C++是一门古老的语言,但仍然在不间断更新中,不断引用新特性。但与此同时 C++又甩不掉巨大的历史包袱,并且 C++的设计初衷和理念造成了 C++异常复杂,还出现了很多不合理的“缺陷”。
本文主要有 3 个目的:
C++有一个很大的历史包袱,就是 C 语言。C 语言诞生时间很早,并且它是为了编写 OS 而诞生的,语法更加底层。有人说,C 并不是针对程序员友好的语言,而是针对编译期友好的语言。有些场景在 C 语言本身可能并没有什么不合理,但放到 C++当中会“爆炸”,或者说,会迅速变成一种“缺陷”,让人异常费解。
C++在演变过程中一直在吸收其他语言的优势,不断提供新的语法、工具来进行优化。但为了兼容性(不仅仅是语法的兼容,还有一些设计理念的兼容),还是会留下很多坑。
数组本身其实没有什么问题,这种语法也非常常用,主要是表示连续一组相同的数据构成的集合。但数组类型在待遇上却和其他类型(比如说结构体)非常不一样。
我们知道,结构体类型是可以很轻松的复制的,比如说:
struct St {
int m1;
double m2;
};
void demo() {
St st1;
St st2 = st1; // OK
St st3;
st1 = st3; // OK
}但数组却并不可以,比如:
int arr1[5];
int arr2[5] = arr1; // ERR明明这里 arr2 和 arr1 同为int[5]类型,但是并不支持复制。照理说,数组应当比结构体更加适合复制场景,因为需求是很明确的,就是元素按位复制。
由于数组不可以复制,导致了数组同样不支持传参,因此我们只能采用“首地址+长度”的方式来传递数组:
void f1(int *arr, size_t size) {}
void demo() {
int arr[5];
f1(arr, 5);
}而为了方便程序员进行这种方式的传参,C 又做了额外的 2 件事:
int[5]类型,传参时自动转换为int *类型)void f(int *arr);
void f(int arr[]);
void f(int arr[5]);
void f(int arr[100]);所以这里非常容易误导人的就在这个语法糖中,无论中括号里写多少,或者不写,这个值都是会被忽略的,要想知道数组的边界,你就必须要通过额外的参数来传递。
但通过参数传递这是一种软约束,你无法保证调用者传的就是数组元素个数,这里的危害详见后面“指针偏移”的章节。
之所以 C 的数组会出现这种奇怪现象,我猜测,作者考虑的是数组的实际使用场景,是经常会进行切段截取的,也就是说,一个数组类型并不总是完全整体使用,我们可能更多时候用的是其中的一段。举个简单的例子,如果数组是整体复制、传递的话,做数组排序递归的时候会不会很尴尬?首先,排序函数的参数难以书写,因为要指定数组个数,我们总不能针对于 1,2,3,4,5,6,...元素个数的数组都分别写一个排序函数吧?其次,如果取子数组就会复制出一个新数组的话,也就不能对原数组进行排序了。
所以综合考虑,干脆这里就不支持复制,强迫程序员使用指针+长度这种方式来操作数组,反而更加符合数组的实际使用场景。
当然了,在 C++中有了引用语法,我们还是可以把数组类型进行传递的,比如:
void f1(int (&arr)[5]); // 必须传int[5]类型
void demo() {
int arr1[5];
int arr2[8];
f1(arr1); // OK
f1(arr2); // ERR
}但绝大多数的场景似乎都不会这样去用。一些新兴语言(比如说 Go)就注意到了这一点,因此将其进行了区分。在 Go 语言中,区分了“数组”和“切片”的概念,数组就是长度固定的,整体来传递;而切片则类似于首地址+长度的方式传递(只不过没有单独用参数,而是用 len 函数来获取)
func f1(arr [5]int) {
}
func f2(arr []int) {
}上面例子里,f1 就必须传递长度是 5 的数组类型,而 f2 则可以传递任意长度的切片类型。
而 C++其实也注意到了这一点,但由于兼容问题,它只能通过 STL 提供容器的方式来解决,std::array就是定长数组,而std::vector就是变长数组,跟上述 Go 语言中的数组和切片的概念是基本类似的。这也是 C++中更加推荐使用 vector 而不是 C 风格数组的原因。
C/C++中的类型说明符其实设计得很不合理,除了最简单的变量定义:
int a; // 定义一个int类型的变量a
上面这个还是很清晰明了的,但稍微复杂一点的,就比较奇怪了:
int arr[5]; // 定义一个int[5]类型的变量arr
arr 明明是int[5]类型,但是这里的 int 和[5]却并没有写到一起,如果这个还不算很容易造成迷惑的话,那来看看下面的:
int *a1[5]; // 定义了一个数组
int (*a2)[5]; // 定义了一个指针a1 是int *[5]类型,表示 a1 是个数组,有 5 个元素,每个元素都是指针类型的。
a2 是int (*)[5]类型,是一个指针,指针指向了一个int[5]类型的数组。
这里离谱的就在这个int (*)[5]类型上,也就是说,“指向int[5]类型的指针”并不是int[5]*,而是int (*)[5],类型说明符是从里往外描述的,而不是从左往右。
这里的另一个问题就是,C/C++并没有把“定义变量”和“变量的类型”这两件事分开,而是用类型说明符来同时承担了。也就是说,“定义一个 int 类型变量”这件事中,int 这一个关键字不仅表示“int 类型”,还表示了“定义变量”这个意义。这件事放在定义变量这件事上可能还不算明显,但放到定义函数上就不一样了:
int f1();
上面这个例子中,int 和()共同表示了“定义函数”这个意义。也就是说,看到 int 这个关键字,并不一定是表示定义变量,还有可能是定义函数,定义函数时 int 表示了函数的返回值的类型。
正是由于 C/C++中,类型说明符具有多重含义,才造成一些复杂语法简直让人崩溃,比如说定义高阶函数:
// 输入一个函数,输出这个函数的导函数
double (*DC(double (*)(double)))(double);DC 是一个函数,它有一个参数,是double (*)(double)类型的函数指针,它的返回值是一个double (*)(double)类型的函数指针。但从直观性上来说,上面的写法完全毫无可读性,如果没有那一行注释,相信大家很难看得出这个语法到底是在做什么。
C++引入了返回值右置的语法,从一定程度上可以解决这个问题:
auto f1() -> int;
auto DC(auto (*)(double) -> double) -> auto (*)(double) -> double;但用 auto 作为占位符仍然还是有些突兀和晦涩的。
我们来看一看其他语言是如何弥补这个缺陷的,最简单的做法就是把“类型”和“动作”这两件事分开,用不同的关键字来表示。 Go 语言:
// 定义变量
var a1 int
var a2 []int
var a3 *int
var a4 []*int // 元素为指针的数组
var a5 *[]int // 数组的指针
// 定义函数
func f1() {
}
func f2() int {
return 0
}
// 高阶函数
func DC(f func(float64)float64) func(float64)float64 {
}Swift 语言:
// 定义变量
var a1: Int
var a2: [Int]
// 定义函数
func f1() {
}
func f2() -> Int {
return 0
}
// 高阶函数
func DC(f: (Double, Double)->Double) -> (Double, Double)->Double {
}JavaScript 语言:
// 定义变量
var a1 = 0
var a2 = [1, 2, 3]
// 定义函数
function f1() {}
function f2() {
return 0
}
// 高阶函数
function DC(f) {
return function(x) {
//...
}
}指针的偏移运算让指针操作有了较大的自由度,但同时也会引入越界问题:
int arr[5];
int *p1 = arr + 5;
*p1 = 10// 越界
int a = 0;
int *p2 = &a;
a[1] = 10; // 越界换句话说,指针的偏移是完全随意的,静态检测永远不会去判断当前指针的位置是否合法。这个与之前章节提到的数组传参的问题结合起来,会更加容易发生并且更加不容易发现:
void f(int *arr, size_t size) {}
void demo() {
int arr[5];
f(arr, 6); // 可能导致越界
}因为参数中的值和数组的实际长度并没有要求强一致。
在其他语言中,有的语言(例如 java、C#)直接取消了指针的相关语法,但由此就必须引入“值类型”和“引用类型”的概念。 例如在 java 中,存在“实”和“名”的概念:
public static void Demo() {
int[] arr = new int[10];
int[] arr2 = arr; // “名”的复制,浅复制
int[] arr3 = Arrays.copyOf(arr, arr.length); // 用库方法进行深复制
}本质上来说,这个“名”就是栈空间上的一个指针,而“实”则是堆空间中的实际数据。如果取消指针概念的话,就要强行区分哪些类型是“值类型”,会完全复制,哪些是“引用类型”,只会浅复制。
C#中的结构体和类的概念恰好如此,结构体是值类型,整体复制,而类是引用类型,要用库函数来复制。
而还有一些语言保留了指针的概念(例如 Go、Swift),但仅仅用于明确指向和引用的含义,并不提供指针偏移运算,来防止出现越界问题。例如 go 中:
func Demo() {
var a int
var p *int
p = &a // OK
r1 := *p // 直接解指针是OK的
r2 := *(p + 1) // ERR,指针不可以偏移
}swift 中虽然仍然支持指针,但非常弱化了它的概念,从语法本身就能看出,不到迫不得已并不推荐使用:
func f1(_ ptr: UnsafeMutablePointer<Int>) {
ptr.pointee += 1 // 给指针所指向的值加1
}
func demo() {
var a: Int = 5
f1(&a)
}OC 中的指针更加特殊和“奇葩”,首先,OC 完全保留了 C 中的指针用法,而额外扩展的“类”类型则不允许出现在栈中,也就是说,所有对象都强制放在堆中,栈上只保留指针对其引用。虽然 OC 中的指针仍然是 C 指针,但由于操作对象的“奇葩”语法,倒是并不需要太担心指针偏移的问题。
void demo() {
NSObject *obj = [[NSObject alloc] init];
// 例如调用obj的description方法
NSString *desc = [obj description];
// 指针仍可偏移,但几乎不会有人这样来写:
[(obj+1) description]; // 也会越界
}隐式类型转换在一些场景下会让程序更加简洁,降低代码编写难度。比如说下面这些场景:
double a = 5; // int->double
int b = a * a; // double->int
int c = '5' - '0'; // char->int但是有的时候隐式类型转化却会引发很奇怪的问题,比如说:
#define ARR_SIZE(arr) (sizeof(arr) / sizeof(arr[0]))
void f1() {
int arr[5];
size_t size = ARR_SIZE(arr); // OK
}
void f2(int arr[]) {
size_t size = ARR_SIZE(arr); // WRONG
}结合之前所说,函数参数中的数组其实是数组首元素指针的语法糖,所以f2中的arr其实是int *类型,这时候再对其进行sizeof运算,结果是指针的大小,而并非数组的大小。如果程序员不能意识到这里发生了int [N]->int *的隐式类型转换,那么就可能出错。 还有一些隐式类型转换也很离谱,比如说:
int a = 5;
int b = a > 2; // 可能原本想写a / 2,把/写成了>这里发生的隐式转换是 bool->int,同样可能不符合预期。关于布尔类型详见后面章节。 C 中的这些隐式转换可能影响并不算大,但拓展到 C++中就可能有爆炸性的影响,详见后面“隐式构造”和“多态转换”的相关章节。
C/C++的赋值语句自带返回值,这一定算得上一大缺陷,在 C 中赋值语句返回值,在 C++中赋值语句返回左值引用。
这件事造成的最大影响就在=和==这两个符号上,比如:
int a1, a2;
bool b = a1 = a2;这里原本想写b = a1 == a2,但是错把==写成了=,但编译是可以完全通过的,因为a1 = a2本身返回了 a1 的引用,再触发一次隐式类型转换,把 bool 转化为 int(这里详见后面非布尔类型的布尔意义章节)。
更有可能的是写在 if 表达式中:
if (a = 1) {
}可以看到,a = 1执行后 a 的值变为 1,返回的 a 的值就是 1,所以这里的if变成了恒为真。
C++为了兼容这一特性,又不得不要求自定义类型要定义赋值函数
class Test {
public:
Test &operator =(const Test &); // 拷贝赋值函数
Test &operator =(Test &&); // 移动赋值函数
Test &operator =(int a); // 其他的赋值函数
};这里赋值函数的返回值强制要求定义为当前类型的左值引用,一来会让人觉得有些无厘头,记不住这里的写法,二来在发生继承关系的时候非常容易忘记处理父类的赋值。
class Base {
public:
Base &operator =(const Base &);
};
class Ch : public Base {
public:
Ch &opeartor =(const Ch &ch) {
this->Base::operator =(ch);
// 或者写成 *static_cast<Base *>(this) = ch;
// ...
return *this;
}
};古老一些的 C 系扩展语言基本还是保留了赋值语句的返回值(例如 java、OC),但一些新兴语言(例如 Go、Swift)则是直接取消了赋值语句的返回值,比如说在 swift 中:
let a = 5
var b: Int
var c: Int
c = (b = a) // ERRb = a会返回Void,所以再赋值给 c 时会报错
在原始 C 当中,其实并没有“布尔”类型,所有表示是非都是用 int 来做的。所以,int 类型就赋予了布尔意义,0 表示 false,非 0 都表示 true,由此也诞生了很多“野路子”的编程技巧:
int *p;
if (!p) {} // 指针→bool
while (1) {} // int→bool
int n;
while (~scanf("%d", &n)) {} // int→bool所有表示判断逻辑的语法,都可以用非布尔类型的值传入,这样的写法其实是很反人类直觉的,更严重的问题就是与 true 常量比较的问题。
int judge = 2; // 用了int表示了判断逻辑
if (judge == true) {} // 但这里的条件其实是false,因为true会转为1,2 == 1是false正是由于非布尔类型具有了布尔意义,才会造成一些非常反直觉的事情,比如说:
true + true != true
!!2 == 1
(2 == true) == false基本上除了 C++和一些弱类型脚本语言(比如 js)以外,其他语言都取消了非布尔类型的布尔意义,要想转换为布尔值,一定要通过布尔运算才可以,例如在 Go 中:
func Demo() {
a := 1 // int类型
if (a) { // ERR,if表达式要求布尔类型
}
if (a != 0) { // OK,通过逻辑运算得到布尔类型
}
}这样其实更符合直觉,也可以一定程度上避免出现写成类似于if (a = 1)出现的问题。C++中正是由于“赋值语句有返回值”和“非布尔类型有布尔意义”同时生效,才会在这里出现问题。
关于 C/C++到底是强类型语言还是弱类型语言,业界一直争论不休。有人认为,变量的类型从定义后就不能改变,并且每个变量都有固定的类型,所以 C/C++应该是强类型语言。
但有人持相反意见,是因为这个类型,仅仅是“表面上”不可变,但其实是可变的,比如说看下面例程:
int a = 300;
uint8_t *p = reinterpret_cast<uint8_t *>(&a);
*p = 1; // 这里其实就是把a变成了uint8_t类型根源就在于,指针的解类型是可以改变的,原本int类型的变量,我们只要把它的首地址保存下来,然后按照另一种类型来解,那么就可以做到“改变 a 的类型”的目的。
这也就意味着,指针类型是不安全的,因为你不一定能保证现在解指针的类型和指针指向数据的真实类型是匹配的。
还有更野一点的操作,比如:
struct S1 {
short a, b;
};
struct S2 {
int a;
};
void demo() {
S2 s2;
S1 *p = reinterpret_cast<S1 *>(&s2);
p->a = 2;
p->b = 1;
std::cout << s2.a; // 猜猜这里会输出多少?
