供了一系列的预定义Output Parser,如最常用的Structured output parser, List parser,以及在LLM输出无法解析时发挥作用的Auto-fixing parser 和 Retry parser。
Output Parser需要和Prompt Template, Chain组合使用:
Prompt Template中通过指定partial_variables为Output Parser的 format,即可在prompt中补充让模型输出所需格式内容的指令;Chain中指定Output Parser,并使用Chain的predict_and_parse / apply_and_parse方法启动Chain,即可直接输出解析后的数据。以下是一个完整的组合Prompt Template, Output Parser 和 Chain的具体用例:
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=0.5, model_name="gpt-3.5-turbo-16k-0613", openai_api_key=OPENAI_API_KEY, openai_api_base=OPENAI_BASE_URL)
template = """
## Input
{text}
## Instruction
Please summarize the piece of text in the input part above.
Respond in a manner that a 5 year old would understand.
{format_instructions}
YOUR RESPONSE:
"""
# 创建一个Output Parser,包含两个输出字段,并指定类型和说明
output_parser = StructuredOutputParser.from_response_schemas(
[
ResponseSchema(name="keywords", type="list", description="keywords of the text"),
ResponseSchema(name="summary", type="string", description="summary of the text"),
]
)
# 创建Prompt Template,并将format_instructions通过partial_variables直接指定为Output Parser的format
prompt = PromptTemplate(
input_variables=["text"],
template=template,
partial_variables={"format_instructions": output_parser.get_format_instructions()},
)
# 创建Chain并绑定Prompt Template和Output Parser(它将自动使用Output Parser解析llm输出)
summarize_chain = LLMChain(llm=llm, verbose=True, prompt=prompt, output_parser=output_parser)
to_summarize_text = 'Abstract. Text-to-SQL aims at generating SQL queries for the given natural language questions and thus helping users to query databases. Prompt learning with large language models (LLMs) has emerged as a recent approach, which designs prompts to lead LLMs to understand the input question and generate the corresponding SQL. However, it faces challenges with strict SQL syntax requirements. Existing work prompts the LLMs with a list of demonstration examples (i.e. question-SQL pairs) to generate SQL, but the fixed prompts can hardly handle the scenario where the semantic gap between the retrieved demonstration and the input question is large.'
output = summarize_chain.predict(text=to_summarize_text)
import json
print (json.dumps(output, indent=4))输出如下:
