引言
过程概述
网卡启动
硬中断
软中断
NAPI关闭条件
igb_poll
igb_clean_rx_irq
napi_gro_receive
netif_receive_skb
__netif_receive_skb
TC
ip_rcv
ip_rcv_finish
ip_local_deliver
ip_local_deliver_finish
udp_rcv
udp_queue_rcv_skb
对于内核网络栈的分析我在大二听了李勇大神来小组的讲座以后就想干了,但像很多主题的文章一样,始终没有勇气,也没有时间动手,我终究还是把这个话题从大二延到大三,从大三延到大四了。冥冥之中某种东西好像早已是安排好的,毕设本来老陈要求的的是自由发挥,我抱着对数据库的兴趣发掘出一个协议栈前加速内存数据库的题目,想着在XDP和TC加点勾子就收工的题目却因为TCP有状态导致XDP的勾子变得异常复杂,如何破局?
看似不相关的两条暗线霎时间交叉在一起,其实不单单是暗线,从二月二十八号从深圳到西安,三月一号到宝鸡算起(十四天的居家隔离和隔离期间的疫情导致的小区封禁),我的隔离生活已经十六天了(我写到这里时,而不是文章发出时),大段的空闲时间的确是很适合做一些艰苦的东西,看起来我要写这篇文章是老天早早就敲定的了。
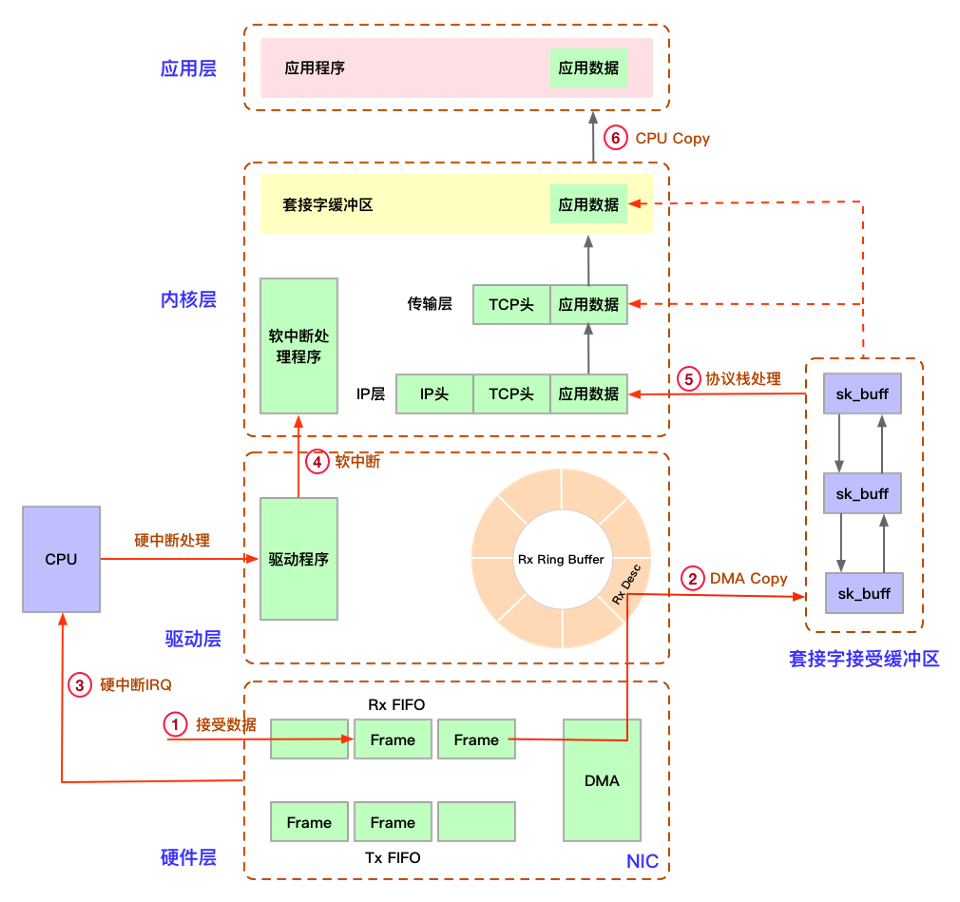
网络栈不单单指协议栈,在这篇文章中我想展示的是一个数据包从网卡到套接字的全过程,从DMA数据拷贝,硬中断开始,到网卡驱动,GRO,TC,Netfilter,网络层,传输层,Socket的全链路分析。分析的过程没有意义,有意义的是这个链路对我们有什么帮助,哪些地方可能丢包,哪些地方执行Netfilter,哪些地方可以挂BPF程序,哪些参数可以进行调优等等。
至少未来两年内(可能三年以后就送外卖了,个体太过渺小,以我现在的功力能预测技术的发展已经很难,更不必说行业了)我给自己的定位是一个分布式数据库研发工程师,就现在看来分布式理论,Linux内核,容器,K8S,数据库领域都需要懂,熟练其一,了解其他,也就是现阶段的目标了。
本文基于内核3.13,驱动采用 igb 作为参考来熟悉流程[1]。
Linux网络栈接收数据包的过程大概可分为以下步骤:
对于RSS/多队列,通过对packet头(五元组,可修改)做哈希选择对应的RX
如果RX 队列有足够的帧,包会通过 DMA 写入到内存中
触发配置的硬中断处理函数,将 napi_struct 放入到 perCPU 的 softnet_data,其中唤醒软中断处理函数执行NAPI处理循环
在 net_rx_action 中 循环调用 poll(igb poll) 接口,读取ring中的数据,然后封装成一个skb,软中断的终止逻辑较为复杂,正文再说
GRO,通过合并的包来减少传送给协议栈的包数量
RPS,软件实现的RSS,把数据包发送到其他CPU的backlog,随后在软中断中处理(process_backlog 注册到poll上),这里backlog有限制,可能造成数据包drop
receive_skb_core 最终将数据送入协议栈
TC 流量控制子系统 ingress
ip_rcv,执行一些数据合法性验证,统计计数器更新
netfilter(PRE_ROUTING)
ip_rcv_finish,其中对路由子系统的dst_entry进行赋值,决定包应该被转发还是到本地协议栈
dst_input 会调用 dst_entry 变量中的input接口,如果包是本地包,则接口是 ip_local_deliver,否则是 ip_forward,其中调用netfilter(FORWARD)