}这里的指针类型问题和前面章节提到的指针偏移问题,综合起来就是说 C/C++的指针操作的自由度过高,提升了语言的灵活度,同时也增加了其复杂度。
如果仅仅在 C 的角度上,后置自增/自减语法并没有带来太多的副作用,有时候在程序中作为一些小技巧反而可以让程序更加精简,比如说:
void AttrCnt() {
static int count = 0;
std::cout << count++ << std::endl;
}但这个特性继承到 C++后问题就会被放大,比如说下面的例子:
for (auto iter = ve.begin(); iter != ve.end(); iter++) {
}这段代码看似特别正常,但仔细想想,iter 作为一个对象类型,如果后置++,一定会发生复制。后置++原本的目的就是在表达式的位置先返回原值,表达式执行完后再进行自增。但如果放在类类型来说,就必须要临时保存一份原本的值。例如:
class Element {
public:
// 前置++
Element &operator ++() {
ele++;
return *this;
}
// 后置++
Element operator ++(int) {
// 为了最终返回原值,所以必需保存一份快照用于返回
Element tmp = *this;
ele++;
return tmp;
}
private:
int ele;
};这也从侧面解释了,为什么前置++要求返回引用,而后置++则是返回非引用,因为这里需要复制一份快照用于返回。
那么,写在 for 循环中的后置++就会平白无故发生一次复制,又因为返回值没有接收,再被析构。
C++保留的++和--的语义,也是因为它和+=1或-=1语义并不完全等价。我们可以用顺序迭代器来解释。对于顺序迭代器(比如说链表的迭代器),++表示取下一个节点,--表示取上一个节点。而+n或者-n则表示偏移了,这种语义更适合随机访问(所以说随机迭代器支持+=和-=,但顺序迭代器只支持++和--)。
其他语言的做法基本分两种,一种就是保留自增/自减语法,但不再提供返回值,也就不用区分前置和后置,例如 Go:
a := 3
a++ // OK
b := a++ // ERR,自增语句没有返回值另一种就是干脆删除自增/自减语法,只提供普通的操作赋值语句,例如 Swift:
var a = 3
a++ // ERR,没有这种语法
a += 1 // OK,只能用这种方式自增这里说的类型长度指的是相同类型在不同环境下长度不一致的情况,下面总结表格
| 类型 | 32 位环境长度 | 64 位环境长度 |
|---|---|---|
| int/unsigned | 4B | 4B |
| long/unsigned long | 4B | 8B |
| long long/ unsigned long long | 8B | 8B |
由于这里出现了 32 位和 64 位环境下长度不一致的情况,C 语言特意提供了stdint.h头文件(C++中在 cstddef 中引用),定义了定长类型,例如int64_t在 32 位环境下其实是long long,而在 64 位环境下其实是long。
但这里的问题点在于:
例如uint64_t在 32 位环境下对应的格式符是%llu,但是在 64 位环境下对应的格式符是%lu。有一种折中的解决办法是自定义一个宏:
#if(sizeof(void*) == 8)
#define u64 "%lu"
#else
#define u64 "%llu"
#endif
void demo() {
uint64_t a;
printf("a="u64, a);
}但这样会让字符串字面量从中间断开,非常不直观。
例如在 64 位环境下,long和long long都是 64 位长,但编译器会识别为不同类型,在一些类型推导的场景会出现和预期不一致的情况,例如:
template <typename T>
void func(T t) {}
template <>
void func<int64_t>(int64_t t) {}
void demo() {
long long a;
func(a); // 会匹配通用模板,而匹配不到特例
}上述例子表明,func<int64_t>和func<long long>是不同实例,尽管在 64 位环境下long和long long真的看不出什么区别,但是编译器就是会识别成不同类型。
格式化字符串算是非常经典的 C 的产物,不仅是 C++,非常多的语言都是支持这种格式符的,例如 java、Go、python 等等。
但 C++中的格式化字符串可以说完全就是 C 的那一套,根本没有任何扩展。换句话说,除了基本数据类型和 0 结尾的字符串以外,其他任何类型都没有用于匹配的格式符。
例如,对于结构体类型、数组、元组类型等等,都没法匹配到格式符:
struct Point {
double x, y;
};
void Demo() {
// 打印Point
Point p {1, 2.5};
printf("(%lf,%lf)", p.x, p.y); // 无法直接打印p
// 打印数组
int arr[] = {1, 2, 3};
for (int i = 0; i < 3; i++) {
printf("%d, ", arr[i]); // 无法直接打印整个数组
}
// 打印元组
std::tuple tu(1, 2.5, "abc");
printf("(%d,%lf,%s)", std::get<0>(tu), std::get<1>(tu), std::get<2>(tu)); // 无法直接打印整个元组
}对于这些组合类型,我们就不得不手动去访问内部成员,或者用循环访问,非常不方便。
针对于字符串,还会有一个严重的潜在问题,比如:
std::string str = "abc";
str.push_back('\0');
str.append("abc");
char buf[32];
sprintf(buf, "str=%s", str.c_str());由于 str 中出现了'\0',如果用%s格式符来匹配的话,会在 0 的位置截断,也就是说buf其实只获取到了str中的第一个 abc,第二个 abc 就被丢失了。
而一些其他语言则是扩展了格式符功能用于解决上述问题,例如 OC 引入了%@格式符,用于调用对象的description方法来拼接字符串:
@interface Point2D : NSObject
@property double x;
@property double y;
- (NSString *)description;
@end
@implementation Point2D
- (NSString *)description {
return [[NSString alloc] initWithFormat:@"(%lf, %lf)", self.x, self.y];
}
@end
void Demo() {
Point2D *p = [[Point2D alloc] init];
[p setX:1];
[p setY:2.5];
NSLog(@"p=%@", p); // 会调用p的description方法来获取字符串,用于匹配%@
}而 Go 语言引入了更加方便的%v格式符,可以用来匹配任意类型,用它的默认方式打印。
type Test struct {
m1 int
m2 float32
}
func Demo() {
a1 := 5
a2 := 2.6
a3 := []int{1, 2, 3}
a4 := "123abc"
a5 := Test{2, 1.5}
fmt.Printf("a1=%v, a2=%v, a3=%v, a4=%v, a5=%v\n", a1, a2, a3, a4, a5)
}Python 则是用%s作为万能格式符来使用:
def Demo():
a1 = 5
a2 = 2.5
a3 = "abc123"
a4 = [1, 2, 3]
print("%s, %s, %s, %s"%(a1, a2, a3, a4)) #这里没有特殊格式要求时都可以用%s来匹配枚举类型原本是用于解决固定范围取值的类型表示,但由于在 C 语言中被定义为了整型类型的一种语法糖,导致枚举类型的使用上出现了一些问题。
枚举类型无法先声明后定义,例如下面这段代码会编译报错:
enum Season;
struct Data {
Season se; // ERR
};
enum Season {
Spring,
Summer,
Autumn,
Winter
};主要是因为enum类型是动态选择基础类型的,比如这里只有 4 个取值,那么可能会选取int16_t,而如果定义的取值范围比较大,或者中间出现大枚举值的成员,那么可能会选取int32_t或者int64_t。也就是说,枚举类型如果没定义完,编译期是不知道它的长度的,因此就没法前置声明。
C++中允许指定枚举的基础类型,制定后可以前置声明:
enum Season : int;
struct Data {
Season se; // OK
};
enum Season : int {
Spring,
Summer,
Autumn,
Winter
};但如果你是在调别人写的库的时候,人家的枚举没有指定基础类型的话,那你也没辙了,就是不能前置声明。
也就是说,我没有办法判断某个值是不是合法的枚举值:
enum Season {
Spring,
Summer,
Autumn,
Winter
};
void Demo() {
Season s = static_cast<Season>(5); // 不会报错
}enum Test {
Ele1 = 10,
Ele2,
Ele3 = 10
};
void Demo() {
bool judge = (Ele1 == Ele3); // true
}但因为 C++提供了enum class风格的枚举类型,解决了这两个问题,因此这里不再额外讨论。
宏这个东西,完全就是针对编译器友好的,编译器非常方便地在宏的指导下,替换源代码中的内容。但这个玩意对程序员(尤其是阅读代码的人)来说是极其不友好的,由于是预处理指令,因此任何的静态检测均无法生效。一个经典的例子就是:
#define MUL(x, y) x * y
void Demo() {
int a = MUL(1 + 2, 3 + 4); // 11
}因为宏就是简单粗暴地替换而已,并没有任何逻辑判断在里面。
宏因为它很“好用”,所以非常容易被滥用,下面列举了一些宏滥用的情况供参考:
#define DEFAULT_MEM \
public: \
int GetX() {return x_;} \
private: \
int x_;
class Test {
DEFAULT_MEM;
public:
void method();
};这种用法相当于屏蔽了内部实现,对阅读者非常不友好,与此同时加不加 DEFAULT_MEM 是一种软约束,实际开发时极容易出错。
再比如这种的:
#define SINGLE_INST(class_name) \
public: \
static class_name &GetInstance() { \
static class_name instance; \
return instance; \
} \
class_name(const class_name&) = delete; \
class_name &operator =(const class_name &) = delete; \
private: \
class_name();
class Test {
SINGLE_INST(Test)
};这位同学,我理解你是想封装一下单例的实现,但咱是不是可以考虑一下更好的方式?(比如用模板)
#define strcpy_s(dst, dst_buf_size, src) strcpy(dst, src)
这位同学,咱要是真想写一个安全版本的函数,咱就好好去判断 dst_buf_size 如何?
#define COPY_IF_EXSITS(dst, src, field) \
do { \
if (src.has_##field()) { \
dst.set_##field(dst.field()); \
} \
} while (false)
void Demo() {
Pb1 pb1;
Pb2 pb2;
COPY_IF_EXSITS(pb2, pb1, f1);
COPY_IF_EXSITS(pb2, pb1, f2);
}这种用宏来做函数名的拼接看似方便,但最容易出的问题就是类型不一致,加入pb1和pb2中虽然都有f1这个字段,但类型不一样,那么这样用就可能造成类型转换。试想pb1.f1是uint64_t类型,而pb2.f1是uint32_t类型,这样做是不是有可能造成数据的截断呢?
#define IF(con) if (con) {
#define END_IF }
#define ELIF(con) } else if (con) {
#define ELSE } else {
void Demo() {
int a;
IF(a > 0)
Process1();
ELIF(a < -3)
Process2();
ELSE
Process3();
}这位同学你到底是写 python 写惯了不适应 C 语法呢,还是说你为了让代码扫描工具扫不出来你的圈复杂度才出此下策的呢~~
共合体的所有成员共用内存空间,也就是说它们的首地址相同。在很多人眼中,共合体仅仅在“多选一”的场景下才会使用,例如:
union QueryKey {
int id;
char name[16];
};
int Query(const QueryKey &key);上例中用于查找某个数据的 key,可以通过 id 查找,也可以通过 name,但只能二选一。
这种场景确实可以使用共合体来节省空间,但缺点在于,共合体的本质就是同一个数据的不同解类型,换句话说,程序是不知道当前的数据是什么类型的,共合体的成员访问完全可以用更换解指针类型的方式来处理,例如:
union Un {
int m1;
unsigned char m2;
};
void Demo() {
Un un;
un.m1 = 888;
std::cout << un.m2 << std::endl;
// 等价于
int n1 = 888;
std::cout << *reinterpret_cast<unsigned char *>(&n1) << std::endl;
}共合体只不过把有可能需要的解类型提前写出来罢了。所以说,共合体并不是用来“多选一”的,笔者认为这是大家曲解的用法。毕竟真正要做到“多选一”,你就得知道当前选的是哪一个,例如:
struct QueryKey {
union {
int id;
char name[16];
} key;
enum {
kCaseId,
kCaseName
} key_case;
};用过 google protobuf 的读者一定很熟悉上面的写法,这个就是 proto 中oneof语法的实现方式。
在 C++17 中提供了std::variant,正是为了解决“多选一”问题存在的,它其实并不是为了代替共合体,因为共合体原本就不是为了这种需求的,把共合体用做“多选一”实在是有点“屈才”了。
更加贴合共合体本意的用法,是我最早是在阅读处理网络报文的代码中看到的,例如某种协议的报文有如下规定(例子是我随便写的):
| 二进制位 | 意义 |
|---|---|
| 0~3 | 协议版本号 |
| 4~5 | 超时时间 |
| 6 | 协商次数 |
| 7 | 保留位,固定 为 0 |
| 8~15 | 业务数据 |
这里能看出来,整个报文有 2 字节,一般的处理时,我们可能只需要关注这个报文的这 2 个字节值是多少(比如说用十六进制表示),而在排错的时候,才会关注报文中每一位的含义,因此,“整体数据”和“内部数据”就成为了这段报文的两种获取方式,这种场景下非常适合用共合体:
union Pack {
uint16_t data; // 直接操作报文数据
struct {
unsigned version : 4;
unsigned timeout : 2;
unsigned retry_times : 1;
unsigned block : 1;
uint8_t bus_data;
} part; // 操作报文内部数据
};
void Demo() {
// 例如有一个从网络获取到的报文
Pack pack;
GetPackFromNetwork(pack);
// 打印一下报文的值
std::printf("%X", pack.data);
// 更改一下业务数据
pack.part.bus_data = 0xFF;
// 把报文内容扔到处理流中
DataFlow() << pack.data;
}因此,这里的需求就是“用两种方式来访问同一份数据”,才是完全符合共合体定义的用法。
共合体应该是 C 语言的特色了,其他任何高级语言都没有类似的语法,主要还是因为 C 语言更加面相底层,C++仅仅是继承了 C 的语法而已。
先来吐槽一件事,就是 C/C++中const这个关键字,这个名字起的非常非常不好!为什么这样说呢?const 是 constant 的缩写,翻译成中文就是“常量”,但其实在 C/C++中,const并不是表示“常量”的意思。
我们先来明确一件事,什么是“常量”,什么是“变量”?常量其实就是衡量,比如说1就是常量,它永远都是这个值。再比如'A'就是个常量,同样,它永远都是和它 ASCII 码对应的值。 “变量”其实是指存储在内存当中的数据,起了一个名字罢了。如果我们用汇编,则不存在“变量”的概念,而是直接编写内存地址:
mov ax, 05FAh
mov ds, ax
mov al, ds:[3Fh]但是这个05FA:3F地址太突兀了,也很难记,另一个缺点就是,内存地址如果固定了,进程加载时动态分配内存的操作空间会下降(尽管可以通过相对内存的方式,但程序员仍需要管理偏移地址),所以在略高级一点的语言中,都会让程序员有个更方便的工具来管理内存,最简单的方法就是给内存地址起个名字,然后编译器来负责翻译成相对地址。
int a; // 其实就是让编译器帮忙找4字节的连续内存,并且起了个名字叫a
所以“变量”其实指“内存变量”,它一定拥有一个内存地址,和可变不可变没啥关系。
因此,C 语言中const用于修饰的一定是“变量”,来控制这个变量不可变而已。用const修饰的变量,其实应当说是一种“只读变量”,这跟“常量”根本挨不上。
这就是笔者吐槽这个const关键字的原因,你叫个read_only之类的不是就没有歧义了么?
C#就引入了readonly关键字来表示“只读变量”,而const则更像是给常量取了个别名(可以类比为 C++中的宏定义,或者constexpr,后面章节会详细介绍constexpr):
const int pi = 3.14159; // 常量的别名
readonly int[] arr = new int[]{1, 2, 3}; // 只读变量C++由于保留了 C 当中的const关键字,但更希望表达其“不可变”的含义,因此着重在“左右值”的方向上进行了区分。左右值的概念来源于赋值表达式:
var = val; // 赋值表达式赋值表达式的左边表示即将改变的变量,右边表示从什么地方获取这个值。因此,很自然地,右值不会改变,而左值会改变。那么在这个定义下,“常量”自然是只能做右值,因为常量仅仅有“值”,并没有“存储”或者“地址”的概念。而对于变量而言,“只读变量”也只能做右值,原因很简单,因为它是“只读”的。
虽然常量和只读变量是不同的含义,但它们都是用来“读取值”的,也就是用来做右值的,所以,C++引入了“const 引用”的概念来统一这两点。所谓 const 引用包含了 2 个方面的含义:
换言之,const 引用可能是引用,也可能只是个普通变量,如何理解呢?请看例程:
void Demo() {
const int a = 5; // a是一个只读变量
const int &r1 = a; // r1是a的引用,所以r1是引用
const int &r2 = 8; // 8是一个常量,因此r2并不是引用,而是一个只读变量
}也就是说,当用一个 const 引用来接收一个变量的时候,这时的引用是真正的引用,其实在r1内部保存了a的地址,当我们操作r的时候,会通过解指针的语法来访问到a
const int a = 5;
const int &r1 = a;
std::cout << r1;
// 等价于
const int *p1 = &a; // 引用初始化其实是指针的语法糖
std::cout << *p1; // 使用引用其实是解指针的语法糖但与此同时,const 引用还可以接收常量,这时,由于常量根本不是变量,自然也不会有内存地址,也就不可能转换成上面那种指针的语法糖。那怎么办?这时,就只能去重新定义一个变量来保存这个常量的值了,所以这时的 const 引用,其实根本不是引用,就是一个普通的只读变量。
const int &r1 = 8;
// 等价于
const int c1 = 8; // r1其实就是个独立的变量,而并不是谁的引用const 引用的这种设计,更多考虑的是语义上的,而不是实现上的。如果我们理解了 const 引用,那么也就不难理解为什么会有“将亡值”和“隐式构造”的问题了,因为搭配 const 引用,可以实现语义上的统一,但代价就是同一语法可能会做不同的事,会令人有疑惑甚至对人有误导。
在后面“右值引用”和“因式构造”的章节会继续详细介绍它们和 const 引用的联动,以及可能出现的问题。
C++11 的右值引用语法的引入,其实也完全是针对于底层实现的,而不是针对于上层的语义友好。换句话说,右值引用是为了优化性能的,而并不是让程序变得更易读的。
右值引用跟 const 引用类似,仍然是同一语法不同意义,并且右值引用的定义强依赖“右值”的定义。根据上一节对“左右值”的定义,我们知道,左右值来源于赋值语句,常量只能做右值,而变量做右值时仅会读取,不会修改。按照这个定义来理解,“右值引用”就是对“右值”的引用了,而右值可能是常量,也可能是变量,那么右值引用自然也是分两种情况来不同处理:
我们先来看右值引用绑定常量的情况:
int &&r1 = 5; // 右值引用绑定常量
和 const 引用一样,常量没有地址,没有存储位置,只有值,因此,要把这个值保存下来的话,同样得按照“新定义变量”的形式,因此,当右值引用绑定常量时,相当于定义了一个普通变量:
int &&r1 = 5;
// 等价于
int v1 = 5; // r1就是个普通的int变量而已,并不是引用所以这时的右值引用并不是谁的引用,而是一个普普通通的变量。
我们再来看看右值引用绑定变量的情况: 这里的关键问题在于,什么样的变量适合用右值引用绑定? 如果对于普通的变量,C++不允许用右值引用来绑定,但这是为什么呢?