{
"keywords": [
"Text-to-SQL",
"SQL queries",
"natural language questions",
"databases",
"prompt learning",
"large language models",
"LLMs",
"SQL syntax requirements",
"demonstration examples",
"semantic gap"
],
"summary": "Text-to-SQL is a method that helps users generate SQL queries for their questions about databases. One approach is to use large language models to understand the question and generate the SQL. However, this approach faces challenges with strict SQL syntax rules. Existing methods use examples to teach the language models, but they struggle when the examples are very different from the question."
}正如我在文章开头的LangChain 是什么一节中提到的,集成外部数据到 Language Model 中是 LangChain 提供的核心能力之一,也是市面上很多优秀的大语言模型应用成功的核心之一(Github Copilot Chat,网页聊天助手,论文总结助手,youtube 视频总结助手…),在LangChain中,Data connection这一层主要包含以下四个抽象组件:
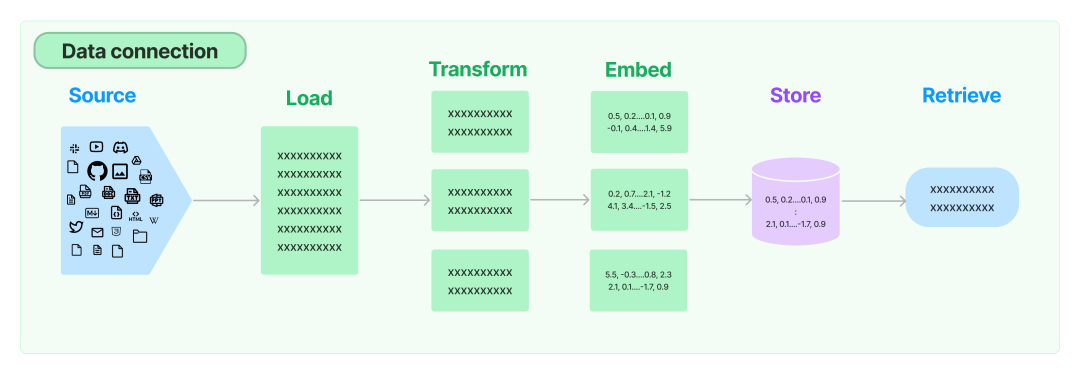
为了补全 LLM 的上下文信息,给予其足够的提示,我们需要从各类数据源获取各类数据,这也就是LangChain抽象的Document loaders这一组件的功能。
使用Document loaders可以将源中的数据加载为Document。Document由一段文本和相关元数据组成。例如,有用于加载简单.txt 文件的,用于加载相对结构化的 markdown 文件的,用于加载任何网页文本内容,甚至用于加载解析 YouTube 视频的脚本。
同时 LangChain 还收录了海量的第三方 Document loaders,以下是一个使用NotionDBLoader来加载notion database中的page为Document的示例:
from langchain.document_loaders import NotionDBLoader
from getpass import getpass
# getpass()指引用户输入密钥
NOTION_TOKEN = getpass()
DATABASE_ID = getpass()
loader = NotionDBLoader(
integration_token=NOTION_TOKEN,
database_id=DATABASE_ID,
request_timeout_sec=30, # optional, defaults to 10
)
# 请求详情见 https://developers.notion.com/reference/post-database-query
docs = loader.load()
docs[0].page_content[:100]当我们加载 Document 到内存后,我们通常还会希望将他们尽可能的结构化 / 分块,以进行更加灵活的操作。
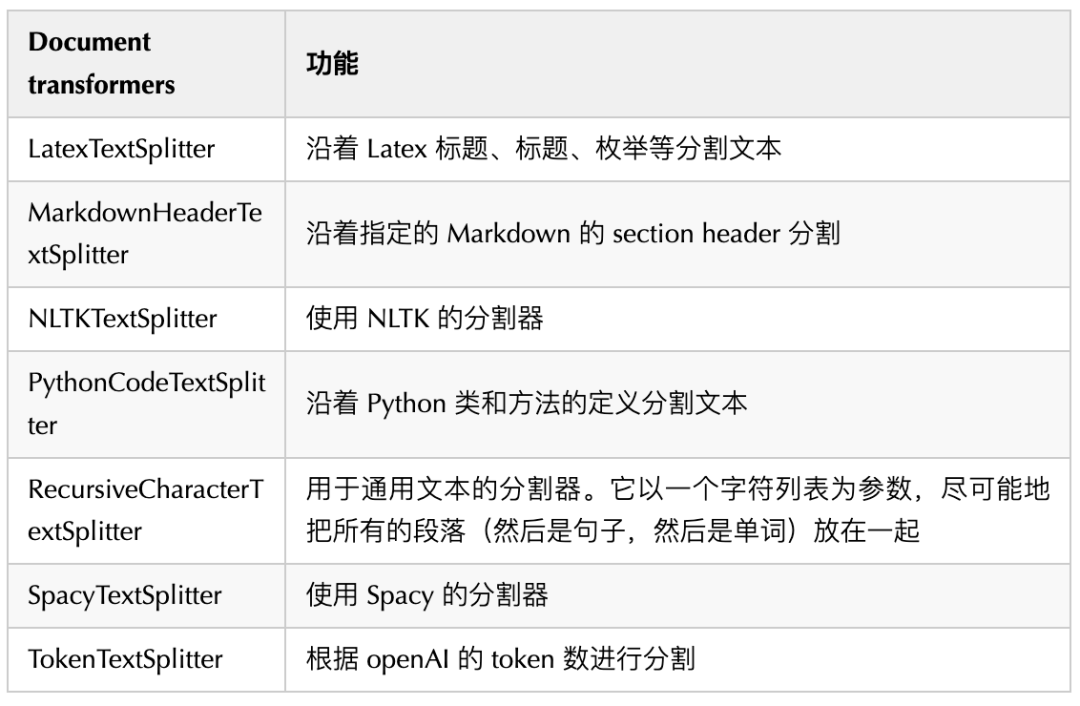
最简单的例子是,我们很多时候都需要将一个长文档拆分成更小的块,以便放入模型的上下文窗口中;LangChain 有许多内置的Document transformers(大部分都是Text Spliter),可以轻松地拆分、合并、筛选和以其他方式操作文档,一些常用的Document transformers如下:
同时 LangChain 也收录了很多第三方的Document transformers(如基于爬虫中常见的 beautiful soup, 基于 OpenAI 打 metadata tag 的等等)。
在前面的 Prompt 一节中我们提到了 Example selectors,那么我们要如何找到相关示例呢?通常这个答案就是向量数据库。
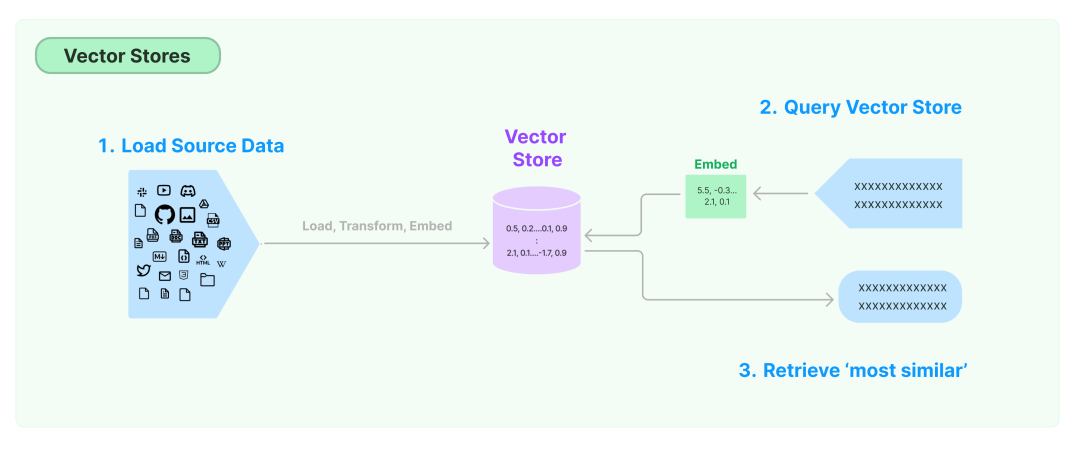
同时 LangChain 也收录了很多第三方的 Vector Stores,提供更加强大的向量搜索等功能。
Retrievers是 LangChain 提供的将Document与Language Model相结合的组件。
