以太坊设计与实现
+++ title = "以太坊PoW共识算法Ethash" menuTitle = "Ethash基础" date = 2019-08-07T21:42:53+08:00 weight= 20302 +++
区块链鼻祖比特币,是PoW共识,已经稳定运行10年。但在2011年开始,因为比特币有利可图,市场经济下出现了专业矿机专门针对哈希算法、散热、耗能进行优化,这脱离了比特币网络节点运行在成千上万的普通计算机中并公平参与挖矿的初衷。这将造成节点中心化,面临51%攻击风险。因此,以太坊需要预防和改进PoW。
因此在以太坊设计共识算法时,期望达到两个目的:
- 抗ASIC^ASIC性:为算法创建专用硬件的优势应尽可能小,理想情况是即使开发出专有的集成电路,加速能力也足够小。以便普通计算机上的用户仍然可以获得微不足道的利润。
- 轻客户端可验证性: 一个区块应能被轻客户端快速有效校验。
在以太坊早期起草的共识算法是 Dagger-Hashimoto[^Hashimoto], 但被证明 Dagger很容易受到 Sergio Lerner 共享内存硬件加速的影响。 所以最终抛弃了 Dagger-Hashimoto,改变研究方向。 在对 Dagger-Hashimoto 进行大量修改,终于形成了明显不同于 Dagger-Hashimoto 的新算法:Ethash[^Ethash]。 Ethash 是 Ethereum 1.0 计划的 PoW 共识算法,在 Ethereum 2.0 将推进 PoS 共识。
下图是在挖矿时寻找 Nonce 时, Ethash 算法流程。 上半部分是前期的预备工作,根据区块高度计算出区块所在窗口期(一个窗口期固定3万个区块)。 一个窗口期内种子哈希、缓存和数据集都是固定不变的。 因此可按窗口期缓存数据,大多时候是读取数据,极少时候需要重新生成。
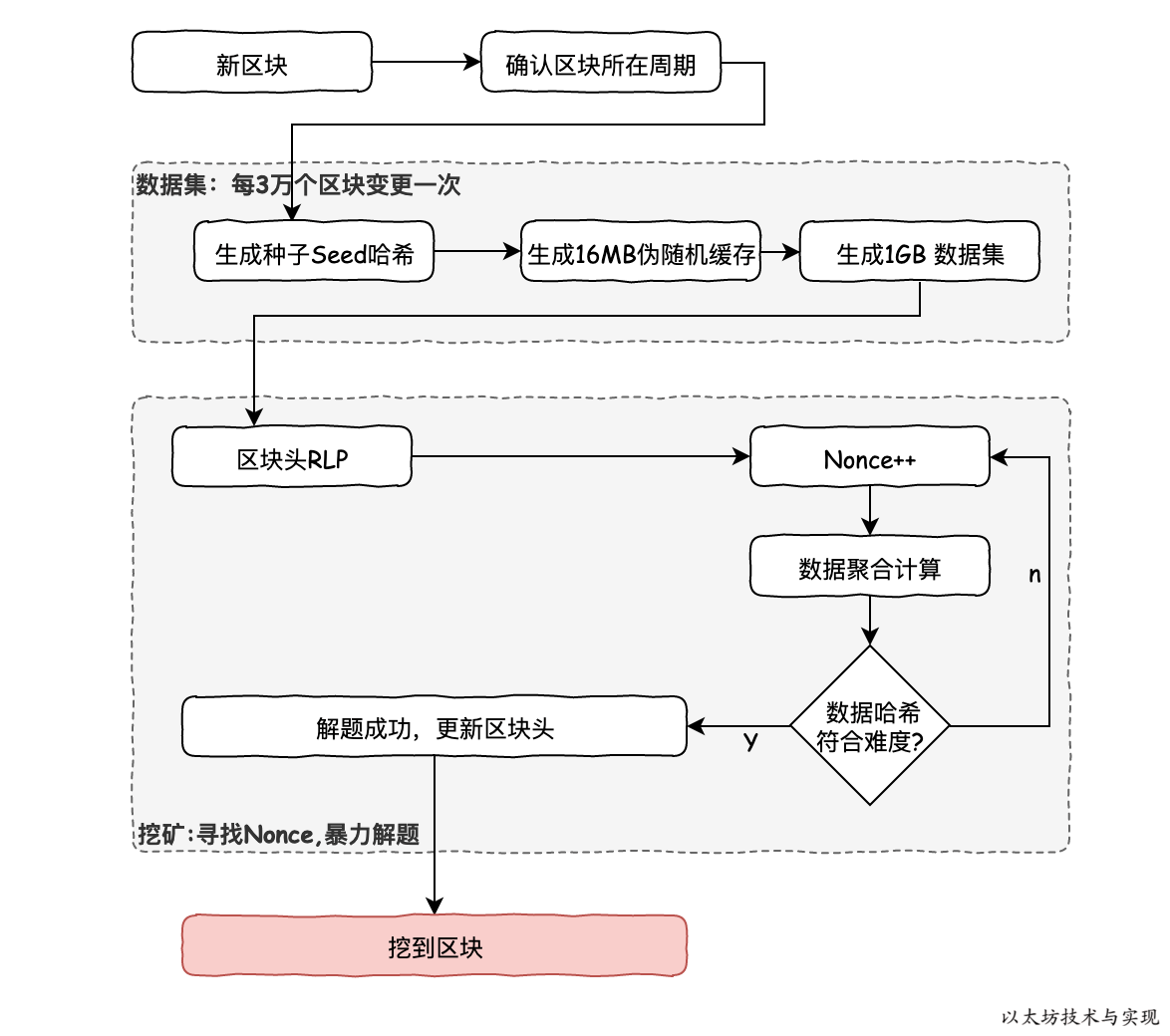
下半部分是寻找 Nonce,矿工在准备好一个区块数据,需要进行PoW工作量计算时,实际上是在暴力破解一道数学题。 已知的区块RLP数据和数据集,再结合需要求解的变量 Nonce,进行数据合成计算。 需要使得计算结果能够符合区块难度系数要求。如果不符合要求,则继续使用 Nonce++ 继续计算, 直到符合要求。