int a = 3;
int &&r = a; // ERR,为什么不允许右值引用绑定普通变量?我们按照上面对左右值的分析,当一个变量做右值时,该变量只读,不会被修改,那么,“引用”这个变量自然是想让引用成为这个变量的替身,而如果我们希望这里做的事情是“当通过这个引用来操作实体的时候,实体不能被改变”的话,使用 const 引用就已经可以达成目的了,没必要引入一个新的语法。
所以,右值引用并不是为了让引用的对象只能做右值(这其实是 const 引用做的事情),相反,右值引用本身是可以做左值的。这就是右值引用最迷惑人的地方,也是笔者认为“右值引用”这个名字取得迷惑人的地方。
右值引用到底是想解决什么问题呢?请看下面示例:
struct Test { // 随便写一个结构体,大家可以脑补这个里面有很多复杂的成员
int a, b;
};
Test GetAnObj() { // 一个函数,返回一个结构体类型
Test t {1, 2}; // 大家可以脑补这里面做了一些复杂的操作
return t; // 最终返回了这个对象
}
void Demo() {
Test t1 = GetAnObj();
}我们忽略编译器的优化问题,只分析 C++语言本身。在GetAnObj函数内部,t是一个局部变量,局部变量的生命周期是从创建到当前代码块结束,也就是说,当GetAnObj函数结束时,这个t一定会被释放掉。
既然这个局部变量会被释放掉,那么函数如何返回呢?这就涉及了“值赋值”的问题,假如t是一个整数,那么函数返回的时候容易理解,就是返回它的值。具体来说,就是把这个值推到寄存器中,在跳转会调用方代码的时候,再把寄存器中的值读出来:
int f1() {
int t = 5;
return t;
}翻译成汇编就是:
push rbp
mov rbp, rsp
mov DWORD PTR [rbp-4], 5 ; 这里[rbp-4]就是局部变量t
mov eax, DWORD PTR [rbp-4] ; 把t的值放到eax里,作为返回值
pop rbp
ret之所以能这样返回,主要就是 eax 放得下 t 的值。但如果 t 是结构体的话,一个 eax 寄存器自然是放不下了,那怎么返回?(这里汇编代码比较长,而且跟编译器的优化参数强相关,就不放代码了,有兴趣的读者可以自己汇编看结果。)简单来说,因为寄存器放不下整个数据,这个数据就只能放到内存中,作为一个临时区域,然后在寄存器里放一个临时区域的内存地址。等函数返回结束以后,再把这个临时区域释放掉。
那么我们再回来看这段代码:
struct Test {
int a, b;
};
Test GetAnObj() {
Test t {1, 2};
return t; // 首先开辟一片临时空间,把t复制过去,再把临时空间的地址写入寄存器
} // 代码块结束,局部变量t被释放
void Demo() {
Test t1 = GetAnObj(); // 读取寄存器中的地址,找到临时空间,再把临时空间的数据复制给t1
// 函数调用结束,临时空间释放
}那么整个过程发生了 2 次复制和 2 次释放,如果我们按照程序的实际行为来改写一下代码,那么其实应该是这样的:
struct Test {
int a, b;
};
void GetAnObj(Test *tmp) { // tmp要指向临时空间
Test t{1, 2};
*tmp = t; // 把t复制给临时空间
} // 代码块结束,局部变量t被释放
void Demo() {
Test *tmp = (Test *)malloc(sizeof(Test)); // 临时空间
GetAnObj(tmp); // 让函数处理临时空间的数据
Test t1 = *tmp; // 把临时空间的数据复制给这里的局部变量t1
free(tmp); // 释放临时空间
}如果我真的把代码写成这样,相信一定会被各位前辈骂死,质疑我为啥不直接用出参。的确,用出参是可以解决这种多次无意义复制的问题,所以 C++11 以前并没有要去从语法层面来解决,但这样做就会让代码不得不“面相底层实现”来编程。C++11 引入的右值引用,就是希望从“语法层面”解决这种问题。
试想,这片非常短命的临时空间,究竟是否有必要存在?既然这片空间是用来返回的,返回完就会被释放,那我何必还要单独再搞个变量来接收,如果这片临时空间可以持续使用的话,不就可以减少一次复制吗?于是,“右值引用”的概念被引入。
struct Test {
int a, b;
};
Test GetAnObj() {
Test t {1, 2};
return t; // t会复制给临时空间
}
void Demo() {
Test &&t1 = GetAnObj(); // 我设法引用这篇临时空间,并且让他不要立刻释放
// 临时空间被t1引用了,并不会立刻释放
} // 等代码块结束,t1被释放了,才让临时空间释放所以,右值引用的目的是为了延长临时变量的生命周期,如果我们把函数返回的临时空间中的对象视为“临时对象”的话,正常情况下,当函数调用结束以后,临时对象就会被释放,所以我们管这个短命的对象叫做“将亡对象”,简单粗暴理解为“马上就要挂了的对象”,它的使命就是让外部的t1复制一下,然后它就死了,所以这时候你对他做什么操作都是没意义的,他就是让人来复制的,自然就是个只读的值了,所以才被归结为“右值”。我们为了让它不要死那么快,而给它延长了生命周期,因此使用了右值引用。所以,右值引用是不是应该叫“续命引用”更加合适呢~
当用右值引用捕获一个将亡对象的时候,对象的生命周期从“将亡”变成了“与右值引用共存亡”,这就是右值引用的根本意义,这时的右值引用就是“将亡对象的引用”,又因为这时的将亡对象已经不再“将亡”了,那它既然不再“将亡”,我们再对它进行操作(改变成员的值)自然就是有意义的啦,所以,这里的右值引用其实就等价于一个普通的引用而已。既然就是个普通的引用,而且没用 const 修饰,自然,可以做左值咯。右值引用做左值的时候,其实就是它所指对象做左值而已。不过又因为普通引用并不会影响原本对象的生命周期,但右值引用会,因此,右值引用更像是一个普通的变量,但我们要知道,它本质上还是引用(底层是指针实现的)。
总结来说就是,右值引用绑定常量时相当于“给一个常量提供了生命周期”,这时的“右值引用”并不是谁的引用,而是相当于一个普通变量;而右值引用绑定将亡对象时,相当于“给将亡对象延长了生命周期”,这时的“右值引用”并不是“右值的引用”,而是“对需要续命的对象”的引用,生命周期变为了右值引用本身的生命周期(或者理解为“接管”了这个引用的对象,成为了一个普通的变量)。
需要知道的是,const 引用也是可以绑定将亡对象的,正如上文所说,既然将亡对象定义为了“右值”,也就是只读不可变的,那么自然就符合 const 引用的语义。
// 省略Test的定义,见上节
void Demo() {
const Test &t1 = GetAnObj(); // OK
}这样看来,const 引用同样可以让将亡对象延长生命周期,但其实这里的出发点并不同,const 引用更倾向于“引用一个不可变的量”,既然这里的将亡对象是一个“不可变的值”,那么,我就可以用 const 引用来保存“这个值”,或者这里的“值”也可以理解为这个对象的“快照”。所以,当一个 const 引用绑定一个将亡值时,const 引用相当于这个对象的“快照”,但背后还是间接地延长了它的生命周期,但只不过是不可变的。
在解释移动语义之前,我们先来看这样一个例子:
class Buffer final {
public:
Buffer(size_t size);
Buffer(const Buffer &ob);
~Buffer();
int &at(size_t index);
private:
size_t buf_size_;
int *buf_;
};
Buffer::Buffer(size_t size) : buf_size_(size), buf_(malloc(sizeof(int) * size)) {}
Buffer::Buffer(const Buffer &ob) :buf_size_(ob.buf_size_),
buf_(malloc(sizeof(int) * ob.buf_size_)) {
memcpy(buf_, ob.buf_, ob.buf_size_);
}
Buffer::~Buffer() {
if (buf_ != nullptr) {
free(buf_);
}
}
int &Buffer::at(size_t index) {
return buf_[index];
}
void ProcessBuf(Buffer buf) {
buf.at(2) = 100; // 对buf做一些操作
}
void Demo() {
ProcessBuf(Buffer{16}); // 创建一个16个int的buffer
}上面这段代码定义了一个非常简单的缓冲区处理类,ProcessBuf函数想做的事是传进来一个 buffer,然后对这个 buffer 做一些修改的操作,最后可能把这个 buffer 输出出去之类的(代码中没有体现,但是一般业务肯定会有)。
如果像上面这样写,会出现什么问题?不难发现在于ProcessBuf的参数,这里会发生复制。由于我们在Buffer类中定义了拷贝构造函数来实现深复制,那么任何传入的 buffer 都会在这里进行一次拷贝构造(深复制)。再观察Demo中调用,仅仅是传了一个临时对象而已。临时对象本身也是将亡对象,复制给buf后,就会被释放,也就是说,我们进行了一次无意义的深复制。 有人可能会说,那这里参数用引用能不能解决问题?比如这样:
void ProcessBuf(Buffer &buf) {
buf.at(2) = 100;
}
void Demo() {
ProcessBuf(Buffer{16}); // ERR,普通引用不可接收将亡对象
}所以这里需要我们注意的是,C++当中,并不只有在显式调用=的时候才会赋值,在函数传参的时候仍然由赋值语义(也就是实参赋值给形参)。所以上面就相当于:
Buffer &buf = Buffer{16}; // ERR
所以自然不合法。那,用 const 引用可以吗?由于 const 引用可以接收将亡对象,那自然可以用于传参,但ProcessBuf函数中却对对象进行了修改操作,所以 const 引用不能满足要求:
void ProcessBuf(const Buffer &buf) {
buf.at(2) = 100; // 但是这里会报错
}
void Demo() {
ProcessBuf(Buffer{16}); // 这里确实OK了
}正如上一节描述,const 引用倾向于表达“保存快照”的意义,因此,虽然这个对象仍然是放在内存中的,但 const 引用并不希望它发生改变(否则就不叫快照了),因此,这里最合适的,仍然是右值引用:
void ProcessBuf(Buffer &&buf) {
buf.at(2) = 100; // 右值引用完成绑定后,相当于普通引用,所以这里操作OK
}
void Demo() {
ProcessBuf(Buffer{16}); // 用右值引用绑定将亡对象,OK
}我们再来看下面的场景:
void Demo() {
Buffer buf1{16};
// 对buf进行一些操作
buf1.at(2) = 50;
// 再把buf传给ProcessBuf
ProcessBuf(buf1); // ERR,相当于Buffer &&buf= buf1;右值引用绑定非将亡对象
}因为右值引用是要来绑定将亡对象的,但这里的buf1是Demo函数的局部变量,并不是将亡的,所以右值引用不能接受。但如果我有这样的需求,就是说buf1我不打算用了,我想把它的控制权交给ProcessBuf函数中的buf,相当于,我主动让buf1提前“亡”,是否可以强制把它弄成将亡对象呢?STL 提供了std::move函数来完成这件事,“期望强制把一个对象变成将亡对象”:
void Demo() {
Buffer buf1{16};
// 对buf进行一些操作
buf1.at(2) = 50;
// 再把buf传给ProcessBuf
ProcessBuf(std::move(buf1)); // OK,强制让buf1将亡,那么右值引用就可以接收
} // 但如果读者尝试的话,在这里会出ERRORstd::move的本意是提前让一个对象“将亡”,然后把控制权“移交”给右值引用,所以才叫「move」,也就是“移动语义”。但很可惜,C++并不能真正让一个对象提前“亡”,所以这里的“移动”仅仅是“语义”上的,并不是实际的。如果我们看一下std::move的实现就知道了:
template <typename T>
constexpr std::remove_reference_t<T> &&move(T &&ref) noexcept {
return static_cast<std::remove_reference_t<T> &&>(ref);
}如果这里参数中的&&符号让你懵了的话,可以参考后面“引用折叠”的内容,如果对其他乱七八糟的语法还是没整明白的话,没关系,我来简化一下:
template <typename T>
T &&move(T &ref) {
return static_cast<T &&>(ref);
}哈?就这么简单?是的!真的就这么简单,这个std::move不是什么多高大上的处理,就是简单把普通引用给强制转换成了右值引用,就这么简单。
所以,我上线才说“C++并不能真正让一个对象提前亡”,这里的std::move就是跟编译器玩了一个文字游戏罢了。
所以,C++的移动语义仅仅是在语义上,在使用时必须要注意,一旦将一个对象 move 给了一个右值引用,那么不可以再操作原本的对象,但这种约束是一种软约束,操作了也并不会有报错,但是就可能会出现奇怪的问题。
有了右值引用和移动语义,C++还引入了移动构造和移动赋值,这里简单来解释一下:
void Demo() {
Buffer buf1{16};
Buffer buf2(std::move(buf1)); // 把buf1强制“亡”,但用它的“遗体”构造新的buf2
Buffer buf3{8};
buf3 = std::move(buf2); // 把buf2强制“亡”,把“遗体”转交个buf3,buf3原本的东西不要了
}为了解决用一个将亡对象来构造/赋值另一个对象的情况,引入了移动构造和移动赋值函数,既然是用一个将亡对象,那么参数自然是右值引用来接收了。
class Buffer final {
public:
Buffer(size_t size);
Buffer(const Buffer &ob);
Buffer(Buffer &&ob); // 移动构造函数
~Buffer();
Buffer &operator =(Buffer &&ob); // 移动赋值函数
int &at(size_t index);
private:
size_t buf_size_;
int *buf_;
};这里主要考虑的问题是,既然是用将亡对象来构造新对象,那么我们应当尽可能多得利用将亡对象的“遗体”,在将亡对象中有一个buf_指针,指向了一片堆空间,那这片堆空间就可以直接利用起来,而不用再复制一份了,因此,移动构造和移动赋值应该这样实现:
Buffer::Buffer(Buffer &&ob) : buf_size_(ob.buf_size_), // 基本类型数据,只能简单拷贝了
buf_(ob.buf_) { // 直接把ob中指向的堆空间接管过来
// 为了防止ob中的空间被重复释放,将其置空
ob.buf_ = nullptr;
}
Buffer &Buffer::operator =(Buffer &&ob) {
// 先把自己原来持有的空间释放掉
if (buf_ != nullptr) {
free(buf_);
}
// 然后继承ob的buf_
buf_ = ob.buf_;
// 为了防止ob中的空间被重复释放,将其置空
ob.buf_ = nullptr;
}细心的读者应该能发现,所谓的“移动构造/赋值”,其实就是一个“浅复制”而已。当出现移动语义的时候,我们想象中是“把旧对象里的东西 移动 到新对象中”,但其实没法做到这种移动,只能是“把旧对象引用的东西转为新对象来引用”,本质就是一次浅复制。
引用折叠指的是在模板参数以及 auto 类型推导时遇到多重引用时进行的映射关系,我们先从最简单的例子来说:
template <typename T>
void f(T &t) {
}
void Demo() {
int a = 3;
f<int>(a);
f<int &>(a);
f<int &&>(a);
}当T实例化为int时,函数变成了:
void f(int &t);但如果T实例化为int &和int &&时呢?难道是这样吗?
void f(int & &t);
void f(int && &t);我们发现,这种情况下编译并没有出错,T本身带引用时,再跟参数后面的引用符结合,也是可以正常通过编译的。这就是所谓的引用折叠,简单理解为“两个引用撞一起了,以谁为准”的问题。引用折叠满足下面规律:
左值引用短路右值引用
简单来说就是,除非是两个右值引用遇到一起,会推导出右值引用以外,其他情况都会推导出左值引用,所以是左值引用优先。
& + & -> &
& + && -> &
&& + & -> &
&& + && -> &&这种规律同样同样适用于auto &&,当auto &&遇到左值时会推导出左值引用,遇到右值时才会推导出右值引用:
auto &&r1 = 5; // 绑定常量,推导出int &&
int a;
auto &&r2 = a; // 绑定变量,推导出int &
int &&b = 1;
auto &&r3 = b; // 右值引用一旦绑定,则相当于普通变量,所以绑定变量,推导出int &由于&比&&优先级高,因此auto &一定推出左值引用,如果用auto &绑定常量或将亡对象则会报错:
auto &r1 = 5; // ERR,左值引用不能绑定常量
auto &r2 = GetAnObj(); // ERR,左值引用不能绑定将亡对象
int &&b = 1;
auto &r3 = b; // OK,左值引用可以绑定右值引用(因为右值引用一旦绑定后,相当于左值)
auto &r4 = r3; // OK,左值引用可以绑定左值引用(相当于绑定r4的引用源)前面的章节笔者频繁强调一个概念:右值引用一旦绑定,则相当于普通的引用(左值)。
这也就意味着,“右值”性质无法传递,请看例子:
void f1(int &&t1) {}
void f2(int &&t2) {
f1(t2); // 注意这里
}
void Demo() {
f2(5);
}在Demo函数中调用f2,f2的参数是int &&,用来绑定常量5没问题,但是,在f2函数内,t2是一个右值引用,而右值引用一旦绑定,则相当于左值,因此,不能再用右值引用去接收。所以f2内部调f1的过程会报错。这就是所谓“右值引用传递时会失去右性”。
那么如何保持右性呢?很无奈,只能层层转换:
void f1(int &&t1) {}
void f2(int &&t2) {
f1(std::move(t2)); // 保证右性
}
void Demo() {
f2(5);
}但我们来考虑另一个场景,在模板函数中这件事会怎么样?