LangChain 中有许多不同类型的 Retrievers,但最广泛使用的就是 VectoreStoreRetriever,我们可以直接把它当做连接向量数据库和 Language Model 的中间层,并且 VectoreStoreRetriever 的使用也很简单,直接retriever = db.as_retriever()即可。
当然我们还有很多其它的 Retrievers 如 Web search Retrievers 等,LangChain 也收录了很多第三方的 Retrievers
以下就是一个使用向量数据库 + VectoreStoreRetriever + QA Chain 的 QA 应用示例:
from langchain.chat_models import ChatOpenAI
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 初始化LLM
llm = ChatOpenAI(temperature=0.5, model_name="gpt-3.5-turbo-16k-0613", openai_api_key=OPENAI_API_KEY, openai_api_base=OPENAI_PROXY_URL)
# 加载文档
loader = TextLoader('path/to/related/document')
doc = loader.load()
print (f"You have {len(doc)} document")
print (f"You have {len(doc[0].page_content)} characters in that document")
# 分割字符串
text_splitter = RecursiveCharacterTextSplitter(chunk_size=3000, chunk_overlap=400)
docs = text_splitter.split_documents(doc)
num_total_characters = sum([len(x.page_content) for x in docs])
print (f"Now you have {len(docs)} documents that have an average of {num_total_characters / len(docs):,.0f} characters (smaller pieces)")
# 初始化向量化模型
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY, openai_api_base=OPENAI_PROXY_URL)
# 向量化Document并存入向量数据库(绑定向量和对应Document元数据),这里我们选择本地最常用的FAISS数据库
# 注意: 这会向OpenAI产生请求并产生费用
doc_search = FAISS.from_documents(docs, embeddings)
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=doc_search.as_retriever(), verbose=True)
query = "Specific questions to be asked"
qa.run(query)执行后 verbose 输出日志如下:
You have 1 document You have 74663 characters in that document Now you have 29 documents that have an average of 2,930 characters (smaller pieces)
> Entering new chain...
Prompt after formatting:
System: Use the following pieces of context to answer the users question. If you don't know the answer, just say that you don't know, don't try to make up an answer. ---------------
Human: What does the author describe as good work?
The author describes working on things that aren't prestigious as a sign of good work. They believe that working on unprestigious types of work can lead to the discovery of something real and that it indicates having the right kind of motives. The author also mentions that working on things that last, such as paintings, is considered good work.