ip_local_deliver 中先调用 ip_defrag 使得IP分片重组,然后调用netfilter(INPUT)
ip_local_deliver_finish 通过数据包中的协议调用相关的勾子
本篇文章在传输层以UDP协议为例子,上面指的勾子就是 udp_rcv,查找此数据包对应的socket(UDP和TCP通过skb_buff获取socket的过程是不一样的,UDP通过目的端口和目的地址做哈希,在 udp_hslot 结构中查找,而TCP是LHTABLE),关联调用 udp_queue_rcv_skb,中间会判断队列是否满,是否有系统调用,最后调用 sock_queue_rcv_skb 把数据包送向套接字缓冲区
用户态如果正在等待这个事件,那就会被通知,至于手段是select,poll,epoll,io_uring就无所谓了
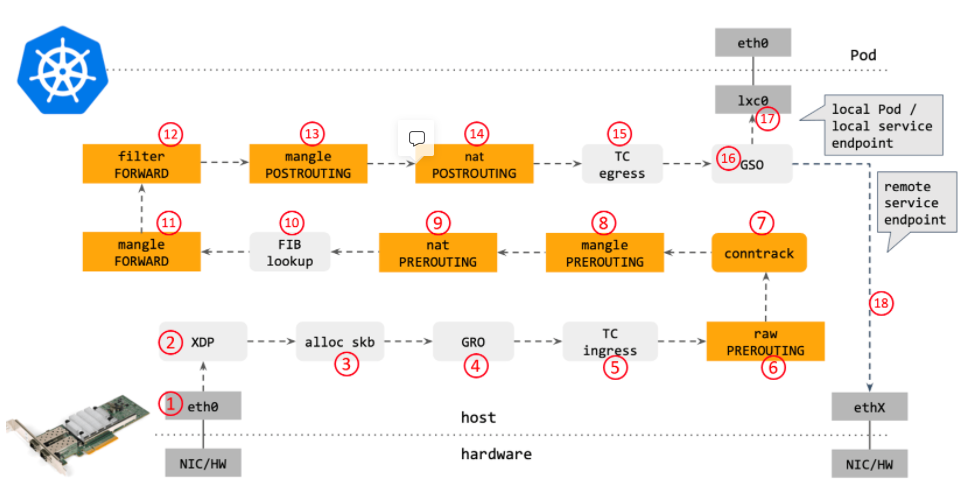
对整个链路有了了解以后我们再来看看 kube-proxy 数据包转发的流程,就有了不一样的理解:
配合这张图食用更佳[2],步骤一到四对应了上图中步骤一:
协议层我们以UDP和IP为例子,接下来我们更加详细的过一遍上述流程,作者水平有限,难免出现错误,对于稳重内容有异议的同学可以在评论区提出。
我们假设驱动已经被载入了,网卡已经启动,也就意味着 ethtool 相关的方法被注册,默认 MAC 地址也被获取,软中断,硬中断已经被获取,
这里我比较感兴趣的是网络设备子系统的初始化,具体的函数是net_dev_init:
在proc文件系统上创建此设备相关的目录,调用 dev_proc_init
在sys目录下创建此网络设备的目录,调用 netdev_kobject_init
为每个CPU创建一个 softnet_data 变量,这是一个收包过程的一个核心结构,包含着很多重要信息:
per CPU 的 NAPI 变量列表 napi_struct
正常应该接收的网络数据 softnet_data
权重相关
RPS相关结构 input_pkt_queue,存储其他CPU传输到本CPU处理的数据包
注册TX和RX的软中断处理函数 net_tx_action
如果 RX 队列空间足够,包会通过 DMA 写到 RX 队列中(RAM),随后发起硬中断。这里中断的方式并不是唯一的,驱动必须判断出设备支持哪种中断方式,然后注册相应的硬中断处理函数。
对于支持多队列的网卡,MSI-X是比较推荐的一种方案,每个 RX 队列都会有独立的 MSI-X 中断,因此可以被不同的 CPU 处理(通过 irqbalance 方式,或者修改 /proc/irq/IRQ_NUMBER/smp_affinity),因为处理中断的 CPU 随后也会处理这个包,所以设置MSI-X可以使得包被不同的CPU处理。更多中断相关的信息可以参考[3]。
igb MSI-X 的驱动函数对应的硬中断处理函数为igb_msix_ring,代码如下:
static irqreturn_t igb_msix_ring(int irq, void *data)
{
struct igb_q_vector *q_vector = data;
/* Write the ITR value calculated from the previous interrupt. */
igb_write_itr(q_vector);
napi_schedule(&q_vector->napi);
return IRQ_HANDLED;