template <typename T>
void f1(T &&t1) {}
template <typename T>
void f2(T &&t2) {
f1<T>(t2);
}
void Demo() {
f2<int &&>(5); // 传右值
int a;
f2<int &>(a); // 传左值
}由于f1和f2都是模板,因此,传入左值和传入右值的可能性都要有的,我们没法在f2中再强制std::move了,因为这样做会让左值变成右值传递下去,我们希望的是保持其左右性。
但如果不这样做,当我向f2传递右值时,右性无法传递下去,也就是t2是int &&类型,但是传递给f1的时候,t1变成了int &类型,这时t1是t2的引用(就是左值引用绑定右值引用的场景),并不是我们想要的。那怎么解决,如何让这种左右性质传递下去呢?就要用到模板元编程来完成了:
template <typename T>
T &forward(T &t) {
return t; // 如果传左值,那么直接传出
}
template <typename T>
T &&forward(T &&t) {
return std::move(t); // 如果传右值,那么保持右值性质传出
}
template <typename T>
void f1(T &&t1) {}
template <typename T>
void f2(T &&t2) {
f1(forward<T>(t2));
}
void Demo() {
f2<int &&>(5); // 传右值
int a;
f2<int &>(a); // 传左值
}上面展示的是std::forward的一个示例型的代码,便于读者理解,实际实现要稍微复杂一点。思路就是,根据传入的参数来判断,如果是左值引用就直接传出,如果是右值引用就std::move变成右值再传出,保证其左右性。std::forward又被称为“完美转发”,意义就在于传递引用时能保持其左右性。
C++11 提供了auto来自动推导类型,很大程度上提升了代码的直观性,例如:
std::unordered_map<std::string, std::vector<int>> data_map;
// 不用auto
std::unordered_map<std::string, std::vector<int>>::iterator iter = data_map.begin();
// 使用auto推导
auto iter = data_map.begin();但 auto 的推导仍然引入了不少奇怪的问题。首先,auto关键字仅仅是用来代替“类型符”的,它并没有改变“C++类型说明符具有多重意义”这件事,在前面“类型说明符”的章节我曾介绍过,C++中,类型说明符除了表示“类型”以外,还承担了“定义动作”的任务,auto可以视为一种带有类型推导的类型说明符,其本质仍然是类型说明符,所以,它同样承担了定义动作的任务,例如:
auto a = 5; // auto承担了“定义变量”的任务
但auto却不可以和[]组合定义数组,比如:
auto arr[] = {1, 2, 3}; // ERR
在定义函数上,更加有趣,在 C++14 以前,并不支持用auto推导函数返回值类型,但是却支持返回值后置语法,所以在这种场景下,auto仅仅是一个占位符而已,它既不表示类型,也不表示定义动作,仅仅就是为了结构完整占位而已:
auto func() -> int; // () -> int表示定义函数,int表示函数返回值类型
到了 C++14 才支持了返回值类型自动推导,但并不支持自动生成多种类型的返回值:
auto func(int cmd) {
if (cmd > 0) {
return 5; // 用5推导返回值为int
}
return std::string("123"); // ERR,返回值已经推导为int了,不能多类型返回
}同样还是出自这句话“auto 是用来代替类型说明符的”,因此auto在语义上也更加倾向于“用它代替类型说明符”这种行为,尤其是它和引用、指针类型结合时,这种特性更加明显:
int a = 5;
const int k = 9;
int &r = a;
auto b = a; // auto->int
auto c = 4; // auto->int
auto d = k; // auto->int
auto e = r; // auto->int我们看到,无论用普通变量、只读变量、引用、常量去初始化 auto 变量时,auto都只会推导其类型,而不会带有左右性、只读性这些内容。
所以,auto的类型推导,并不是“推导某个表达式的类型”,而是“推导当前位置合适的类型”,或者可以理解为“这里最简单可以是什么类型”。比如说上面auto c = 4这里,auto可以推导为int,int &&,const int,const int &,const int &&,而auto选择的是里面最简单的那一种。
auto还可以跟指针符、引用符结合,而这种时候它还是满足上面“最简单”的这种原则,并且此时指的是“auto本身最简单”,举例来说:
int a = 5;
auto p1 = &a; // auto->int *
auto *p2 = &a; // auto->int
auto &r1 = a; // auto->int
auto *p3 = &p2; // auto->int *
auto p4 = &p2; // auto-> int **p1和p2都是指针,但auto都是用最简原则来推导的,p2这里因为我们已经显式写了一个*了,所以auto只会推导出int,因此p2最终类型仍然是int *而不会变成int **。同样的道理在p3和p4上也成立。
在一些将“类型”和“动作”语义分离的语言中,就完全不会有 auto 的这种困扰,它们可以用“省略类型符”来表示“自动类型推导”的语义,而起“定义”语义的关键字得以保留而不受影响,例如在 swift 中:
var a = 5 // Int
let b = 5.6 // 只读Double
let c: Double = 8 // 显式指定类型在 Go 中也是类似的:
var a = 2.5 // var表示“定义变量”动作,自动推导a的类型为float64
b := 5 // 自动推导类型为int,:=符号表示了“定义动作”语义
const c = 7 // const表示“定义只读变量”动作,自动推导c类型为int
var d float32 = 9 // 显式指定类型在前面“引用折叠”的章节曾经提到过auto &&的推导原则,有可能会推导出左值引用来,所以auto &&并不是要“定义一个右值引用”,而是“定义一个保持左右性的引用”,也就是说,绑定一个左值时会推导出左值引用,绑定一个右值时会推导出右值引用。
int a = 5;
int &r1 = a;
int &&r2 = 4;
auto &&y1 = a; // int &
auto &&y2 = r1; // int &
auto &&y3 = r2; // int &(注意右值引用本身是左值)
auto &&y4 = 3; // int &&
auto &&y5 = std::move(r1); // int &&更详细的内容可以参考前面“引用折叠”的章节。
我相信大家现在看到auto都第一印象是 C++当中的“自动类型推导”,但其实auto并不是 C++11 引入的新关键在,在原始 C 语言中就有这一关键字的。
在原始 C 中,auto表示“自动变量位置”,与之对应的是register。在之前“const 引用”章节中笔者曾经提到,“变量就是内存变量”,但其实在原始 C 中,除了内存变量以外,还有一种变量叫做“寄存器变量”,也就是直接将这个数据放到 CPU 的寄存器中。也就是说,编译器可以控制这个变量的位置,如果更加需要读写速度,那么放到寄存器中更合适,因此auto表示让编译器自动决定放内存中,还是放寄存器中。而register修饰的则表示人工指定放在寄存器中。至于没有关键字修饰的,则表示希望放到内存中。
int a; // 内存变量
register int b; // 寄存器变量
auto int c; // 由编译器自动决定放在哪里需要注意的是,寄存器变量不能取址。这个很好理解,因为只有内存才有地址(地址本来指的就是内存地址),寄存器是没有的。因此,auto修饰的变量如果被取址了,那么一定会放在内存中:
auto int a; // 有可能放在内存中,也有可能放在寄存器中
auto int b;
int *p = &b; // 这里b被取址了,因此b一定只能放在内存中
register int c;
int *p2 = &c; // ERR,对寄存器变量取址,会报错然而在 C++中,几乎不会人工来控制变量的存放位置了,毕竟 C++更加上层一些,这样超底层的语法就被摒弃了(C++11 取消了register关键字,而auto关键字也失去其本意,变为了“自动类型推导”的占位符)。而关于变量的存储位置则是全权交给了编译器,也就是说我们可以理解为,在 C++11 以后,所有的变量都是自动变量,存储位置由编译器决定。
笔者在前面章节吐槽了const这个命名,也吐槽了“右值引用”这个命名。那么static就是笔者下一个要重点吐槽的命名了。static这个词本身没有什么问题,其主要的槽点就在于“一词多用”,也就是说,这个词在不同场景下表示的是完全不同的含义。(作者可能是出于节省关键词的目的吧,明明是不同的含义,却没有用不同的关键词)。
static,限定的是变量的生命周期static,限定的变量/函数的作用域static,限定的是成员变量的生命周期static,限定的是成员函数的调用方(或隐藏参数)上面是static关键字的 4 种不同含义,接下来逐一我会解释。
当用static修饰局部变量时,static表示其生命周期:
void f() {
static int count = 0;
count++;
}上例中,count是一个局部变量,既然已经是“局部变量”了,那么它的作用域很明显,就是f函数内部。而这里的static表示的是其生命周期。普通的全局变量在其所在函数(或代码块)结束时会被释放。而用static修饰的则不会,我们将其称为“静态局部变量”。 静态局部变量会在首次执行到定义语句时初始化,在主函数执行结束后释放,在程序执行过程中遇到定义(和初始化)语句时会忽略。
void f() {
static int count = 0;
count++;
std::cout << count << std::endl;
}
int main(int argc, const char *argv[]) {
f(); // 第一次执行时count被定义,并且初始化为0,执行后count值为1,并且不会释放
f(); // 第二次执行时由于count已经存在,因此初始化语句会无视,执行后count值为2,并且不会释放
f(); // 同上,执行后count值为3,不会释放
} // 主函数执行结束后会释放f中的count例如上面例程的输出结果会是:
1
2
3详细的说明已经在注释中,这里不再赘述。
当static修饰全局变量或函数时,用于限定其作用域为“当前文件内”。同理,由于已经是“全局”变量了,生命周期一定是符合全局的,也就是“主函数执行前构造,主函数执行结束后释放”。至于全局函数就不用说了,函数都是全局生命周期的。
因此,这时候的static不会再对生命周期有影响,而是限定了其作用域。与之对应的是extern。用extern修饰的全局变量/函数作用于整个程序内,换句话说,就是可以跨文件:
// a1.cc
int g_val = 4; // 定义全局变量
// a2.cc
extern int g_val; // 声明全局变量
void Demo() {
std::cout << g_val << std::endl; // 使用了在另一个文件中定义的全局变量
}而用static修饰的全局变量/函数则只能在当前文件中使用,不同文件间的static全局变量/函数可以同名,并且互相独立。
// a1.cc
static int s_val1 = 1; // 定义内部全局变量
static int s_val2 = 2; // 定义内部全局变量
static void f1() {} // 定义内部函数
// a2.cc
static int s_val1 = 6; // 定义内部全局变量,与a1.cc中的互不影响
static int s_val2; // 这里会视为定义了新的内部全局变量,而不会视为“声明”
static void f1(); // 声明了一个内部函数
void Demo() {
std::cout << s_val1 << std::endl; // 输出6,与a1.cc中的s_val1没有关系
std::cout << s_val2 << std::endl; // 输出0,同样不会访问到a1.cc中的s_val2
f1(); // ERR,这里链接会报错,因为在a2.cc中没有找到f1的定义,并不会链接到a1.cc中的f1
}所以我们发现,在这种场景下,static并不表示“静态”的含义,而是表示“内部”的含义,所以,为什么不再引入个类似于inner的关键字呢?这里很容易让程序员造成迷惑。
静态成员变量指的是用static修饰的成员变量。普通的成员变量其生命周期是跟其所属对象绑定的。构造对象时构造成员变量,析构对象时释放成员变量。
struct Test {
int a; // 普通成员变量
};
int main(int argc, const char *argv[]) {
Test t; // 同时构造t.a
auto t2 = new Test; // 同时构造t2->a
delete t2; // t2所指对象析构,同时释放t2->a
} // t析构,同时释放t.a而用static修饰后,其声明周期变为全局,也就是“主函数执行前构造,主函数执行结束后释放”,并且不再跟随对象,而是全局一份。
struct Test {
static int a; // 静态成员变量(基本等同于声明全局变量)
};
int Test::a = 5; // 初始化静态成员变量(主函数前执行,基本等同于初始化全局变量)
int main(int argc, const char *argv[]) {
std::cout << Test::a << std::endl; // 直接访问静态成员变量
Test t;
std::cout << t.a << std::endl; // 通过任意对象实例访问静态成员变量
} // 主函数结束时释放Test::a所以静态成员变量基本就相当于一个全局变量,而这时的类更像一个命名空间了。唯一的区别在于,通过类的实例(对象)也可以访问到这个静态成员变量,就像上面的t.a和Test::a完全等价。
static关键字修饰在成员函数前面,称为“静态成员函数”。我们知道普通的成员函数要以对象为主调方,对象本身其实是函数的一个隐藏参数(this 指针):
struct Test {
int a;
void f(); // 非静态成员函数
};
void Test::f() {
std::cout << this->a << std::endl;
}
void Demo() {
Test t;
t.f(); // 用对象主调成员函数
}上面其实等价于:
struct Test {
int a;
};
void f(Test *this) {
std::cout << this->a << std::endl;
}
void Demo() {
Test t;
f(&t); // 其实对象就是函数的隐藏参数
}也就是说,obj.f(arg)本质上就是f(&obj, arg),并且这个参数强制叫做this。这个特性在 Go 语言中尤为明显,Go 不支持封装到类内的成员函数,也不会自动添加隐藏参数,这些行为都是显式的:
type Test struct {
a int
}
func(t *Test) f() {
fmt.Println(t.a)
}
func Demo() {
t := new(Test)
t.f()
}回到 C++的静态成员函数这里来。用static修饰的成员函数表示“不需要对象作为主调方”,也就是说没有那个隐藏的this参数。
struct Test {
int a;
static void f(); // 静态成员函数
};
void Test::f() {
// 没有this,没有对象,只能做对象无关操作
// 也可以操作静态成员变量和其他静态成员函数
}可以看出,这时的静态成员函数,其实就相当于一个普通函数而已。这时的类同样相当于一个命名空间,而区别在于,如果这个函数传入了同类型的参数时,可以访问私有成员,例如:
class Test {
public:
static void f(const Test &t1, const Test &t2); // 静态成员函数
private:
int a; // 私有成员
};
void Test::f(const Test &t1, const Test &t2) {
// t1和t2是通过参数传进来的,但因为是Test类型,因此可以访问其私有成员
std::cout << t1.a + t2.a << std::endl;
}或者我们可以把静态成员函数理解为一个友元函数,只不过从设计角度上来说,与这个类型的关联度应该是更高的。但是从语法层面来解释,基本相当于“写在类里的普通函数”。
其实 C++中static造成的迷惑,同样也是因为 C 中的缺陷被放大导致的。毕竟在 C 中不存在构造、析构和引用链的问题。说到这个引用链,其实 C++中的静态成员变量、静态局部变量和全局变量还存在一个链路顺序问题,可能会导致内存重复释放、访问野指针等情况的发生。这部分的内容详见后面“平凡、标准布局”的章节。
总之,我们需要了解static关键字有多义性,了解其在不同场景下的不同含义,更有助于我们理解 C++语言,防止踩坑。
前阵子我和一个同事对这样一个问题进行了非常激烈的讨论:
到底应不应该定义 std::string 类型的全局变量
这个问题乍一看好像没什么值得讨论的地方,我相信很多程序员都在不经意间写过类似的代码,并且确实没有发现什么执行上的问题,所以可能从来没有意识到,这件事还有可能出什么问题。
我们和我同事之所以激烈讨论这个问题,一切的根源来源于谷歌的 C++编程规范,其中有一条是:
Static or global variables of class type are forbidden: they cause hard-to-find bugs due to indeterminate order of construction and destruction.
Objects with static storage duration, including global variables, static variables, static class member variables, and function static variables, must be Plain Old Data (POD): only ints, chars, floats, or pointers, or arrays/structs of POD.大致翻译一下就是说:不允许非 POD 类型的全局变量、静态全局变量、静态成员变量和静态局部变量,因为可能会导致难以定位的 bug。而std::string是非 POD 类型的,自然,按照规范,也不允许std::string类型的全局变量。
但是如果我们真的写了,貌似也从来没有遇到过什么问题,程序也不会出现任何 bug 或者异常,甚至下面的几种写法都是在日常开发中经常遇到的,但都不符合这谷歌的这条代码规范。
const std::string ip = "127.0.0.1";
const uint16_t port = 80;
void Demo() {
// 开启某个网络连接
SocketSvr svr{ip, port};
// 记录日志
WriteLog("net linked: ip:port={%s:%hu}", ip.c_str(), port);
}std::string GetDesc(int code) {
static const std::unordered_map<int, std::string> ma {
{0, "SUCCESS"},
{1, "DATA_NOT_FOUND"},
{2, "STYLE_ILLEGEL"},
{-1, "SYSTEM_ERR"}
};
if (auto res = ma.find(code); res != ma.end()) {
return res->second;
}
return "UNKNOWN";
}class SingleObj {
public:
SingleObj &GetInstance();
SingleObj(const SingleObj &) = delete;
SingleObj &operator =(const SingleObj &) = delete;
private:
SingleObj();
~SingleObj();
};
SingleObj &SingleObj::GetInstance() {
static SingleObj single_obj;
return single_obj;
}上面的几个例子都存在“非 POD 类型全局或静态变量”的情况。
既然谷歌规范中禁止这种情况,那一定意味着,这种写法存在潜在风险,我们需要搞明白风险点在哪里。 首先明确变量生命周期的问题:
这件事如果在 C 语言中,并没有什么问题,设计也很合理。但是 C++就是这样悲催,很多 C 当中合理的问题在 C++中会变得不合理,并且缺陷会被放大。
由于 C 当中的变量仅仅是数据,因此,它的“构造”和“释放”都没有什么副作用。但在 C++当中,“构造”是要调用构造函数来完成的,“释放”之前也是要先调用析构函数。这就是问题所在!照理说,主函数应该是程序入口,那么在主函数之前不应该调用任何自定义的函数才对。但这件事放到 C++当中就不一定成立了,我们看一下下面例程:
class Test {
public:
Test();
~Test();
};
Test::Test() {
std::cout << "create" << std::endl;
}
Test::~Test() {
std::cout << "destroy" << std::endl;
}
Test g_test; // 全局变量
int main(int argc, const char *argv[]) {
std::cout << "main function" << std::endl;
return 0;
}运行上面程序会得到以下输出:
create
main function
destroy也就是说,Test 的构造函数在主函数前被调用了。解释起来也很简单,因为“全局变量在主函数执行之前构造,主函数执行结束后释放”,而因为Test类型是类类型,“构造”时要调用构造函数,“释放”时要调用析构函数。所以上面的现象也就不奇怪了。
这种单一个的全局变量其实并不会出现什么问题,但如果有多变量的依赖,这件事就不可控了,比如下面例程:
test.h
struct Test1 {
int a;
};
extern Test1 g_test1; // 声明全局变量test.cc
Test1 g_test1 {4}; // 定义全局变量
main.cc
#include "test.h"
class Test2 {
public:
Test2(const Test1 &test1); // 传Test1类型参数
private:
int m_;
};
Test2::Test2(const Test1 &test1): m_(test1.a) {}