接下来就是 LangChain 中的主角——Chains 了,Chains 是 LangChain 中为连接多次与 Language Model 的交互过程而抽象的重要组件,它可以将多个组件组合在一起以创建一个单一的、连贯的任务,也可以嵌套多个 Chain 组合在一起,或者将 Chain 与其他组件组合来构建更复杂的 Chain。
除了单一 Chain 外,常用的几个 Chains 如下:
在一些场景下,我们需要根据输入 / 上下文决定使用哪一条 Chain,甚至哪一个 Prompt,Router Chain 就提供了诸如MultiPromptChain, LLMRouterChain等一系列用于决策的 Chain(这与后面我们会提到的 Agent 有类似的地方)。
Router Chain 由两部分组成:
顾名思义,顺序执行的串行 Chain,其中最简单的 SimpleSequentialChain 非常简单粗暴,SimpleSequentialChain 的每个子 Chain 都有一个单一的输入/输出,并且一个步骤的输出是下一步的输入。
而高阶一些的 SequentialChain 则允许多输入输出,并且我们可以通过添加后面会提到的 Memory 等来提高其推理表现。
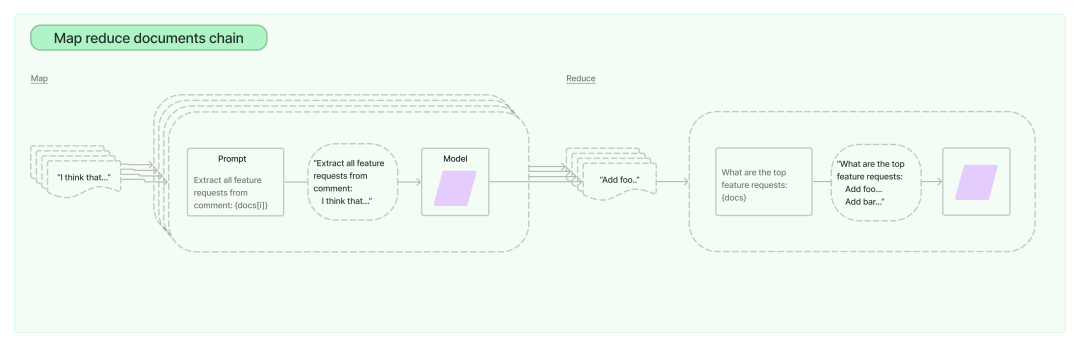
Map-reduce Chain 主要用于 summary 的场景,针对那些超长的文档,首先我们通过前面提到过的 TextSpliter 按一定规则分割文档为更小的 Chunks(通常使用 RecursiveCharacterTextSplitter,如果 Document 是结构化的可以考虑使用指定的 TextSpliter),然后对每个分割的部分执行”map-chain”,收集全部”map-chain”的输出后,再执行”reduce-chain”,获得最终的 summary 输出。
下面就是一个 Router Chain 中的MultiPromptChain的具体示例:
from langchain.chains.router import MultiPromptChain
from langchain.llms import OpenAI
from langchain.chains import ConversationChain
from langchain.chains.llm import LLMChain
from langchain.prompts import PromptTemplate
from langchain.chains.router.llm_router import LLMRouterChain, RouterOutputParser
from langchain.chains.router.multi_prompt_prompt import MULTI_PROMPT_ROUTER_TEMPLATE
# 定义要路由的prompts
physics_template = """You are a very smart physics professor. \
You are great at answering questions about physics in a concise and easy to understand manner. \
When you don't know the answer to a question you admit that you don't know.
Here is a question:
{input}"""
math_template = """You are a very good mathematician. You are great at answering math questions. \
You are so good because you are able to break down hard problems into their component parts, \
answer the component parts, and then put them together to answer the broader question.