}学过操作系统的都知道因为硬件中断有一些限制使得我们会把更多的任务放在软中断中执行,具体细节可以参考[4][5]。
所以可以看到硬中断的函数体看起来是很简单的,igb_write_itr更新硬件寄存器,统计硬中断的数量;然后调用napi_schedule,如果 NAPI 的处理循环还没开始的话会唤醒 NAPI,当然处理的过程是在软中断中,napi_schedule最终调用__napi_schedule。
void __napi_schedule(struct napi_struct *n)
{
unsigned long flags;
local_irq_save(flags);
// __get_cpu_var 用于获取属于这个 CPU 的 structure softnet_data 变量
____napi_schedule(this_cpu_ptr(&softnet_data), n);
local_irq_restore(flags);
}
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi)
{
list_add_tail(&napi->poll_list, &sd->poll_list);
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
}____napi_schedule做了两件重要的事情:
将(从驱动的中断函数中传来的)napi_struct 变量,添加到 per CPU softnet_data->poll_list上
__raise_softirq_irqoff触发一个 NET_RX_SOFTIRQ 类型软中断。这会触发执行 net_rx_action
软中断
前面提到包是被设备通过 DMA 直接送到内存的,net_rx_action函数遍历本 CPU 队列的 NAPI 变量列表,软中断也不是随意处理的,处理逻辑考虑任务量和执行时间两个因素,这也是概述中我提到这里终止逻辑比较复杂的原因。
// int netdev_budget __read_mostly = 300;
int budget = netdev_budget;
void *have;
local_irq_disable();
while (!list_empty(&sd->poll_list)) {
struct napi_struct *n;
int work, weight;
if (unlikely(budget <= 0 || time_after_eq(jiffies, time_limit)))
goto softnet_break;
local_irq_enable();
n = list_first_entry(&sd->poll_list, struct napi_struct, poll_list);
have = netpoll_poll_lock(n);
weight = n->weight;
work = 0;
if (test_bit(NAPI_STATE_SCHED, &n->state)) {
work = n->poll(n, weight);
trace_napi_poll(n);
}
WARN_ON_ONCE(work > weight);
budget -= work;在网络设备驱动使用 netif_napi_add 注册 igb_poll 方法时有如下代码:
/* initialize NAPI */
netif_napi_add(adapter->netdev, &q_vector->napi, igb_poll, 64);
...