Ethash 算法基本内容
Ethash 是 Ethereum 1.0 计划的 PoW 算法。算法基本内容如下:
- 存在一个种子(seed),这个种子可以通过扫描区块头部直到该点为每个区块计算。
- 从种子中,可以计算出16 MB的伪随机缓存。轻客户端存储此缓存。
- 从缓存中,可以生成1 GB的DAG数据集,数据集中的每个项仅依赖于缓存中的少量项。完整客户端和矿工存储此数据集。数据集随时间线性增长。
种子是通过每个窗口期的种子进行哈希叠加而成,从种子中可以计算出一个16MB的伪随机填充缓存,用于辅助校验区块和生成数据集。 数据集是通过缓存生成的一个初始为 1GB 数据,数据集中的每个项(64 字节)仅依赖于缓存中的少量项。 小容量的缓存可方便各种客户端存储,而数据集仅仅存储在完整客户端和矿工节点。
这里选择16 MB 缓存是因为较小的高速缓存允许使用光评估(light-evaluation)方法,则太容易地用于 ASIC。 16 MB 缓存仍然需要非常高的缓存读取带宽,而较小的高速缓存可以更容易地被优化。 较大的缓存会导致算法太难而使得轻客户端无法进行区块校验。
选择 1GB 的数据集是为了要求内存级别超过大多数专用内存和缓存的大小,但普通计算机能够也还能使用它。 数据集选择 30000 个块更新一次,是因为间隔太大使得更容易创建被设计为非常不频繁地更新并且仅经常读取的内存。 而间隔太短,会增加进入壁垒,因为弱机器需要花费大量时间在更新数据集的固定成本上。
同时,缓存和数据集大小随时间线性增长,且为了降低循环行为时的偶然规律性风险,数据大小是一个不超过上限的素数。 每年约以0.73倍的速度增长,这个增长速率大致同摩尔定律持平。这仍有越过摩尔定律的风险,将导致挖矿需要非常大量的内存,使得普通的GPU不再能用于挖矿。
因为可通过使用缓存重新生成所需数据集的特定部分,少量内存进行PoW验证,因此你只需要存储缓存,而不需要存储数据集。
[^Hashimoto]: Dagger-Hashimoto 以太坊早起使用的算法,是两个算法的组合。https://github.com/ethereum/wiki/wiki/Dagger-Hashimoto
[^Ethash]: Ethash 是以太坊1.0 PoW共识算法,https://github.com/ethereum/wiki/wiki/Ethash