Here is a question:
{input}"""
# 整理prompt和相关信息
prompt_infos = [
{
"name": "physics",
"description": "Good for answering questions about physics",
"prompt_template": physics_template,
},
{
"name": "math",
"description": "Good for answering math questions",
"prompt_template": math_template,
},
]
llm = OpenAI(temperature=0.5, openai_api_key=OPENAI_API_KEY, openai_api_base=OPENAI_PROXY_URL+"/v1")
destination_chains = {}
for p_info in prompt_infos:
# 以每个prompt为基础创建一个destination_chain(开启verbose)
name = p_info["name"]
prompt_template = p_info["prompt_template"]
prompt = PromptTemplate(template=prompt_template, input_variables=["input"])
chain = LLMChain(llm=llm, prompt=prompt)
destination_chains[name] = chain
# 创建一个缺省chain,如果没有其他chain满足路由条件,则使用该chain
default_chain = ConversationChain(llm=llm, output_key="text")
destinations = [f"{p['name']}: {p['description']}" for p in prompt_infos]
destinations_str = "\n".join(destinations)
# 根据prompt_infos中的映射关系创建router_prompt
router_template = MULTI_PROMPT_ROUTER_TEMPLATE.format(destinations=destinations_str)
router_prompt = PromptTemplate(
template=router_template,
input_variables=["input"],
output_parser=RouterOutputParser(),
)
# 创建router_chain(开启verbose)
router_chain = LLMRouterChain(llm_chain=LLMChain(llm=llm, prompt=router_prompt, verbose=True), verbose=True)
# 将router_chain和destination_chains以及default_chain组合成MultiPromptChain(开启verbose)
chain = MultiPromptChain(
router_chain=router_chain,
destination_chains=destination_chains,
default_chain=default_chain,
verbose=True,
)
# run
chain.run("What is black body radiation?")执行后 verbose 输出日志如下:
Entering new chain...Prompt after formatting: Given a raw text input to a language model select the model prompt best suited for the input. You will be given the names of the available prompts and a description of what the prompt is best suited for. You may also revise the original input if you think that revising it will ultimately lead to a better response from the language model.
<< FORMATTING >> Return a markdown code snippet with a JSON object formatted to look like:
{ "destination": string \ name of the prompt to use or "DEFAULT" "next_inputs": string \ a potentially modified version of the original input }REMEMBER: "destination" MUST be one of the candidate prompt names specified below OR it can be "DEFAULT" if the input is not well suited for any of the candidate prompts. REMEMBER: "next_inputs" can just be the original input if you don't think any modifications are needed.
<< CANDIDATE PROMPTS >> physics: Good for answering questions about physics math: Good for answering math questions
<< INPUT >> What is black body radiation?
<< OUTPUT >>
Finished chain.
physics: {'input': 'What is black body radiation?'}
> Entering new chain...
Prompt after formatting:
You are a very smart physics professor. You are great at answering questions about physics in a concise and easy to understand manner. When you don't know the answer to a question you admit that you don't know.
Here is a question: What is black body radiation?
> Finished chain.
Memory可以帮助Language Model补充历史信息的上下文,LangChain中的Memory是一个有点模糊的术语,它可以像记住你过去聊天过的信息一样简单,也可以结合向量数据库做更加复杂的历史信息检索,甚至维护相关实体及其关系的具体信息,这取决于具体的应用。
通常 Memory 用于较长的 Chain,能一定程度上提高模型的推理表现。
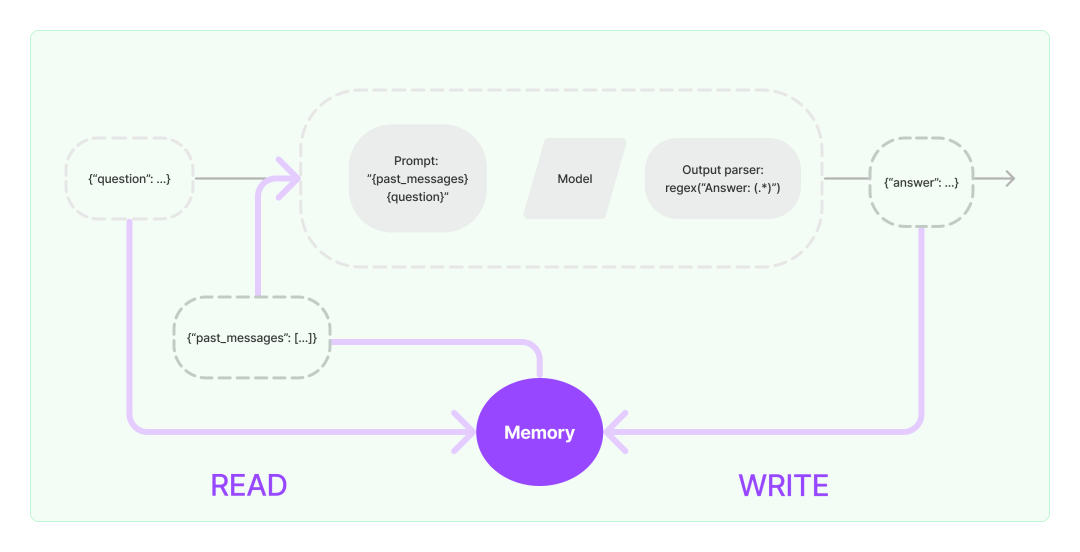
Chat Messages
最简单 Memory,将历史 Chat 记录作为补充信息放入 prompt 中.