void netif_napi_add(struct net_device *dev, struct napi_struct *napi,
int (*poll)(struct napi_struct *, int), int weight) {
...
napi->weight = weight;
...net_rx_action中的 poll 指向 igb_poll,poll() 返回语意是处理的数据帧数量,igb_poll 中如果还存在work没执行完返回 weight 本身,否则为min(work_done, budget - 1);,netif_napi_add中可以看到weight默认64,也就是说返回值最小63,budget 会减去这个值。
这其实是内核方式数据包的处理太占用CPU的一种限制方案。其次我们需要知道的是一个CPU上一般会绑定一个ksoftirqd,可以执行ps -ef | grep ksoftirqd查看机器上运行的内核软中断处理线程,每个ksoftirqd会处理此线程上的软中断,这也意味着上述代码中的budget budget 是该 CPU 的 所有 NAPI 变量的总预算,这也是多队列网卡应该精心调整 IRQ Affinity 的原因,否则可能出现有的CPU非常忙碌,每次处理budget都消耗完,但有些CPU却非常空闲。
综上,net_rx_action会在下面两个条件时结束数据的处理流程:
NAPI关闭条件
注意,NAPI 存在的意义是无需硬件中断通知就可以接收网络数据。前面提到, NAPI的执行是受硬件中断触发的,也就是说NAPI 功能启用了,但是并没有工作,直到硬件中断去调用软中断。
首先NAPI的工作模式如下:
我们可以看到重要的是第六步其实是比较重要的一步,其需要在包接收完时关闭NAPI,打开硬中断继续接收数据包,判断关闭条件的代码部分是这样的:
if (unlikely(work == weight)) {
if (unlikely(napi_disable_pending(n))) {
local_irq_enable();
napi_complete(n);
local_irq_disable();
} else {
if (n->gro_list) {
local_irq_enable();
napi_gro_flush(n, HZ >= 1000);
local_irq_disable();
}
list_move_tail(&n->poll_list, &sd->poll_list);
}
}这里有两种可能性:
net_rx_action循环调用igb_poll,我们来看看其实现:
static int igb_poll(struct napi_struct *napi, int budget)
{
struct igb_q_vector *q_vector = container_of(napi,
struct igb_q_vector,
napi);
bool clean_complete = true;
#ifdef CONFIG_IGB_DCA
if (q_vector->adapter->flags & IGB_FLAG_DCA_ENABLED)
igb_update_dca(q_vector);
#endif
if (q_vector->tx.ring)
clean_complete = igb_clean_tx_irq(q_vector);
if (q_vector->rx.ring)
clean_complete &= igb_clean_rx_irq(q_vector, budget);
/* If all work not completed, return budget and keep polling */
if (!clean_complete)
return budget;
/* If not enough Rx work done, exit the polling mode */
napi_complete(napi);
igb_ring_irq_enable(q_vector);
return 0;
}非常重要的一个函数,但是同时非常复杂,其基本功能如下:
static bool igb_clean_rx_irq(struct igb_q_vector *q_vector, const int budget)
{
struct igb_ring *rx_ring = q_vector->rx.ring;
struct sk_buff *skb = rx_ring->skb;
unsigned int total_bytes = 0, total_packets = 0;
u16 cleaned_count = igb_desc_unused(rx_ring);
do {
union e1000_adv_rx_desc *rx_desc;
// 1
if (cleaned_count >= IGB_RX_BUFFER_WRITE) {
igb_alloc_rx_buffers(rx_ring, cleaned_count);
cleaned_count = 0;
}
rx_desc = IGB_RX_DESC(rx_ring, rx_ring->next_to_clean);
if (!igb_test_staterr(rx_desc, E1000_RXD_STAT_DD))
break;
rmb();
// 2
skb = igb_fetch_rx_buffer(rx_ring, rx_desc, skb);
/* exit if we failed to retrieve a buffer */
if (!skb)
break;
// ring_buffer中空闲帧增加
cleaned_count++;
// 3
if (igb_is_non_eop(rx_ring, rx_desc))
continue;
// 4
if (igb_cleanup_headers(rx_ring, rx_desc, skb)) {
skb = NULL;