Test2 g_test2{g_test1}; // 用一个全局变量来初始化另一个全局变量
int main(int argc, const char *argv) {
return 0;
}上面这种情况,程序编译、链接都是没问题的,但运行时会概率性出错,问题就在于,g_test1和g_test2都是全局变量,并且是在不同文件中定义的,并且由于全局变量构造在主函数前,因此其初始化顺序是随机的。
假如g_test1在g_test2之前初始化,那么整个程序不会出现任何问题,但如果g_test2在g_test1前初始化,那么在Test2的构造函数中,得到的就是一个未初始化的test1引用,这时候访问test1.a就是操作野指针了。
这时我们就能发现,全局变量出问题的根源在于全局变量的初始化顺序不可控,是随机的,因此,如果出现依赖,则会导致问题。 同理,析构发生在主函数后,那么析构顺序也是随机的,可能出问题,比如:
struct Test1 {
int count;
};
class Test2 {
public:
Test2(Test1 *test1);
~Test2();
private:
Test1 *test1_;
};
Test2::Test2(Test1 *test1): test1_(test1) {
test1_->count++;
}
Test2::~Test2() {
test1_->count--;
}
Test1 g_test1 {0}; // 全局变量
void Demo() {
static Test2 t2{&g_test1}; // 静态局部变量
}
int main(int argc, const char *argv[]) {
Demo(); // 构造了t2
return 0;
}在上面示例中,构造t2的时候使用了g_test1,由于t2是静态局部变量,因此是在第一个调用时(主函数中调用Demo时)构造。这时已经是主函数执行过程中了,因此g_test1已经构造完毕的,所以构造时不会出现问题。
但是,静态成员变量是在主函数执行完成后析构,这和全局变量相同,因此,t2和g_test1的析构顺序无法控制。如果t2比g_test1先析构,那么不会出现任何问题。但如果g_test1比t2先析构,那么在析构t2时,对test1_访问count成员这一步,就会访问野指针。因为test1_所指向的g_test1已经先行析构了。
那么这个时候我们就可以确定,全局变量、静态变量之间不能出现依赖关系,否则,由于其构造、析构顺序不可控,因此可能会出现问题。
回到我们刚才提到的谷歌标准,这里标准的制定者正是因为担心这样的问题发生,才禁止了非 POD 类型的全局或静态变量。但我们分析后得知,也并不是说所有的类类型全局或静态变量都会出现问题。
而且,谷歌规范中的“POD 类型”的限定也过于广泛了。所谓“POD 类型”指的是“平凡”+“标准内存布局”,这里我来解释一下这两种性质,并且分析分析为什么谷歌标准允许 POD 类型的全局或静态变量。
“平凡(trivial)”指的是:
换句话说,六大特殊函数都是默认的。这里要区分 2 个概念,我们要的是“语法上的平凡”还是“实际意义上的平凡”。语法上的平凡就是说能够被编译期识别、认可的平凡。而实际意义上的平凡就是说里面没有额外操作。 比如说:
class Test1 {
public:
Test1() = default; // 默认无参构造函数
Test1(const Test1 &) = default; // 默认拷贝构造函数
Test &operator =(const Test1 &) = default; // 默认拷贝赋值函数
~Test1() = default; // 默认析构函数
};
class Test2 {
public:
Test2() {} // 自定义无参构造函数,但实际内容为空
~Test2() {std::printf("destory\n");} // 自定义析构函数,但实际内容只有打印
};上面的例子中,Test1就是个真正意义上的平凡类型,语法上是平凡的,因此编译器也会认为其是平凡的。我们可以用 STL 中的工具来判断一个类型是否是平凡的:
bool is_test1_tri = std::is_trivial_v<Test1>; // true
但这里的 Test2,由于我们自定义了其无参构造函数和析构函数,那么对编译器来说,它就是非平凡的,我们用std::is_trivial来判断也会得到false_value。但其实内部并没有什么外链操作,所以其实我们把Test2类型定义全局变量时也不会出现任何问题,这就是所谓“实际意义上的平凡”。
C++对“平凡”的定义比较严格,但实际上我们看看如果要做全局变量或静态变量的时候,是不需要这样严格定义的。对于全局变量来说,只要定义全局变量时,使用的是“实际意义上平凡”的构造函数,并且拥有“实际意义上平凡”的析构函数,那这个全局变量定义就不会有任何问题。而对于静态局部变量来说,只要拥有“实际意义上平凡”的析构函数的就一定不会出问题。
标准内存布局的定义是:
public,或都protected,或都private);我们同样可以用 STL 中的std::is_standard_layout来判断一个类型是否是标准内存布局的。这里的定义比较简单,不在赘述。
所谓 POD 类型就是同时符合“平凡”和“标准内存布局”的类型。符合这个类型的基本就是基本数据类型,加上一个普通 C 语言的结构体。换句话说,符合“旧类型(C 语言中的类型)行为的类型”,它不存在虚函数指针、不存在虚表,可以视为普通二进制来操作的。
因此,在 C++中,只有 POD 类型可以用memcpy这种二进制方法来复制而不会产生副作用,其他类型的都必须用用调用拷贝构造。
以前有人向笔者提出疑问,为何vector扩容时不直接用类似于memcpy的方式来复制,而是要以此调用拷贝构造。原因正是在此,对于非 POD 类型的对象,其中可能会包含虚表、虚函数指针等数据,复制时这些内容可能会重置,并且内部可能会含有一些类似于“计数”这样操作其他引用对象的行为,因为一定要用拷贝构造函数来保证这些行为是正常的,而不能简单粗暴地用二进制方式进行拷贝。
STL 中可以用std::is_pod来判断是个类型是否是 POD 的。
我们再回到谷歌规范中,POD 的限制比较多,因此,确实 POD 类型的全局/静态变量是肯定不会出问题的,但直接将非 POD 类型的一棍子打死,笔者个人认为有点过了,没必要。
所以,笔者认为更加精确的限定应该是:对于全局变量、静态成员变量来说,初始化时必须调用的是平凡的构造函数,并且其应当拥有平凡的析构函数,而且这里的“平凡”是指实际意义上的平凡,也就是说可以自定义,但是在内部没有对任何其他的对象进行操作;对于静态局部变量来说,其应当拥有平凡的析构函数,同样指的是实际意义上的平凡,也就是它的析构函数中没有对任何其他的对象进行操作。
最后举几个例子:
class Test1 {
public:
Test1(int a): m_(a) {}
void show() const {std::printf("%d\n", m_);}
private:
int m_;
};
class Test2 {
public:
Test2(Test1 *t): m_(t) {}
Test2(int a): m_(nullptr) {}
~Test2() {}
private:
Test1 *m_;
};
class Test3 {
public:
Test3(const Test1 &t): m_(&t) {}
~Test3() {m_->show();}
private:
Test1 *m_;
};
class Test4 {
public:
Test4(int a): m_(a) {}
~Test4() = default;
private:
Test1 m_;
};Test1是非平凡的(因为无参构造函数没有定义),但它仍然可以定义全局/静态变量,因为Test1(int)构造函数是“实际意义上平凡”的。
Test2是非平凡的,并且Test2(Test1 *)构造函数需要引用其他类型,因此它不能通过Test2(Test1 *)定义全局变量或静态成员变量,但可以通过Test2(int)来定义全局变量或静态成员变量,因为这是一个“实际意义上平凡”的构造函数。而且因为它的析构函数是“实际意义上平凡”的,因此Test2类型可以定义静态局部变量。
Test3是非平凡的,构造函数对Test1有引用,并且析构函数中调用了Test1::show方法,因此Test3类型不能用来定义局部/静态变量。
Test4也是非平凡的,并且内部存在同样非平凡的Test1类型成员,但是因为m1_不是引用或指针,一定会随着Test4类型的对象的构造而构造,析构而析构,不存在顺序依赖问题,因此Test4可以用来定义全局/静态变量。
最后回到这个问题上,笔者认为定义一个全局的std::string类型的变量并不会出现什么问题,在std::string的内部,数据空间是通过new的方式申请的,并且一般情况下都不会被其他全局变量所引用,在std::string对象析构时,对这片空间会进行delete,所以并不会出现析构顺序问题。
但是,如果你用的不是默认的内存分配器,而是自定义了内存分配器的话,那确实要考虑构造析构顺序的问题了,你要保证在对象构造前,内存分配器是存在的,并且内存分配器的析构要在所有对象之后。
当然了,如果你仅仅是想给字符串常量起个别名的话,有一种更好的方式:
constexpr const char *ip = "127.0.0.1";
毕竟指针一定是平凡类型,而且用constexpr修饰后可以变为编译期常量。这里详情可以在后面“constexpr”的章节了解。
而至于其他类型的静态局部变量(比如说单例模式,或者局部内的map之类的映射表),只要让它不被析构就好了,所以可以用堆空间的方式:
static Test &Test::GetInstance() {
static Test &inst = *new Test;
return inst;
}std::string GetDesc(int code) {
static const auto &desc = *new std::map<int, std::string> {
{1, "desc1"},
{2, "desc2"},
};
auto iter = desc.find(code);
return iter == desc.end() ? "no_desc" : iter->second;
}在讨论完平凡类型后,我们发现平凡析构其实是更加值得关注的场景。这里就引申出非平凡析构的移动语义问题,请看例程:
class Buffer {
public:
Buffer(size_t size): buf(new int[size]), size(size) {}
~Buffer() {delete [] buf;}
Buffer(const Buffer &ob): buf(new int[ob.size]), size(ob.size) {}
Buffer(Buffer &&ob): buf(ob.buf), size(ob.size) {}
private:
int *buf;
size_t size;
};
void Demo() {
Buffer buf{16};
Buffer nb = std::move(buf);
} // 这里会报错还是这个简单的缓冲区的例子,如果我们调用Demo函数,那么结束时会报重复释放内存的异常。
那么在上面例子中,buf和nb中的buf指向的是同一片空间,当Demo函数结束时,buf销毁会触发一次Buffer的析构,nb析构时也会触发一次Buffer的析构。而析构函数中是delete操作,所以堆空间会被释放两次,导致报错。
这也就是说,对于非平凡析构类型,其发生移动语义后,应当放弃对原始空间的控制。
如果我们修改一下代码,那么这种问题就不会发生:
class Buffer {
public:
Buffer(size_t size): buf(new int[size]), size(size) {}
~Buffer();
Buffer(const Buffer &ob): buf(new int[ob.size]), size(ob.size) {}
Buffer(Buffer &&ob): buf(ob.buf), size(ob.size) {ob.buf = nullptr;} // 重点在这里
private:
int *buf;
};
Buffer::~Buffer() {
if (buf != nullptr) {
delete [] buf;
}
}
void Demo() {
Buffer buf{16};
Buffer nb = std::move(buf);
} // OK,没有问题由于移动构造函数和移动赋值函数是我们可以自定义的,因此,可以把重复析构产生的问题在这个里面考虑好。例如上面的把对应指针置空,而析构时再进行判空即可。
因此,我们得出的结论是并不是说非平凡析构的类型就不可以使用移动语义,而是非平凡析构类型进行移动构造或移动赋值时,要考虑引用权释放问题。
在讲解私有继承和多继承之前,笔者要先澄清一件事:C++不是单纯的面相对象的语言。同样地,它也不是单纯的面向过程的语言,也不是函数式语言,也不是接口型语言……
真的要说,C++是一个多范式语言,也就是说它并不是为了某种编程范式来创建的。C++的语法体系完整且庞大,很多范式都可以用 C++来展现。因此,不要试图用任一一种语言范式来解释 C++语法,不然你总能找到各种漏洞和奇怪的地方。
举例来说,C++中的“继承”指的是一种语法现象,而面向对象理论中的“继承”指的是一种类之间的关系。这二者是有本质区别的,请读者一定一定要区分清楚。
以面向对象为例,C++当然可以面向对象编程(OOP),但由于 C++并不是专为 OOP 创建的语言,自然就有 OOP 理论解释不了的语法现象。比如说多继承,比如说私有继承。
C++与 java 不同,java 是完全按照 OOP 理论来创建的,因此所谓“抽象类”,“接口(协议)类”的语义是明确可以和 OOP 对应上的,并且,在 OOP 理论中,“继承”关系应当是"A is a B"的关系,所以不会存在 A 既是 B 又是 C 的这种情况,自然也就不会出现“多继承”这样的语法。
但是在 C++中,考虑的是对象的布局,而不是 OOP 的理论,所以出现私有继承、多继承等这样的语法也就不奇怪了。
笔者曾经听有人持有下面这样类似的观点:
等等这些观点,它们其实都有一个共同的前提,那就是“我要用 C++来支持 OOP 范式”。如果我们用 OOP 范式来约束 C++,那么上面这些观点都是非常正确的,否则将不符合 OOP 的理论,例如:
class Pet {};
class Cat : public Pet {};
class Dog : public Pet {};
void Demo() {
Pet pet; // 一个不属于猫、狗等具体类型,仅仅属于“宠物”的实例,显然不合理
}Pet既然作为一个抽象概念存在,自然就不应当有实体。同理,如果一个类含有未完全实现的虚函数,就证明这个类属于某种抽象,它就不应该允许创建实例。而可以创建实例的类,一定就是最“具象”的定义了,它就不应当再被继承。
在 OOP 的理论下,多继承也是不合理的:
class Cat {};
class Dog {};
class SomeProperty : public Cat, public Dog {}; // 啥玩意会既是猫也是狗?但如果是“协议父类”的多继承就是合理的:
class Pet { // 协议类
public:
virtual void Feed() = 0; // 定义了喂养方式就可以成为宠物
};
class Animal {};
class Cat : public Animal, public Pet { // 遵守协议,实现其需方法
public:
void Feed() override; // 实现协议方法
};上面例子中,Cat虽然有 2 个父类,但Animal才是真正意义上的父类,也就是Cat is a (kind of) Animal的关系,而Pet是协议父类,也就是Cat could be a Pet,只要一个类型可以完成某些行为,那么它就可以“作为”这样一种类型。
在 java 中,这两种类型是被严格区分开的:
interface Pet { // 接口类
public void Feed();
}
abstract class Animal {} // 抽象类,不可创建实例
class Cat extends Animal implements Pet {
public void Feed() {}
}子类与父类的关系叫“继承”,与协议(或者叫接口)的关系叫“实现”。
与 C++同源的 Objective-C 同样是 C 的超集,但从名称上就可看出,这是“面向对象的 C”,语法自然也是针对 OOP 理论的,所以 OC 仍然只支持单继承链,但可以定义协议类(类似于 java 中的接口类),“继承”和“遵守(类似于 java 中的实现语义)”仍然是两个分离的概念:
@protocol Pet <NSObject> // 定义协议
- (void)Feed;
@end
@interface Animal : NSObject
@end
@interface Cat : Animal<Pet> // 继承自Animal类,遵守Pet协议
- (void)Feed;
@end
@implementation Cat
- (void)Feed {
// 实现协议接口
}
@end相比,C++只能说“可以”用做 OOP 编程,但 OOP 并不是其唯一范式,也就不会针对于 OOP 理论来限制其语法。这一点,希望读者一定要明白。
在此强调,这个标题中,第一个“继承”指的是一种 C++语法,也就是class A : B {};这种写法。而第二个“继承”指的是 OOP(面向对象编程)的理论,也就是 A is a B 的抽象关系,类似于“狗”继承自“动物”的这种关系。
所以我们说,私有继承本质是表示组合的,而不是继承关系,要验证这个说法,只需要做一个小实验即可。我们知道最能体现继承关系的应该就是多态了,如果父类指针能够指向子类对象,那么即可实现多态效应。请看下面的例程:
class Base {};
class A : public Base {};
class B : private Base {};
class C : protected Base {};
void Demo() {
A a;
B b;
C c;
Base *p = &a; // OK
p = &b; // ERR
p = &c; // ERR
}这里我们给Base类分别编写了A、B、C三个子类,分别是public、private和protected继承。然后用Base *类型的指针去分别指向a、b、c。发现只有public继承的a对象可以用p直接指向,而b和c都会报这样的错:
Cannot cast 'B' to its private base class 'Base'
Cannot cast 'C' to its protected base class 'Base'也就是说,私有继承是不支持多态的,那么也就印证了,他并不是 OOP 理论中的“继承关系”,但是,由于私有继承会继承成员变量,也就是可以通过b和c去使用a的成员,那么其实这是一种组合关系。或者,大家可以理解为,把b.a.member改写成了b.A::member而已。
那么私有继承既然是用来表示组合关系的,那我们为什么不直接用成员对象呢?为什么要使用私有继承?这是因为用成员对象在某种情况下是有缺陷的。
在解释私有继承的意义之前,我们先来看一个问题,请看下面例程
class T {};
// sizeof(T) = ?T是一个空类,里面什么都没有,那么这时T的大小是多少?照理说,空类的大小就是应该是0,但如果真的设置为0的话,会有很严重的副作用,请看例程:
class T {};
void Demo() {
T arr[10];
sizeof(arr); // 0
T *p = arr + 5;
// 此时p==arr
p++; // ++其实无效
}发现了吗?假如T的大小是0,那么T指针的偏移量就永远是0,T类型的数组大小也将是0,而如果它成为了一个成员的话,问题会更严重:
struct Test {
T t;
int a;
};
// t和a首地址相同由于T是0大小,那么此时Test结构体中,t和a就会在同一首地址。 所以,为了避免这种 0 长的问题,编译器会针对于空类自动补一个字节的大小,也就是说其实sizeof(T)是 1,而不是 0。
这里需要注意的是,不仅是绝对的空类会有这样的问题,只要是不含有非静态成员变量的类都有同样的问题,例如下面例程中的几个类都可以认为是空类:
class A {};
class B {
static int m1;
static int f();
};
class C {
public:
C();
~C();
void f1();
double f2(int arg) const;
};有了自动补 1 字节,T的长度变成了 1,那么T*的偏移量也会变成 1,就不会出现 0 长的问题。但是,这么做就会引入另一个问题,请看例程:
class Empty {};
class Test {
Empty m1;
long m2;
};
// sizeof(Test)==16由于Empty是空类,编译器补了 1 字节,所以此时m1是 1 字节,而m2是 8 字节,m1之后要进行字节对齐,因此Test变成了 16 字节。如果Test中出现了很多空类成员,这种问题就会被继续放大。
这就是用成员对象来表示组合关系时,可能会出现的问题,而私有继承就是为了解决这个问题的。
在上一节最后的历程中,为了让m1不再占用空间,但又能让Test中继承Empty类的其他内容(例如函数、类型重定义等),我们考虑将其改为继承来实现,EBO 就是说,当父类为空类的时候,子类中不会再去分配父类的空间,也就是说这种情况下编译器不会再去补那 1 字节了,节省了空间。
但如果使用public继承会怎么样?
class Empty {};
class Test : public Empty {
long m2;
};
// 假如这里有一个函数让传Empty类对象
void f(const Empty &obj) {}
// 那么下面的调用将会合法
void Demo() {
Test t;
f(t); // OK
}Test由于是Empty的子类,所以会触发多态性,t会当做Empty类型传入f中。这显然问题很大呀!如果用这个例子看不出问题的话,我们换一个例子:
class Alloc {
public:
void *Create();
void Destroy();
};
class Vector : public Alloc {
};
// 这个函数用来创建buffer
void CreateBuffer(const Alloc &alloc) {
void *buffer = alloc.Create(); // 调用分配器的Create方法创建空间
}
void Demo() {
Vector ve; // 这是一个容器
CreateBuffer(ve); // 语法上是可以通过的,但是显然不合理
}内存分配器往往就是个空类,因为它只提供一些方法,不提供具体成员。Vector是一个容器,如果这里用public继承,那么容器将成为分配器的一种,然后调用CreateBuffer的时候可以传一个容器进去,这显然很不合理呀!
那么此时,用私有继承就可以完美解决这个问题了
class Alloc {
public:
void *Create();
void Destroy();
};
class Vector : private Alloc {
private:
void *buffer;
size_t size;
// ...