Vector store-backed memory
基于向量数据库的 Memory,将 memory 存储在向量数据库中,并在每次调用时查询TopK 的最“重要”的文档。
这与大多数其他内存类的不同之处在于,它不显式跟踪交互的顺序,最多基于部分元数据筛选一下向量数据库的查询范围
Conversation buffer(window) memory保存一段时间内的历史 Chat 记录,它只使用最后 K 个记录(仅保持最近交互的滑动窗口),这样 buffer 也就不会变得太大,避免超过 token 上限。
Conversation summary memory
这种类型的 Memory 会随着 Chat 的进行创建对话的摘要,并将当前摘要存储在 Memory 中,用于后续对话的 history 提示;这种 memory 方案对长会话非常有用,但频繁的总结摘要会耗费大量的 token.
Conversation Summary Buffer Memory
结合了buffer memory和summary memory的策略,依旧会在内存中保留最后的一些 Chat 记录作为 buffer,并在 buffer 的总 token 数达到预置的上限后,对所有 Chat 记录总结摘要作为 SystemMessage 并清理其它历史 Messages;这种 memory 方案结合了buffer memory和summary memory的优点,既不会频繁地总结摘要消耗 token,也不会让 buffer 缺失过多信息。
下面是一个Conversation Summary Buffer Memory在ConversationChain中的使用示例,包含了切换会话时恢复现场 memory的方法以及自定义 summary prompt的方法:
from langchain.chains import ConversationChain
from langchain.memory import ConversationSummaryBufferMemory
from langchain.llms import OpenAI
from langchain.schema import SystemMessage, AIMessage, HumanMessage
from langchain.memory.prompt import SUMMARY_PROMPT
from langchain.prompts import PromptTemplate
llm = OpenAI(temperature=0.7, openai_api_key=OPENAI_API_KEY, openai_api_base=OPENAI_PROXY_URL+"/v1")
# ConversationSummaryBufferMemory默认使用langchain.memory.prompt.SUMMARY_PROMPT作为summary的PromptTemplate
# 如果对它summary的格式/内容有特殊要求,可以自定义PromptTemplate(实测默认的summary有些流水账)
prompt_template_str = """
## Instruction
Progressively summarize the lines of conversation provided, adding onto the previous summary returning a new concise and detailed summary.
Don't repeat the conversation directly in the summary, extract key information instead.
## EXAMPLE
Current summary:
The human asks what the AI thinks of artificial intelligence. The AI thinks artificial intelligence is a force for good.
New lines of conversation:
Human: Why do you think artificial intelligence is a force for good?
AI: Because artificial intelligence will help humans reach their full potential.
New summary:
The human inquires about the AI's opinion on artificial intelligence. The AI believes that it is a force for good as it can help humans reach their full potential.
## Current summary
{summary}
## New lines of conversation
{new_lines}
## New summary
"""
prompt = PromptTemplate(
input_variables=SUMMARY_PROMPT.input_variables, # input_variables为SUMMARY_PROMPT中的input_variables不变
template=prompt_template_str, # template替换为上面重新编写的prompt_template_str
)
memory = ConversationSummaryBufferMemory(llm=llm, prompt=prompt, max_token_limit=60)
# 添加历史memory,其中第一条SystemMessage为历史对话中Summary的内容,第二条HumanMessage和第三条AIMessage为历史对话中最后的对话内容
memory.chat_memory.add_message(SystemMessage(content="The human asks what the AI thinks of artificial intelligence. The AI thinks artificial intelligence is a force for good because it will help humans reach their full potential. The human then asks the difference between python and golang in short. The AI responds that python is a high-level interpreted language with an emphasis on readability and code readability, while golang is a statically typed compiled language with a focus on concurrency and performance. Python is typically used for general-purpose programming, while golang is often used for building distributed systems."))
memory.chat_memory.add_user_message("Then if I want to build a distributed system, which language should I choose?")
memory.chat_memory.add_ai_message("If you want to build a distributed system, I would recommend golang as it is a statically typed compiled language that is designed to facilitate concurrency and performance.")