continue;
}
// 5
total_bytes += skb->len;
// 6
igb_process_skb_fields(rx_ring, rx_desc, skb);
// 7
napi_gro_receive(&q_vector->napi, skb);
/* reset skb pointer */
skb = NULL;
/* update budget accounting */
total_packets++;
} while (likely(total_packets < budget));
/* place incomplete frames back on ring for completion */
rx_ring->skb = skb;
u64_stats_update_begin(&rx_ring->rx_syncp);
rx_ring->rx_stats.packets += total_packets;
rx_ring->rx_stats.bytes += total_bytes;
u64_stats_update_end(&rx_ring->rx_syncp);
q_vector->rx.total_packets += total_packets;
q_vector->rx.total_bytes += total_bytes;
if (cleaned_count)
igb_alloc_rx_buffers(rx_ring, cleaned_count);
return (total_packets < budget);
}实际的过程在dev_gro_receive被调用:
static enum gro_result dev_gro_receive(struct napi_struct *napi, struct sk_buff *skb)
{
struct sk_buff **pp = NULL;
struct packet_offload *ptype;
__be16 type = skb->protocol;
struct list_head *head = &offload_base; //packet_offload链表
int same_flow;
enum gro_result ret;
int grow;
if (!(skb->dev->features & NETIF_F_GRO)) //如果设备不支持GRO,则直接提交报文给协议栈处理
goto normal;
if (skb_is_gso(skb) || skb_has_frag_list(skb) || skb->csum_bad) //如果报文是GSO报文,包含frag_list,或csum_bad则提交给协议栈处理
goto normal;
gro_list_prepare(napi, skb); //遍历gro_list中的报文和当前报文是否同流,相同的入口设备、vlan_tci、mac头相同
rcu_read_lock();
list_for_each_entry_rcu(ptype, head, list) { //遍历packet_offload链表,找到和当前协议相同的packet_offload,IP报文为ip_packet_offload
if (ptype->type != type || !ptype->callbacks.gro_receive)
continue;
skb_set_network_header(skb, skb_gro_offset(skb)); //设置network header,驱动调用napi_gro_receive前需要把报文移到network header
skb_reset_mac_len(skb); //设置mac长度
NAPI_GRO_CB(skb)->same_flow = 0;
NAPI_GRO_CB(skb)->flush = 0;
NAPI_GRO_CB(skb)->free = 0;
NAPI_GRO_CB(skb)->udp_mark = 0;
NAPI_GRO_CB(skb)->gro_remcsum_start = 0;
/* Setup for GRO checksum validation */
switch (skb->ip_summed) { //根据ip_summed字段初始化参数
case CHECKSUM_COMPLETE:
NAPI_GRO_CB(skb)->csum = skb->csum;
NAPI_GRO_CB(skb)->csum_valid = 1;
NAPI_GRO_CB(skb)->csum_cnt = 0;
break;
case CHECKSUM_UNNECESSARY:
NAPI_GRO_CB(skb)->csum_cnt = skb->csum_level + 1;
NAPI_GRO_CB(skb)->csum_valid = 0;
break;
default:
NAPI_GRO_CB(skb)->csum_cnt = 0;
NAPI_GRO_CB(skb)->csum_valid = 0;
}
pp = ptype->callbacks.gro_receive(&napi->gro_list, skb); //调用网络层的gro_receive函数处理
break;
}
rcu_read_unlock();
if (&ptype->list == head) //没有匹配到packet_offload对象,则直接提交报文给协议栈
goto normal;
same_flow = NAPI_GRO_CB(skb)->same_flow; //网络层gro_receive处理后,same_flow可能被刷新
ret = NAPI_GRO_CB(skb)->free ? GRO_MERGED_FREE : GRO_MERGED;
if (pp) { //如果pp不为空,说明该报文需要提交给协议栈
struct sk_buff *nskb = *pp;
*pp = nskb->next;