};
// 这个函数用来创建buffer
void CreateBuffer(const Alloc &alloc) {
void *buffer = alloc.Create(); // 调用分配器的Create方法创建空间
}
void Demo() {
Vector ve; // 这是一个容器
CreateBuffer(ve); // ERR,会报错,私有继承关系不可触发多态
}此时,由于私有继承不可触发多态,那么Vector就并不是Alloc的一种,也就是说,从 OOP 理论上来说,他们并不是继承关系。而由于有了私有继承,在Vector中可以调用Alloc里的方法以及类型重命名,所以这其实是一种组合关系。 而又因为 EBO,所以也不用担心Alloc占用Vector的成员空间的问题。
谷歌规范中规定了继承必须是public的,这主要还是在贴近 OOP 理论。另一方面就是说,虽然使用私有继承是为了压缩空间,但一定程度上也是牺牲了代码的可读性,让我们不太容易看得出两种类型之间的关系,因此在绝大多数情况下,还是应当使用public继承。不过笔者仍然持有“万事皆不可一棒子打死”的观点,如果我们确实需要 EBO 的特性否则会大幅度牺牲性能的话,那么还是应当允许使用私有继承。
与私有继承类似,C++的多继承同样是“语法上”的继承,而实际意义上可能并不是 OOP 中的“继承”关系。再以前面章节的 Pet 为例:
class Pet {
public:
virtual void Feed() = 0;
};
class Animal {};
class Cat : public Animal, public Pet {
public:
void Feed() override;
};从形式上来说,Cat同时继承自Anmial和Pet,但从 OOP 理论上来说,Cat和Animal是继承关系,而和Pet是实现关系,前面章节已经介绍得很详细了,这里不再赘述。
但由于 C++并不是完全针对 OOP 的,因此支持真正意义上的多继承,也就是说,即便父类不是这种纯虚类,也同样支持集成,从语义上来说,类似于“交叉分类”。请看示例:
class Organic { // 有机物
};
class Inorganic { // 无机物
};
class Acid { // 酸
};
class Salt { // 盐
};
class AceticAcid : public Organic, public Acid { // 乙酸
};
class HydrochloricAcid : public Inorganic, public Acid { // 盐酸
};
class SodiumCarbonate : public Inorganic, public Salt { // 碳酸钠
};上面就是一个交叉分类法的例子,使用多继承语法合情合理。如果换做其他 OOP 语言,可能会强行把“酸”或者“有机物”定义为协议类,然后用继承+实现的方式来完成。但如果从化学分类上来看,无论是“酸碱盐”还是“有机物无机物”,都是一种强分类,比如说“碳酸钠”,它就是一种“无机物”,也是一种“盐”,你并不能用类似于“猫是一种动物,可以作为宠物”的理论来解释,不能说“碳酸钠是一种盐,可以作为一种无机物”。
因此 C++中的多继承是哪种具体意义,取决于父类本身是什么。如果父类是个协议类,那这里就是“实现”语义,而如果父类本身就是个实际类,那这里就是“继承”语义。当然了,像私有继承的话表示是“组合”语义。不过 C++本身并不在意这种语义,有时为了方便,我们也可能用公有继承来表示组合语义,比如说:
class Point {
public:
double x, y;
};
class Circle : public Point {
public:
double r; // 半径
};这里Circle继承了Point,但显然不是说“圆是一个点”,这里想表达的就是圆类“包含了”点类的成员,所以只是为了复用。从意义上来说,Circle类中继承来的x和y显然表达的是圆心的坐标。不过这样写并不符合设计规范,但笔者用这个例子希望解释的是C++并不在意类之间实际是什么关系,它在意的是数据复用,因此我们更需要了解一下多继承体系中的内存布局。
对于一个普通的类来说,内存布局就是按照成员的声明顺序来布局的,与 C 语言中结构体布局相同,例如:
class Test1 {
public:
char a;
int b;
short c;
};那么Test1的内存布局就是
| 字节编号 内容 | |
|---|---|
| 0 | a |
| 1~3 | 内存对齐保留字节 |
| 4~7 | b |
| 8~9 | c |
| 9~11 | 内存对齐保留字节 |
但如果类中含有虚函数,那么还会在末尾添加虚函数表的指针,例如:
class Test1 {
public:
char a;
int b;
short c;
virtual void f() {}
};| 字节编号 | 内容 |
|---|---|
| 0 | a |
| 1~3 | 内存对齐保留字节 |
| 4~7 | b |
| 8~9 | c |
| 9~15 | 内存对齐保留字节 |
| 16~23 | 虚函数表指针 |
多继承时,第一父类的虚函数表会与本类合并,其他父类的虚函数表单独存在,并排列在本类成员的后面。
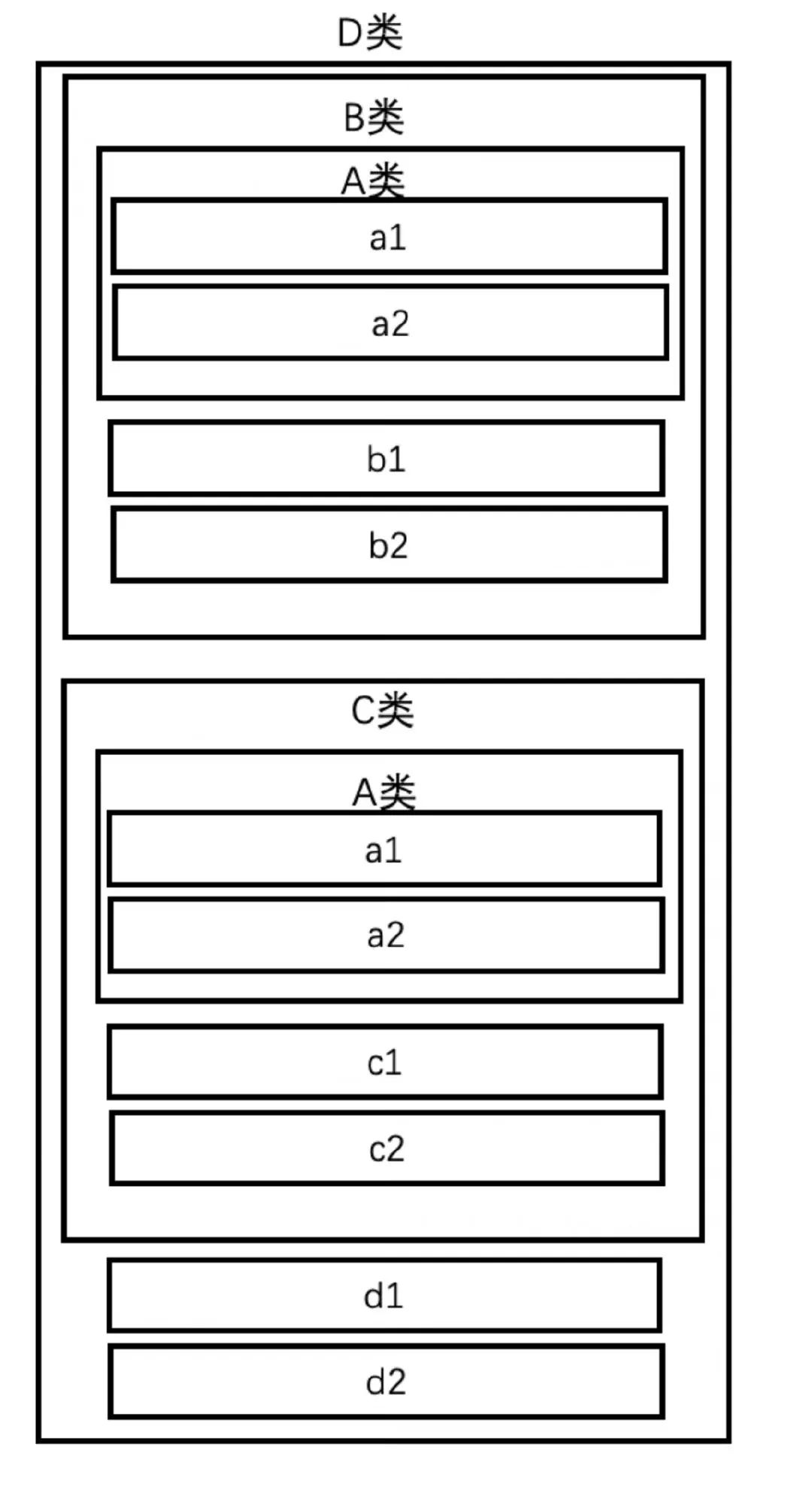
C++由于支持“普适意义上的多继承”,那么就会有一种特殊情况——菱形继承,请看例程:
struct A {
int a1, a2;
};
struct B : A {
int b1, b2;
};
struct C : A {
int c1, c2;
};
struct D : B, C {
int d1, d2;
};根据内存布局原则,D类首先是B类的元素,然后D类自己的元素,最后是C类元素:
| 字节序号 | 意义 |
|---|---|
| 0~15 | B 类元素 |
| 16~19 | d1 |
| 20~23 | d2 |
| 24~31 | C 类元素 |
如果再展开,会变成这样:
| 字节序号 | 意义 |
|---|---|
| 0~3 | a1(B 类继承自 A 类的) |
| 16~19 | d1 |
| 4~7 | a2(B 类继承自 A 类的) |
| 8~11 | b1 |
| 12~15 | b2 |
| 16~19 | d1 |
| 20~23 | d2 |
| 24~27 | a1(C 类继承自 A 类的) |
| 28~31 | a1(C 类继承自 A 类的) |
| 32~35 | c1 |
| 36~39 | c2 |
可以发现,A 类的成员出现了 2 份,这就是所谓“菱形继承”产生的副作用。这也是 C++的内存布局当中的一种缺陷,多继承时第一个父类作为主父类合并,而其余父类则是直接向后扩写,这个过程中没有去重的逻辑(详情参考上一节)。这样的话不仅浪费空间,还会出现二义性问题,例如d.a1到底是指从B继承来的a1还是从C里继承来的呢?
C++引入虚拟继承的概念就是为了解决这一问题。但怎么说呢,C++的复杂性往往都是因为为了解决一种缺陷而引入了另一种缺陷,虚拟继承就是非常典型的例子,如果你直接去解释虚拟继承(比如说和普通继承的区别)你一定会觉得莫名其妙,为什么要引入一种这样奇怪的继承方式。所以这里需要我们了解到,它是为了解决菱形继承时空间爆炸的问题而不得不引入的。
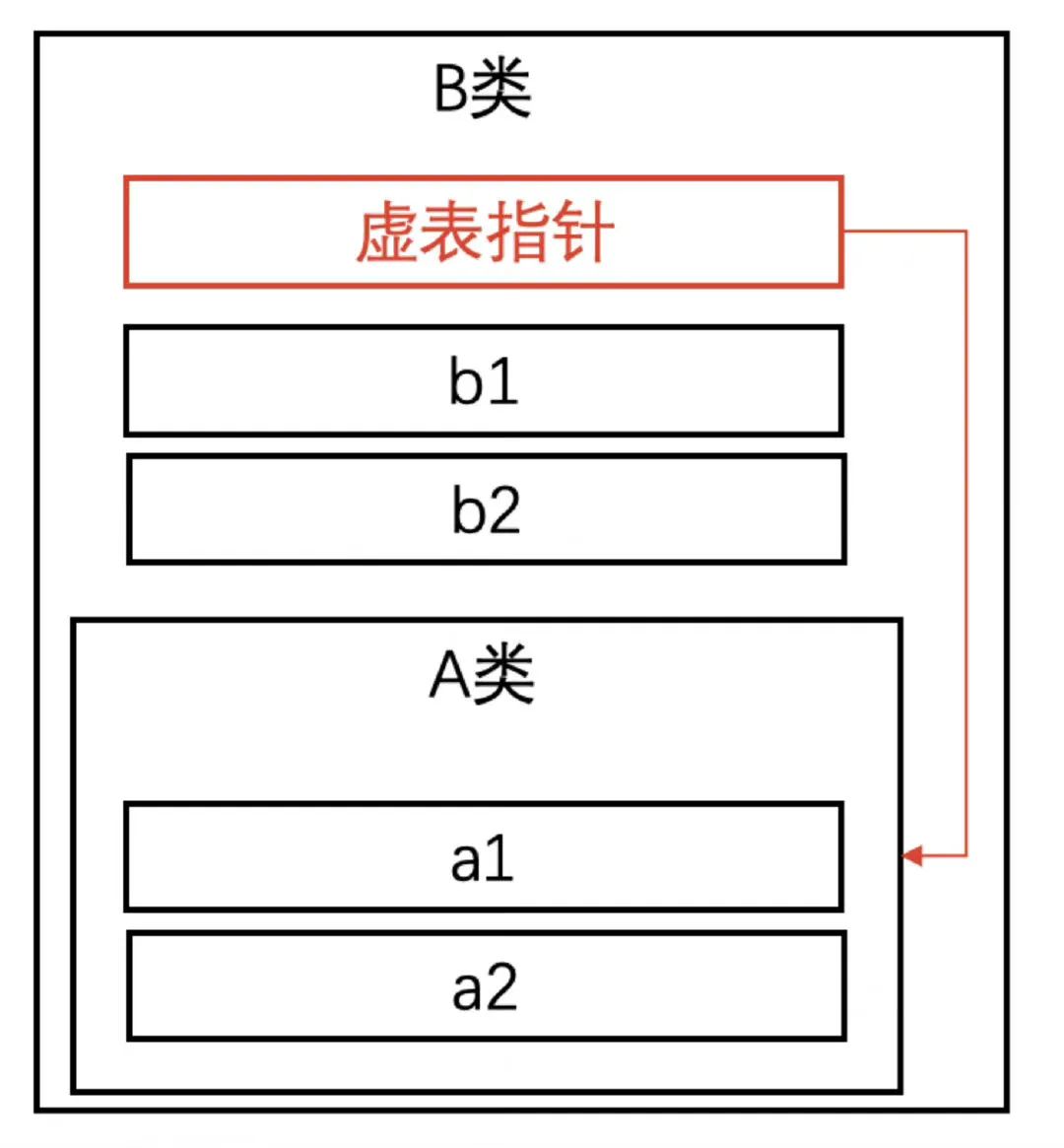
首先我们来看一下普通的继承和虚拟继承的区别: 普通继承:
struct A {
int a1, a2;
};
struct B : A {
int b1, b2;
};B的对象模型应该是这样的:

struct A {
int a1, a2;
};
struct B : virtual A {
int b1, b2;
};对象模型是这样的:
就像刚才说的那样,单纯的虚拟继承看上去很离谱,因为完全没有必要强行更换这样的内存布局,所以绝大多数情况下我们是不会用虚拟继承的。但是菱形继承的情况,就不一样了,普通的菱形继承会这样:
struct A {
int a1, a2;
};
struct B : A {
int b1, b2;
};
struct C : A {
int c1, c2;
};
struct D : B, C {
int d1, d2;
};D的对象模型:
struct A {
int a1, a2;
};
struct B : virtual A {
int b1, b2;
};
struct C : virtual A {
int c1, c2;
};
struct D : B, C {
int d1, d2;
};D的对象模型将会变成:
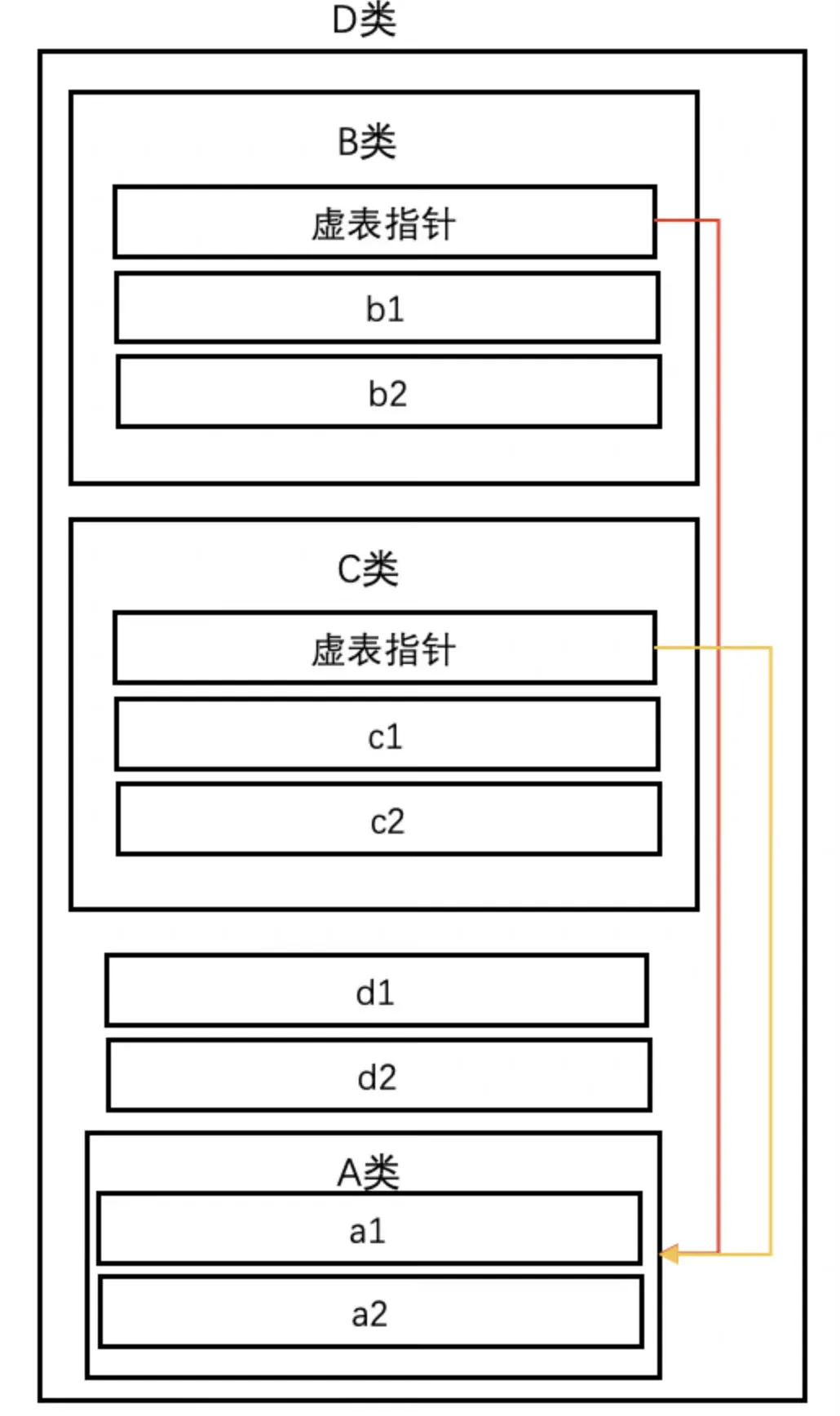
但需要注意的是,D继承自B和C时是普通继承,如果用了虚拟继承,则会在 D 内部又额外添加一份虚基表指针。要虚拟继承的是B和C对A的继承,这也是虚拟继承语法非常迷惑的地方,也就是说,菱形继承的分支处要用虚拟继承,而汇聚处要用普通继承。所以我们还是要明白其底层原理,以及引入这个语法的原因(针对解决的问题),才能更好的使用这个语法,避免出错。
隐式构造指的就是隐式调用构造函数。换句话说,我们不用写出类型名,而是仅仅给出构造参数,编译期就会自动用它来构造对象。举例来说:
class Test {
public:
Test(int a, int b) {}
};
void f(const Test &t) {
}
void Demo() {
f({1, 2}); // 隐式构造Test临时对象,相当于f(Test{a, b})
}上面例子中,f需要接受的是Test类型的对象,然而我们在调用时仅仅使用了构造参数,并没有指定类型,但编译器会进行隐式构造。
尤其,当构造参数只有 1 个的时候,可以省略大括号:
class Test {
public:
Test(int a) {}
Test(int a, int b) {}
};
void f(const Test &t) {
}
void Demo() {
f(1); // 隐式构造Test{1},单参时可以省略大括号
f({2}); // 隐式构造Test{2}
f({1, 2}); // 隐式构造Test{1, 2}
}这样做的好处显而易见,就是可以让代码简化,尤其是在构造string或者vector的时候更加明显:
void f1(const std::string &str) {}
void f2(const std::vector<int> &ve) {}
void Demo() {
f1("123"); // 隐式构造std::string{"123"},注意字符串常量是const char *类型
f2({1, 2, 3}); // 隐式构造std::vector,注意这里是initialize_list构造
}当然,如果遇到函数重载,原类型的优先级大于隐式构造,例如:
class Test {
public:
Test(int a) {}
};
void f(const Test &t) {
std::cout << 1 << std::endl;
}
void f(int a) {
std::cout << 2 << std::endl;
}
void Demo() {
f(5); // 会输出2
}但如果有多种类型的隐式构造则会报二义性错误:
class Test1 {
public:
Test1(int a) {}
};
class Test2 {
public:
Test2(int a) {}
};
void f(const Test1 &t) {
std::cout << 1 << std::endl;
}
void f(const Test2 &t) {
std::cout << 2 << std::endl;
}
void Demo() {
f(5); // ERR,二义性错误
}在返回值场景也支持隐式构造,例如:
struct err_t {
int err_code;
const char *err_msg;
};
err_t f() {
return {0, "success"}; // 隐式构造err_t
}但隐式构造有时会让代码含义模糊,导致意义不清晰的问题(尤其是单参的构造函数),例如:
class System {
public:
System(int version);
};
void Operate(const System &sys, int cmd) {}
void Demo() {
Operate(1, 2); // 意义不明确,不容易让人意识到隐式构造
}上例中,System表示一个系统,其构造参数是这个系统的版本号。那么这时用版本号的隐式构造就显得很突兀,而且只通过Operate(1, 2)这种调用很难让人想到第一个参数竟然是System类型的。
因此,是否应当隐式构造,取决于隐式构造的场景,例如我们用const char *来构造std::string就很自然,用一组数据来构造一个std::vector也很自然,或者说,代码的阅读者非常直观地能反应出来这里发生了隐式构造,那么这里就适合隐式构造,否则,这里就应当限定必须显式构造。用explicit关键字限定的构造函数不支持隐式构造:
class Test {
public:
explicit Test(int a);
explicit Test(int a, int b);
Test(int *p);
};
void f(const Test &t) {}
void Demo() {
f(1); // ERR,f不存在int参数重载,Test的隐式构造不允许用(因为有explicit限定),所以匹配失败
f(Test{1}); // OK,显式构造
f({1, 2}); // ERR,同理,f不存在int, int参数重载,Test隐式构造不许用(因为有explicit限定),匹配失败
f(Test{1, 2}); // OK,显式构造
int a;
f(&a); // OK,隐式构造,调用Test(int *)构造函数
}还有一种情况就是,对于变参的构造函数来说,更要优先考虑要不要加explicit,因为变参包括了单参,并且默认情况下所有类型的构造(模板的所有实例,任意类型、任意个数)都会支持隐式构造,例如:
class Test {
public:
template <typename... Args>
Test(Args&&... args);
};
void f(const Test &t) {}
void Demo() {
f(1); // 隐式构造Test{1}
f({1, 2}); // 隐式构造Test{1, 2}
f("abc"); // 隐式构造Test{"abc"}
f({0, "abc"}); // 隐式构造Test{0, "abc"}
}所以避免爆炸(生成很多不可控的隐式构造),对于变参构造最好还是加上explicit,如果不加的话一定要慎重考虑其可能实例化的每一种情况。