# 调用memory.prune()确保chat_memory中的对话内容不超过max_token_limit
memory.prune()
conversation_with_summary = ConversationChain(
llm=llm,
# We set a very low max_token_limit for the purposes of testing.
memory=memory,
verbose=True,
)
# memory.prune()会在每次调用predict()后自动执行
conversation_with_summary.predict(input="Is there any well-known distributed system built with golang?")
conversation_with_summary.predict(input="Is there a substitutes for Kubernetes in python?")执行后 verbose 输出日志如下:
> Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation: System: The human asks the AI about its opinion on artificial intelligence and is told that it is a force for good that can help humans reach their full potential. The human then inquires about the differences between python and golang, with the AI explaining that python is a high-level interpreted language for general-purpose programming, while golang is a statically typed compiled language often used for building distributed systems. Human: Then if I want to build a distributed system, which language should I choose? AI: If you want to build a distributed system, I would recommend golang as it is a statically typed compiled language that is designed to facilitate concurrency and performance. Human: Is there any well-known distributed system built with golang? AI:
> Finished chain.
> Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation: System: The human asks the AI about its opinion on artificial intelligence and is told that it is a force for good that can help humans reach their full potential. The human then inquires about the differences between python and golang, with the AI explaining that python is a high-level interpreted language for general-purpose programming, while golang is a statically typed compiled language designed to facilitate concurrency and performance, thus better suited for distributed systems. The AI recommends golang for building distributed systems. Human: Is there any well-known distributed system built with golang? AI: Yes, there are several well-known distributed systems built with golang. These include Kubernetes, Docker, and Consul. Human: Is there a substitutes for Kubernetes in python?
AI:
> Finished chain.
'Yes, there are several substitutes for Kubernetes in python. These include Dask, Apache Mesos and Marathon, and Apache Aurora.’
在一些场景下,我们需要根据用户输入灵活地调用LLM和其它工具(LangChain将工具抽象为 Tools 这一组件),Agent 为这样的应用程序提供了相关的支持。
Agent可以访问一套工具,并根据用户输入确定要使用Chain或是Function,我们可以简单的理解为他可以动态的帮我们选择和调用 Chain 或者已有的工具。
常用的Agent类型如下:
这类 Agent 可以根据 Language Model 的输出决定是否使用指定的 Tool,以及使用什么 Tool(这里的 Tool 也可以是一个 Chain),以及时的为 Model I/O 的过程补充信息。