nskb->next = NULL;
napi_gro_complete(nskb); //提交给协议栈
napi->gro_count--;
}
if (same_flow) //如果是相同的流,则返回GRO_MERGED_FREE 或 GRO_MERGED,报文不会被提交给协议栈
goto ok;
if (NAPI_GRO_CB(skb)->flush) //未匹配到流,且flush被置1,则直接提交报文给协议栈
goto normal;
if (unlikely(napi->gro_count >= MAX_GRO_SKBS)) { //gro_list中的报文超过了设定值
struct sk_buff *nskb = napi->gro_list;
/* locate the end of the list to select the 'oldest' flow */
while (nskb->next) {
pp = &nskb->next;
nskb = *pp;
}
*pp = NULL;
nskb->next = NULL;
napi_gro_complete(nskb); //取出最早的报文,提交给协议栈处理
} else {
napi->gro_count++;
}
NAPI_GRO_CB(skb)->count = 1; //未匹配到流,且flush未被置1,则把该报文插入到gro_list中,待以后匹配处理
NAPI_GRO_CB(skb)->age = jiffies;
NAPI_GRO_CB(skb)->last = skb;
skb_shinfo(skb)->gso_size = skb_gro_len(skb);
skb->next = napi->gro_list;
napi->gro_list = skb;
ret = GRO_HELD;
pull:
grow = skb_gro_offset(skb) - skb_headlen(skb);
if (grow > 0) //当前数据偏移如果超过线性区,则需要扩展线性区,线性区长度由驱动保证够用
gro_pull_from_frag0(skb, grow); //扩展报文线性区
ok:
return ret;
normal:
ret = GRO_NORMAL;
goto pull;
}这个数据包有这样几种命运:
可以看到GRO核心处理函数是gro_receive,本篇文章不讨论,有兴趣可参考[6]。
netif_receive_skb
这里处理的复杂性来源于RPS。一些网卡支持多队列,这意味着收进来的包会被通过 DMA 放到位于不同内存的队列上,而不同的队列有相应的 NAPI 变量管理软中断过程,这允许多个 CPU 同时处理从网卡来的数据包,也称为 RSS(Receive Side Scaling)。
RPS (Receive Packet Steering)是 RSS 的一种软件实现,也正因如此,RPS 只能在数据包进入内存以后才可以开始工作,RPS 的工作原理是对个 packet 做 hash,以此觉得要转发多CPU序号,然后 packet 放到每个 CPU 独占的接收后备队列(backlog)等待处理。
int netif_receive_skb(struct sk_buff *skb)
{
net_timestamp_check(netdev_tstamp_prequeue, skb);
if (skb_defer_rx_timestamp(skb))
return NET_RX_SUCCESS;
#ifdef CONFIG_RPS
if (static_key_false(&rps_needed)) {
struct rps_dev_flow voidflow, *rflow = &voidflow;
int cpu, ret;
rcu_read_lock();
// 获取cpu编号
cpu = get_rps_cpu(skb->dev, skb, &rflow);
if (cpu >= 0) {
// 这个 CPU 会向对端 CPU 触发一个进程间中断( IPI,Inter-processor Interrupt)。如果当时对端 CPU 没有在处理 backlog 队列收包,这个进程间会触发它开始从 backlog 收包。
ret = enqueue_to_backlog(skb, cpu, &rflow->last_qtail);
rcu_read_unlock();
return ret;
}
rcu_read_unlock();
}
#endif
return __netif_receive_skb(skb);
}
需要重点讨论的就是enqueue_to_backlog:
// 首先从对端 CPU 的 struct softnet_data 变量获取 backlog queue 长度
qlen = skb_queue_len(&sd->input_pkt_queue);
// 如果 backlog 大于 netdev_max_backlog,或者超过了 flow limit
if (qlen <= netdev_max_backlog && !skb_flow_limit(skb, qlen)) {
// 如果 backlog 非空,那就 enqueue 包
if (skb_queue_len(&sd->input_pkt_queue)) {
enqueue:
__skb_queue_tail(&sd->input_pkt_queue, skb);
input_queue_tail_incr_save(sd, qtail);
rps_unlock(sd);
local_irq_restore(flags);
return NET_RX_SUCCESS;
}
// 如果 backlog 为空,远端 CPU NAPI 变量没有运行,并且 IPI 没有被加到队列,那就 触发一个 IPI 加到队列,然后调用____napi_schedule 进一步处理
if (!__test_and_set_bit(NAPI_STATE_SCHED, &sd->backlog.state)) {