在谷歌规范中,单参数构造函数必须用explicit限定,但笔者认为这个规范并不完全合理,在个别情况隐式构造意义非常明确的时候,还是应当允许使用隐式构造。另外,即便是多参数的构造函数,如果当隐式构造意义不明确时,同样也应当用explicit来限定。所以还是要视情况而定。
C++支持隐式构造,自然考虑的是一些场景下代码更简洁,但归根结底在于C++主要靠 STL 来扩展功能,而不是语法。举例来说,在 Swift 中,原生语法支持数组、map、字符串等:
let arr = [1, 2, 3] // 数组
let map = [1 : "abc", 25 : "hhh", -1 : "fail"] // map
let str = "123abc" // 字符串因此,它并不需要所谓隐式构造的场景,因为语法本身已经表明了它的类型。
而 C++不同,C++并没有原生支持std::vector、std::map、std::string等的语法,这就会让我们在使用这些基础工具的时候很头疼,因此引入隐式构造来简化语法。所以归根结底,C++语言本身考虑的是语法层面的功能,而数据逻辑层面靠 STL 来解决,二者并不耦合。但又希望程序员能够更加方便地使用 STL,因此引入了一些语言层面的功能,但它却像全体类型开放了。
举例来说,Swift 中,[1, 2, 3]的语法强绑定Array类型,[k1:v1, k2,v2]的语法强绑定Map类型,因此这里的“语言”和“工具”是耦合的。但 C++并不和 STL 耦合,他的思路是{x, y, z}就是构造参数,哪种类型都可以用,你交给vector时就是表示数组,你交给map时就是表示 kv 对,并不会将“语法”和“类型”做任何强绑定。因此把隐式构造和explicit都提供出来,交给开发者自行处理是否支持。
这是我们需要体会的 C++设计理念,当然,也可以算是 C++的缺陷。
字符串同样是 C++特别容易踩坑的位置。出于对 C 语言兼容、以及上一节所介绍的 C++希望将“语言”和“类型”解耦的设计理念的目的,在 C++中,字符串并没有映射为std::string类型,而是保留 C 语言当中的处理方式。编译期会将字符串常量存储在一个全局区,然后再使用字符串常量的位置用一个指针代替。所以基本可以等价认为,字符串常量(字面量)是const char *类型。
但是,更多的场景下,我们都会使用std::string类型来保存和处理字符串,因为它功能更强大,使用更方便。得益于隐式构造,我们可以把一个字符串常量轻松转化为std::string类型来处理。
但本质上来说,std::string和const char *是两种类型,所以一些场景下它还是会出问题。
在进行类型推导时,字符串常量会按const char *来处理,有时会导致问题,比如:
template <typename T>
void f(T t) {
std::cout << 1 << std::endl;
}
template <typename T>
void f(T *t) {
std::cout << 2 << std::endl;
}
void Demo() {
f("123");
f(std::string{"123"});
}代码的原意是将“值类型”和“指针类型”分开处理,至于字符串,照理说应当是一个“对象”,所以要按照值类型来处理。但如果我们用的是字符串常量,则会识别为const char *类型,直接匹配到了指针处理方式,而并不会触发隐式构造。
C 风格字符串有一个约定,就是以 0 结尾。它并不会去单独存储数据长度,而是很暴力地从首地址向后查找,找到 0 为止。但std::string不同,其内部有统计个数的成员,因此不会受 0 值得影响:
std::string str1{"123\0abc"}; // 0处会截断
std::string str2{"123\0abc", 7}; // 不会截断截断问题在传参时更加明显,比如说:
void f(const char *str) {}
void Demo() {
std::string str2{"123\0abc", 7};
// 由于f只支持C风格字符串,因此转化后传入
f(str2.c_str()); // 但其实已经被截断了
}前面的章节曾经提到过,C++没有引入额外的格式符,因此把std::string传入格式化函数的时候,也容易发生截断问题:
std::string MakeDesc(const std::string &head, double data) {
// 拼凑一个xxx:ff%的形式
char buf[128];
std::sprintf(buf, "%s:%lf%%", head.c_str(), data); // 这里有可能截断
return buf; // 这里也有可能截断
}总之,C 风格的字符串永远难逃 0 值截断问题,而又因为 C++中仍然保留了 C 风格字符串的所有行为,并没有在语言层面直接关联std::string,因此在使用时一定要小心截断问题。
由于 C++保留了 C 风格字符串的行为,因此在很多场景下,把const char *就默认为了字符串,都会按照字符串去解析。但有时可能会遇到一个真正的指针,那么此时就会有问题,比如说:
void Demo() {
int a;
char b;
std::cout << &a << std::endl; // 流接受指针,打印指针的值
std::cout << &b << std::endl; // 流接收char *,按字符串处理
}STL 中所有流接收到char *或const char *时,并不会按指针来解析,而是按照字符串解析。在上面例子中,&b本身应当就是个单纯指针,但是输出流却将其按照字符串处理了,也就是会持续向后搜索找到 0 值为止,那这里显然是发生越界了。
因此,如果我们给char、signed char、unsigned char类型取地址时,一定要考虑会不会被识别为字符串。
原本int8_t和uint8_t是用来表示“8 位整数”的,但是不巧的是,他们的定义是:
using int8_t = signed char;
using uint8_t = unsigned char;由于 C 语言历史原因,ASCII 码只有 7 位,所以“字符”类型有无符号是没区别的,而当时没有定制规范,因此不同编译器可能有不同处理。到后来干脆把char当做独立类型了。所以char和signed char以及unsigned char是不同类型。这与其他类型不同,例如int和signed int是同一类型。
但是类似于流的处理中,却没有把signed char和unsigned char单独拿出来处理,都是按照字符来处理了(这里笔者也不知道什么原因)。而int8_t和uint8_t又是基于此定义的,所以也会出现奇怪问题,比如:
uint8_t n = 56; // 这里是单纯想放一个整数
std::cout << n << std::endl; // 但这里会打印出8,而不是56原本uint8_t是想屏蔽掉char这层含义,让它单纯地表示 8 位整数的,但是在 STL 的解析中,却又让它有了“字符”的含义,去按照 ASCII 码来解析了,让uint8_t的定义又失去了原本该有的含义,所以这里也是很容易踩坑的地方。
(这一点笔者真的没想明白为什么,明明是不同类型,但为什么没有区分开。可能同样是历史原因吧,总之这个点可以算得上真正意义上的“缺陷”了。)
new这个运算符相信大家一定不陌生,即便是非 C++系其他语言一般都会保留new这个关键字。而且这个已经成为业界的一个哏了,比如说“没有对象怎么办?不怕,new 一个!”
从字面意思就能看得出,这是“新建”的意思,不过在 C++中,new远不止字面看上去这么简单。而且,delete关键字基本算得上是 C++的特色了,其他语言中基本见不到。
“堆空间”的概念同样继承自 C 语言,它是提供给程序手动管理、调用的内存空间。在 C 语言中,malloc用于分配堆空间,free用于回收。自然,在 C++中仍然可以用malloc和free
但使用malloc有一个不方便的地方,我们来看一下malloc的函数原型:
void *malloc(size_t size);
malloc接收的是字节数,也就是我们需要手动计算出我们需要的空间是多少字节。它不能方便地通过某种类型直接算出空间,通常需要sizeof运算。malloc返回值是void *类型,是一个泛型指针,也就是没有指定默认解类型的,使用时通常需要类型转换,例如:
int *data = (int *)malloc(sizeof(int));
而new运算符可以完美解决上面的问题,注意,在 C++中new是一个运算符:
int *data = new int;
同理,delete也是一个运算符,用于释放空间:
delete data;
熟悉 C++运算符重载的读者一定清楚,C++中运算符的本质其实就是一个函数的语法糖,例如a + b实际上就是operator +(a, b),a++实际上就是a.operator++(),甚至仿函数、下标运算也都是函数调用,比如f()就是f.operator()(),a[i]就是a.operator[](i)。
既然new和delete也是运算符,那么它就应当也符合这个原理,一定有一个operator new的函数存在,下面是它的函数原型:
void *operator new(size_t size);
void *operator new(size_t size, void *ptr);这个跟我们直观想象可能有点不一样,它的返回值仍然是void *,也并不是一个模板函数用来判断大小。所以,new运算符跟其他运算符并不一样,它并不只是单纯映射成operator new,而是做了一些额外操作。
另外,这个拥有 2 个参数的重载又是怎么回事呢?这个等一会再来解释。
系统内置的operator new本质上就是malloc,所以如果我们直接调operator new和operator delete的话,本质上来说,和malloc和free其实没什么区别:
int *data = static_cast<int *>(operator new(sizeof(int)));
operator delete(data);而当我们用运算符的形式来书写时,编译器会自动处理类型的大小,以及返回值。new运算符必须作用于一个类型,编译器会将这个类型的 size 作为参数传给operator new,并把返回值转换为这个类型的指针,也就是说:
new T;
// 等价于
static_cast<T *>(operator new(sizeof(T)))delete运算符要作用于一个指针,编译器会将这个指针作为参数传给operator delete,也就是说:
delete ptr;
// 等价于
operator delete(ptr);之所以要引入operator new和operator delete还有一个原因,就是可以重载。默认情况下,它们操作的是堆空间,但是我们也可以通过重载来使得其操作自己的内存池。
std::byte buffer[16][64]; // 一个手动的内存池
std::array<void *, 16> buf_mark {nullptr}; // 统计已经使用的内存池单元
struct Test {
int a, b;
static void *operator new(size_t size) noexcept; // 重载operator new
static void operator delete(void *ptr); // 重载operator delete
};
void *Test::operator new(size_t size) noexcept {
// 从buffer中分配资源
for (int i = 0; i < 16; i++) {
if (buf_mark.at(i) == nullptr) {
buf_mark.at(i) = buffer[i];
return buffer[i];
}
}
return nullptr;
}
void Test::operator delete(void *ptr) {
for (int i = 0; i < 16; i++) {
if (buf_mark.at(i) == ptr) {
buf_mark.at(i) = nullptr;
}
}
}
void Demo() {
Test *t1 = new Test; // 会在buffer中分配
delete t1; // 释放buffer中的资源
}另一个点,相信大家已经发现了,operator new和operator delete是支持异常抛出的,而我们这里引用直接用空指针来表示分配失败的情况了,于是加上了noexcept修饰。而默认的情况下,可以通过接收异常来判断是否分配成功,而不用每次都对指针进行判空。
malloc的另一个问题就是处理非平凡构造的类类型。当一个类是非平凡构造时,它可能含有虚函数表、虚基表,还有可能含有一些额外的构造动作(比如说分配空间等等),我们拿一个最简单的字符串处理类为例:
class String {
public:
String(const char *str);
~String();
private:
char *buf;
size_t size;
size_t capicity;
};
String::String(const char *str):
buf((char *)std::malloc(std::strlen(str) + 1)),
size(std::strlen(str)),
capicity(std::strlen(str) + 1) {
std::memcpy(buf, str, capicity);
}
String::~String() {
if (buf != nullptr) {
std::free(buf);
}
}
void Demo() {
String *str = (String *)std::malloc(sizeof(String));
// 再使用str一定是有问题的,因为没有正常构造
}上面例子中,String就是一个非平凡的类型,它在构造函数中创建了堆空间。如果我们直接通过malloc分配一片String大小的空间,然后就直接用的话,显然是会出问题的,因为构造函数没有执行,其中buf管理的堆空间也是没有进行分配的。 所以,在 C++中,创建一个对象应该分 2 步:
同样,释放一个对象也应该分 2 步:
3 . 调用析构函数
4 . 释放内存空间
这个理念在 OC 语言中贯彻得非常彻底,OC 中没有默认的构造函数,都是通过实现一个类方法来进行构造的,因此构造前要先分配空间:
NSString *str = [NSString alloc]; // 分配NSString大小的内存空间
[str init]; // 调用初始化函数
// 通常简写为:
NSString *str = [[NSString alloc] init];但是在 C++中,初始化方法并不是一个普通的类方法,而是特殊的构造函数,那如何手动调用构造函数呢?