类似 Conversational Agent,但它能够让 Agent 更进一步地帮忙提取指定 Tool 的参数等,甚至使用多个 Tools。
抽象 Agent“决定做什么”的过程为“planning what to do”和“executing the sub tasks”(这种方法来自"Plan-and-Solve"这一篇论文),其中“planning what to do”这一步通常完全由 LLM 完成,而“executing the sub tasks”这一任务则通常由更多的 Tools 来完成。
结合对 LLM 输出的归因和执行,类似 OpenAI functions Agent,提供了一个更加明确的框架以及由论文支撑的方法。
这类 Agent 会基于 LLM 的输出,自行调用 Tools 以及 LLM 来进行额外的搜索和自查,以达到拓展和优化输出的目的。
LangChain 中的 Data Connection 将 LLM 与万物互联,给 LangChain 构建的应用带来了无限可能,而 Agent 又为应用开发中非常常见的”事件驱动“这一开发框架提供了偷懒的途径,将分支决策的工作交给 LLM,这又进一步简化了应用开发的工作;结合基于高度抽象的 Model I/O 及 Memory 等组件,LangChain 让开发者能够更快,更好更灵活地实现 LLM 助手、对话机器人等应用,极大地降低了 LLM 的使用门槛。
本文由微信公众号腾讯技术工程原创,哈喽比特收录。
文章来源:https://mp.weixin.qq.com/s/KrWM3cMywMvYUiawRZ94Gg
京东创始人刘强东和其妻子章泽天最近成为了互联网舆论关注的焦点。有关他们“移民美国”和在美国购买豪宅的传言在互联网上广泛传播。然而,京东官方通过微博发言人发布的消息澄清了这些传言,称这些言论纯属虚假信息和蓄意捏造。
日前,据博主“@超能数码君老周”爆料,国内三大运营商中国移动、中国电信和中国联通预计将集体采购百万台规模的华为Mate60系列手机。
据报道,荷兰半导体设备公司ASML正看到美国对华遏制政策的负面影响。阿斯麦(ASML)CEO彼得·温宁克在一档电视节目中分享了他对中国大陆问题以及该公司面临的出口管制和保护主义的看法。彼得曾在多个场合表达了他对出口管制以及中荷经济关系的担忧。
今年早些时候,抖音悄然上线了一款名为“青桃”的 App,Slogan 为“看见你的热爱”,根据应用介绍可知,“青桃”是一个属于年轻人的兴趣知识视频平台,由抖音官方出品的中长视频关联版本,整体风格有些类似B站。
日前,威马汽车首席数据官梅松林转发了一份“世界各国地区拥车率排行榜”,同时,他发文表示:中国汽车普及率低于非洲国家尼日利亚,每百户家庭仅17户有车。意大利世界排名第一,每十户中九户有车。
近日,一项新的研究发现,维生素 C 和 E 等抗氧化剂会激活一种机制,刺激癌症肿瘤中新血管的生长,帮助它们生长和扩散。
据媒体援引消息人士报道,苹果公司正在测试使用3D打印技术来生产其智能手表的钢质底盘。消息传出后,3D系统一度大涨超10%,不过截至周三收盘,该股涨幅回落至2%以内。
9月2日,坐拥千万粉丝的网红主播“秀才”账号被封禁,在社交媒体平台上引发热议。平台相关负责人表示,“秀才”账号违反平台相关规定,已封禁。据知情人士透露,秀才近期被举报存在违法行为,这可能是他被封禁的部分原因。据悉,“秀才”年龄39岁,是安徽省亳州市蒙城县人,抖音网红,粉丝数量超1200万。他曾被称为“中老年...
9月3日消息,亚马逊的一些股东,包括持有该公司股票的一家养老基金,日前对亚马逊、其创始人贝索斯和其董事会提起诉讼,指控他们在为 Project Kuiper 卫星星座项目购买发射服务时“违反了信义义务”。
据消息,为推广自家应用,苹果现推出了一个名为“Apps by Apple”的网站,展示了苹果为旗下产品(如 iPhone、iPad、Apple Watch、Mac 和 Apple TV)开发的各种应用程序。
特斯拉本周在美国大幅下调Model S和X售价,引发了该公司一些最坚定支持者的不满。知名特斯拉多头、未来基金(Future Fund)管理合伙人加里·布莱克发帖称,降价是一种“短期麻醉剂”,会让潜在客户等待进一步降价。
据外媒9月2日报道,荷兰半导体设备制造商阿斯麦称,尽管荷兰政府颁布的半导体设备出口管制新规9月正式生效,但该公司已获得在2023年底以前向中国运送受限制芯片制造机器的许可。
近日,根据美国证券交易委员会的文件显示,苹果卫星服务提供商 Globalstar 近期向马斯克旗下的 SpaceX 支付 6400 万美元(约 4.65 亿元人民币)。用于在 2023-2025 年期间,发射卫星,进一步扩展苹果 iPhone 系列的 SOS 卫星服务。
据报道,马斯克旗下社交平台𝕏(推特)日前调整了隐私政策,允许 𝕏 使用用户发布的信息来训练其人工智能(AI)模型。新的隐私政策将于 9 月 29 日生效。新政策规定,𝕏可能会使用所收集到的平台信息和公开可用的信息,来帮助训练 𝕏 的机器学习或人工智能模型。
9月2日,荣耀CEO赵明在采访中谈及华为手机回归时表示,替老同事们高兴,觉得手机行业,由于华为的回归,让竞争充满了更多的可能性和更多的魅力,对行业来说也是件好事。
《自然》30日发表的一篇论文报道了一个名为Swift的人工智能(AI)系统,该系统驾驶无人机的能力可在真实世界中一对一冠军赛里战胜人类对手。
近日,非营利组织纽约真菌学会(NYMS)发出警告,表示亚马逊为代表的电商平台上,充斥着各种AI生成的蘑菇觅食科普书籍,其中存在诸多错误。
社交媒体平台𝕏(原推特)新隐私政策提到:“在您同意的情况下,我们可能出于安全、安保和身份识别目的收集和使用您的生物识别信息。”
2023年德国柏林消费电子展上,各大企业都带来了最新的理念和产品,而高端化、本土化的中国产品正在不断吸引欧洲等国际市场的目光。
罗永浩日前在直播中吐槽苹果即将推出的 iPhone 新品,具体内容为:“以我对我‘子公司’的了解,我认为 iPhone 15 跟 iPhone 14 不会有什么区别的,除了序(列)号变了,这个‘不要脸’的东西,这个‘臭厨子’。