我们知道,要想调用构造函数(构造一个对象),我们首先需要一个分配好的内存空间。因此,要拿着用于构造的内存空间,以构造参数,才能构造一个对象(也就是调用构造函数)。C++管这种语法叫做就地构造(placement new)。
String *str = static_cast<String *>(std::malloc(sizeof(String))); // 分配内存空间
new(str) String("abc"); // 在str指向的位置调用String的构造函数就地构造的语法就是new(addr) T(args...),看得出,这也是new运算符的一种。这时我们再回去看operator new的一个重载,应该就能猜到它是干什么的了:
void *operator new(size_t size, void *ptr);
就是用于支持就地构造的函数。 要注意的是,如果是通过就地构造方式构造的对象,需要再回收内存空间之前进行析构。以上面String为例,如果不析构直接回收,那么buf所指的空间就不能得到释放,从而造成内存泄漏:
str->~String(); // 析构
std::free(str); // 释放内存空间看到本节的标题,相信读者会恍然大悟。C++中new运算符同时承担了“分配空间”和“构造对象”的任务。上一节的例子中我们是通过malloc和free来管理的,自然,通过operator new和operator delete也是一样的,而且它们还支持针对类型的重载。
因此,我们说,一次new,相当于先operator new(分配空间)加placement new(调用构造函数)。
String *str = new String("abc");
// 等价于
String *str = static_cast<String *>(operator new(sizeof(String)));
new(str) String("abc");同理,一次delete相当于先“析构”,再operator delete(释放空间)
delete str;
// 等价于
str->~String();
operator delete(str);这就是new和delete的神秘面纱,它确实和普通的运算符不一样,除了对应的operator函数外,还有对构造、析构的处理。 但也正是由于 C++总是进行一些隐藏操作,才会复杂度激增,有时也会出现一些难以发现的问题,所以我们一定要弄清楚它的本质。
new []和delete []的语法看起来是“创建/删除数组”的语法。但其实它们也并不特殊,就是封装了一层的new和delete
void *operator new[](size_t size);
void operator delete[](void *ptr);可以看出,operator new[]和operator new完全一样,opeator delete[]和operator delete也完全一样,所以区别应当在编译器的解释上。operator new T[size]的时候,会计算出size个T类型的总大小,然后调用operator new[],之后,会依次对每个元素进行构造。也就是说:
String *arr_str = new String [4] {"abc", "def", "123"};
// 等价于
String *arr_str = static_cast<String *>(opeartor new[](sizeof(String) * 3));
new(arr_str) String("abc");
new(arr_str + 1) String("def");
new(arr_str + 2) String("123");
new(arr_str + 3) String; // 没有写在列表中的会用无参构造函数同理,delete []会首先依次调用析构,然后再调用operator delete []来释放空间:
delete [] arr_str;
// 等价于
for (int i = 0; i < 4; i++) {
arr_str[i].~String();
}
operator delete[] (arr_str);总结下来new []相当于一次内存分配加多次就地构造,delete []运算符相当于多次析构加一次内存释放。
constexpr全程叫“常量表达式(constant expression)”,顾名思义,将一个表达式定义为“常量”。
关于“常量”的概念笔者在前面“const 引用”的章节已经详细叙述过,只有像1,'a',2.5f之类的才是真正的常量。储存在内存中的数据都应当叫做“变量”。
但很多时候我们在程序编写的时候,会遇到一些编译期就能确定的量,但不方便直接用常量表达的情况。最简单的一个例子就是“魔鬼数字”:
using err_t = int;
err_t Process() {
// 某些错误
return 25;
// ...
return 0;
}作为错误码的时候,我们只能知道业界约定0表示成功,但其他的错误码就不知道什么含义了,比如这里的25号错误码,非常突兀,根本不知道它是什么含义。
C 中的解决的办法就是定义宏,又有宏是预编译期进行替换的,因此它在编译的时候一定是作为常量存在的,我们又可以通过宏名称来增加可读性:
#define ERR_DATA_NOT_FOUNT 25
#define SUCC 0
using err_t = int;
err_t Process() {
// 某些错误
return ERR_DATA_NOT_FOUNT;
// ...
return SUCC;
}(对于错误码的场景当然还可以用枚举来实现,这里就不再赘述了。)
用宏虽然可以解决魔数问题,但是宏本身是不推荐使用的,详情大家可以参考前面“宏”的章节,里面介绍了很多宏滥用的情况。
不过最主要的一点就是宏不是类型安全的。我们既希望定义一个类型安全的数据,又不希望这个数据成为“变量”来占用内存空间。这时,就可以使用 C++11 引入的constexpr概念。
constexpr double pi = 3.141592654;
double Squ(double r) {
return pi * r * r;
}这里的pi虽然是double类型的,类型安全,但因为用constexpr修饰了,因此它会在编译期间成为“常量”,而不会占用内存空间。
用constexpr修饰的表达式,会保留其原有的作用域和类型(例如上面的pi就跟全局变量的作用域是一样的),只是会变成编译期常量。
既然constexpr叫“常量表达式”,那么也就是说有一些编译期参数只能用常量,用constexpr修饰的表达式也可以充当。
举例来说,模板参数必须是一个编译期确定的量,那么除了常量外,constexpr修饰的表达式也可以:
template <int N>
struct Array {
int data[N];
};
constexpr int default_size = 16;
const int g_size = 8;
void Demo() {
Array<8> a1; // 常量OK
Array<default_size> a2; // 常量表达式OK
Array<g_size> a3; // ERR,非常量不可以,只读变量不是常量
}至于其他类型的表达式,也支持constexpr,原则在于它必须要是编译期可以确定的类型,比如说 POD 类型:
constexpr int arr[] {1, 2, 3};
constexpr std::array<int> arr2 {1, 2, 3};
void f() {}
constexpr void (*fp)() = f;
constexpr const char *str = "abc123";
int g_val = 5;
constexpr int *pg = &g_val;这里可能有一些和直觉不太一样的地方,我来解释一下。首先,数组类型是编译期可确定的(你可以单纯理解为一组数,使用时按对应位置替换为值,并不会真的分配空间)。
std::array是 POD 类型,那么就跟普通的结构体、数组一样,所以都可以作为编译期常量。
后面几个指针需要重点解释一下。用constexpr修饰的除了可以是绝对的常量外,在编译期能确定的量也可以视为常量。比如这里的fp,由于函数f的地址,在运行期间是不会改变的,编译期间尽管不能确定其绝对地址,但可以确定它的相对地址,那么作为函数指针fp,它就是f将要保存的地址,所以,这就是编译期可以确定的量,也可用constexpr修饰。
同理,str指向的是一个字符串常量,字符串常量同样是有一个固定存放地址的,位置不会改变,所以用于指向这个数据的指针str也可以用constexpr修饰。要注意的是:constexpr表达式有固定的书写位置,与const的位置不一定相同。比如说这里如果定义只读变量应该是const char *const str,后面的const修饰str,前面的const修饰char。但换成常量表达式时,constexpr要放在最前,因此不能写成const char *constexpr str,而是要写成constexpr const char *str。当然,少了这个const也是不对的,因为不仅是指针不可变,指针所指数据也不可变。这个也是 C++中推荐的定义字符串常量别名的方式,优于宏定义。
最后的这个pg也是一样的道理,因为全局变量的地址也是固定的,运行期间不会改变,因此pg也可以用常量表达式。
当然,如果运行期间可能发生改变的量(也就是编译期间不能确定的量)就不可以用常量表达式,例如:
void Demo() {
int a;
constexpr int *p = &a; // ERR,局部变量地址编译期间不能确定
static int b;
constexpr int *p2 = &b; // OK,静态变量地址可以确定
constexpr std::string str = "abc"; // ERR,非平凡POD类型不能编译期确定内部行为
}希望读者看到这一节标题的时候不要崩溃,C++就是这么难以捉摸。
没错,虽然constexpr已经是常量表达式了,但是用constexpr修饰变量的时候,它仍然是“定义变量”的语法,因此 C++希望它能够兼容只读变量的情况。
当且仅当一种情况下,constexpr定义的变量会真的成为变量,那就是这个变量被取址的时候:
void Demo() {
constexpr int a = 5;
const int *p = &a; // 会让a退化为const int类型
}道理也很简单,因为只有变量才能取址。上面例子中,由于对a进行了取地址操作,因此,a不得不真正成为一个变量,也就是变为const int类型。
那另一个问题就出现了,如果说,我对一个常量表达式既取了地址,又用到编译期语法中了怎么办?
template <int N>
struct Test {};
void Demo() {
constexpr int a = 5;
Test<a> t; // 用做常量
const int *p = &a; // 用做变量
}没关系,编译器会让它在编译期视为常量去给那些编译期语法(比如模板实例化)使用,之后,再把它用作变量写到内存中。
换句话说,在编译期,这里的a相当于一个宏,所有的编译期语法会用5替换a,Test<a>就变成了Test<5>。之后,又会让a成为一个只读变量写到内存中,也就变成了const int a = 5;那么const int *p = &a;自然就是合法的了。
“就地构造”这个词本身就很 C++。很多程序员都能发现,到处纠结对象有没有拷贝,纠结出参还是返回值的只有 C++程序员。
无奈,C++确实没法完全摆脱底层考虑,C++程序员也会更倾向于高性能代码的编写。当出现嵌套结构的时候,就会考虑复制问题了。 举个最简单的例子,给一个vector进行push_back操作时,会发生一次复制:
struct Test {
int a, b;
};
void Demo() {
std::vector<Test> ve;
ve.push_back(Test{1, 2}); // 用1,2构造临时对象,再移动构造
}原因就在于,push_back的原型是:
template <typename T>
void vector<T>::push_back(const T &);
template <typename T>
void vector<T>::push_back(T &&);如果传入左值,则会进行拷贝构造,传入右值会移动构造。但是对于Test来说,无论深浅复制,都是相同的复制。这多构造一次Test临时对象本身就是多余的。
既然,我们已经有{1, 2}的构造参数了,能否想办法跳过这一次临时对象,而是直接在vector末尾的空间上进行构造呢?这就涉及了就地构造的问题。我们在前面“new 和 delete”的章节介绍过,“分配空间”和“构造对象”的步骤可以拆解开来做。首先对vector的buffer进行扩容(如果需要的话),确定了要放置新对象的空间以后,直接使用placement new进行就地构造。
比如针对Test的vector我们可以这样写:
template <>
void vector<Test>::emplace_back(int a, int b) {
// 需要时扩容
// new_ptr表示末尾为新对象分配的空间
new(new_ptr) Test{a, b};
}STL 中把容器的就地构造方法叫做emplace,原理就是通过传递构造参数,直接在对应位置就地构造。所以更加通用的方法应该是:
template <typename T, typename... Args>
void vector<T>::emplace_back(Args &&...args) {
// new_ptr表示末尾为新对象分配的空间
new(new_ptr) T{std::forward<Args>(args)...};
}就地构造确实能在一定程度上解决多余的对象复制问题,但如果是嵌套形式就实则没办法了,举例来说:
struct Test {
int a, b;
};
void Demo() {
std::vector<std::tuple<int, Test>> ve;
ve.emplace_back(1, Test{1, 2}); // tuple嵌套的Test没法就地构造
}也就是说,我们没法在就地构造对象时对参数再就地构造。
这件事情放在map或者unordered_map上更加有趣,因为这两个容器的成员都是std::pair,所以对它进行emplace的时候,就地构造的是pair而不是内部的对象:
struct Test {
int a, b;
};
void Demo() {
std::map<int, Test> ma;
ma.emplace(1, Test{1, 2}); // 这里emplace的对象是pair<int, Test>
}不过好在,map和unordered_map提供了try_emplace方法,可以在一定程度上解决这个问题,函数原型是:
template <typename K, typename V, typename... Args>
std::pair<iterator, bool> map<K, V>::try_emplace(const K &key, Args &&...args);这里把key和value拆开了,前者还是只能通过复制的方式传递,但后者可以就地构造。(实际使用时,value更需要就地构造,一般来说key都是整数、字符串这些。)那么我们可用它代替emplace:
void Demo() {
std::map<int, Test> ma;
ma.try_emplace(1, 1, 2); // 1, 2用于构造Test
}但看这个函数名也能猜到,它是“不覆盖逻辑”。也就是如果容器中已有对应的key,则不会覆盖。返回值中第一项表示对应项迭代器(如果是新增,就返回新增这一条的迭代器,如果是已有key则放弃新增,并返回原项的迭代器),第二项表示是否成功新增(如果已有key会返回false)。
void Demo() {
std::map<int, Test> ma {{1, Test{1, 2}}};
auto [iter, is_insert] = ma.try_emplace(1, 7, 8);
auto ¤t_test = iter->second;
std::cout << current_test.a << ", " << current_test.b << std::endl; // 会打印1, 2
}不过有一些场景利用try_emplace会很方便,比如处理多重key时使用map嵌套map的场景,如果用emplace要写成:
void Demo() {
std::map<int, std::map<int, std::string>> ma;
// 例如想给key为(1, 2)新增value为"abc"的
// 由于无法确定外层key为1是否已经有了,所以要单独判断
if (ma.count(1) == 0) {
ma.emplace(1, std::map<int, std::string>{});
}
ma.at(1).emplace(1, "abc");
}但是利用try_emplace就可以更取巧一些:
void Demo() {
std::map<int, std::map<int, std::string>> ma;
ma.try_emplace(1).first->second.try_emplace(1, "abc");
}解释一下,如果ma含有key为1的项,就返回对应迭代器,如果没有的话则会新增(由于没指定后面的参数,所以会构造一个空map),并返回迭代器。迭代器在返回值的第一项,所以取first得到迭代器,迭代器指向的是map内部的pair,取second得到内部的map,再对其进行一次try_emplace插入内部的元素。
当然了,这么做确实可读性会下降很多,具体使用时还需要自行取舍。
曾经有很多朋友问过我,C++适不适合入门?C++适不适合干活?我学 C++跟我学 java 哪个更赚钱啊?
笔者持有这样的观点:C++并不是最适合生产的语言,但 C++一定是最值得学习的语言。
如果说你单纯就是想干活,享受产出的快乐,那我不建议你学 C++,因为太容易劝退,找一些新语言,语法简单清晰容易上手,自然干活效率会高很多;但如果你希望更多地理解编程语言,全面了解一些自底层到上层的原理和进程,希望享受研究和开悟的快乐,那非 C++莫属了。掌握了 C++再去看其他语言,相信你一定会有不同的见解的。
所以到现在这个时间点,应该说,C++仍然还是我的信仰,我认为 C++将会在将来很长一段时间存在,并且以一个长老的身份发挥其在业界的作用和价值,但同时也会有越来越多新语言的诞生,他们在自己适合的地方发挥着不一样的光彩。我也不再会否认 C++的确有设计不合理的地方,不会否认其存在不擅长的领域,也不会再去鄙视那些吐槽 C++复杂的人。与此同时,我也不会拒绝涉足其他的领域,我认为,只有不断学习比较,不断总结沉淀,才能持续进步。
如果你能读到这里的话,那非常感激你的支持,听我说谢谢你,因为有你……咳咳~。这篇文章作为我学习 C++多年的一个沉淀,也希望借此把我的想法分享给读者,如果你有任何疑问或者建议,欢迎评论区留言!针对更多 C++的特性的用法、编程技巧等内容,请期待我其他系列的文章。
本文由哈喽比特于3年以前收录,如有侵权请联系我们。
文章来源:https://mp.weixin.qq.com/s/Isr5-FojMTRK36g-Gh2_yQ
京东创始人刘强东和其妻子章泽天最近成为了互联网舆论关注的焦点。有关他们“移民美国”和在美国购买豪宅的传言在互联网上广泛传播。然而,京东官方通过微博发言人发布的消息澄清了这些传言,称这些言论纯属虚假信息和蓄意捏造。
日前,据博主“@超能数码君老周”爆料,国内三大运营商中国移动、中国电信和中国联通预计将集体采购百万台规模的华为Mate60系列手机。
据报道,荷兰半导体设备公司ASML正看到美国对华遏制政策的负面影响。阿斯麦(ASML)CEO彼得·温宁克在一档电视节目中分享了他对中国大陆问题以及该公司面临的出口管制和保护主义的看法。彼得曾在多个场合表达了他对出口管制以及中荷经济关系的担忧。
今年早些时候,抖音悄然上线了一款名为“青桃”的 App,Slogan 为“看见你的热爱”,根据应用介绍可知,“青桃”是一个属于年轻人的兴趣知识视频平台,由抖音官方出品的中长视频关联版本,整体风格有些类似B站。
日前,威马汽车首席数据官梅松林转发了一份“世界各国地区拥车率排行榜”,同时,他发文表示:中国汽车普及率低于非洲国家尼日利亚,每百户家庭仅17户有车。意大利世界排名第一,每十户中九户有车。
近日,一项新的研究发现,维生素 C 和 E 等抗氧化剂会激活一种机制,刺激癌症肿瘤中新血管的生长,帮助它们生长和扩散。
据媒体援引消息人士报道,苹果公司正在测试使用3D打印技术来生产其智能手表的钢质底盘。消息传出后,3D系统一度大涨超10%,不过截至周三收盘,该股涨幅回落至2%以内。
9月2日,坐拥千万粉丝的网红主播“秀才”账号被封禁,在社交媒体平台上引发热议。平台相关负责人表示,“秀才”账号违反平台相关规定,已封禁。据知情人士透露,秀才近期被举报存在违法行为,这可能是他被封禁的部分原因。据悉,“秀才”年龄39岁,是安徽省亳州市蒙城县人,抖音网红,粉丝数量超1200万。他曾被称为“中老年...
9月3日消息,亚马逊的一些股东,包括持有该公司股票的一家养老基金,日前对亚马逊、其创始人贝索斯和其董事会提起诉讼,指控他们在为 Project Kuiper 卫星星座项目购买发射服务时“违反了信义义务”。
据消息,为推广自家应用,苹果现推出了一个名为“Apps by Apple”的网站,展示了苹果为旗下产品(如 iPhone、iPad、Apple Watch、Mac 和 Apple TV)开发的各种应用程序。
特斯拉本周在美国大幅下调Model S和X售价,引发了该公司一些最坚定支持者的不满。知名特斯拉多头、未来基金(Future Fund)管理合伙人加里·布莱克发帖称,降价是一种“短期麻醉剂”,会让潜在客户等待进一步降价。
据外媒9月2日报道,荷兰半导体设备制造商阿斯麦称,尽管荷兰政府颁布的半导体设备出口管制新规9月正式生效,但该公司已获得在2023年底以前向中国运送受限制芯片制造机器的许可。
近日,根据美国证券交易委员会的文件显示,苹果卫星服务提供商 Globalstar 近期向马斯克旗下的 SpaceX 支付 6400 万美元(约 4.65 亿元人民币)。用于在 2023-2025 年期间,发射卫星,进一步扩展苹果 iPhone 系列的 SOS 卫星服务。
据报道,马斯克旗下社交平台𝕏(推特)日前调整了隐私政策,允许 𝕏 使用用户发布的信息来训练其人工智能(AI)模型。新的隐私政策将于 9 月 29 日生效。新政策规定,𝕏可能会使用所收集到的平台信息和公开可用的信息,来帮助训练 𝕏 的机器学习或人工智能模型。
9月2日,荣耀CEO赵明在采访中谈及华为手机回归时表示,替老同事们高兴,觉得手机行业,由于华为的回归,让竞争充满了更多的可能性和更多的魅力,对行业来说也是件好事。
《自然》30日发表的一篇论文报道了一个名为Swift的人工智能(AI)系统,该系统驾驶无人机的能力可在真实世界中一对一冠军赛里战胜人类对手。
近日,非营利组织纽约真菌学会(NYMS)发出警告,表示亚马逊为代表的电商平台上,充斥着各种AI生成的蘑菇觅食科普书籍,其中存在诸多错误。
社交媒体平台𝕏(原推特)新隐私政策提到:“在您同意的情况下,我们可能出于安全、安保和身份识别目的收集和使用您的生物识别信息。”
2023年德国柏林消费电子展上,各大企业都带来了最新的理念和产品,而高端化、本土化的中国产品正在不断吸引欧洲等国际市场的目光。
罗永浩日前在直播中吐槽苹果即将推出的 iPhone 新品,具体内容为:“以我对我‘子公司’的了解,我认为 iPhone 15 跟 iPhone 14 不会有什么区别的,除了序(列)号变了,这个‘不要脸’的东西,这个‘臭厨子’。