if (!rps_ipi_queued(sd))
____napi_schedule(sd, &sd->backlog);
}
goto enqueue;
}
// 直接 drop,并更新 softnet_data 的 drop 统计
sd->dropped++;
rps_unlock(sd);
local_irq_restore(flags);
atomic_long_inc(&skb->dev->rx_dropped);
kfree_skb(skb);
return NET_RX_DROP;总而言之,经过netif_receive_skb的数据包有两个命运:
这里的数据包也会被加入到对端CPU到NAPI变量中,会在软中断时执行 poll,不过这里的 poll 的实际执行函数是process_backlog。
__netif_receive_skb
主要处理步骤在__netif_receive_skb_core中,这里我们看5.4.119源码,因为这里可以突出TC ingress的勾子
static int __netif_receive_skb_core(struct sk_buff **pskb, bool pfmemalloc,
struct packet_type **ppt_prev) {
...
list_for_each_entry_rcu(ptype, &ptype_all, list) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
...
#ifdef CONFIG_NET_INGRESS
if (static_branch_unlikely(&ingress_needed_key)) {
skb = sch_handle_ingress(skb, &pt_prev, &ret, orig_dev);
if (!skb)
goto out;
if (nf_ingress(skb, &pt_prev, &ret, orig_dev) < 0)
goto out;
}
#endif
...
if (likely(!deliver_exact)) {
deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type,
&ptype_base[ntohs(type) &
PTYPE_HASH_MASK]);
}
...这里ptype_base和ptype_all可以参考[8]。
为了引出下一步,ptype_base是必须的,其结构为哈希表,填充函数为dev_add_pack:
struct list_head ptype_base[PTYPE_HASH_SIZE] __read_mostly;
void dev_add_pack(struct packet_type *pt)
{
struct list_head *head = ptype_head(pt);
spin_lock(&ptype_lock);
list_add_rcu(&pt->list, head);
spin_unlock(&ptype_lock);
}
struct packet_type {
__be16 type; /* This is really htons(ether_type). */
struct net_device *dev; /* NULL is wildcarded here */
int (*func) (struct sk_buff *,
struct net_device *,
struct packet_type *,
struct net_device *);
bool (*id_match)(struct packet_type *ptype,
struct sock *sk);
void *af_packet_priv;
struct list_head list;
};IP的初始化时传入的参数如下:
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
};最终调用deliver_skb,其实也就是上面调用IP注册的钩子,func对应的是ip_rcv。
static inline int deliver_skb(struct sk_buff *skb,
struct packet_type *pt_prev,
struct net_device *orig_dev)
{
if (unlikely(skb_orphan_frags(skb, GFP_ATOMIC)))
return -ENOMEM;
atomic_inc(&skb->users);
return pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
}参考[7],暂时不做源码分析。
到了这里就是网络层的处理了
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev)
{
const struct iphdr *iph;
u32 len;
/* When the interface is in promisc. mode, drop all the crap
* that it receives, do not try to analyse it.
*/
if (skb->pkt_type == PACKET_OTHERHOST) //丢弃掉不是发往本机的报文,网卡开启混杂模式会收到此类报文
goto drop;
IP_UPD_PO_STATS_BH(dev_net(dev), IPSTATS_MIB_IN, skb->len);
skb = skb_share_check(skb, GFP_ATOMIC); //检查是否skb为share,是则克隆报文
if (!skb) {
IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_INDISCARDS);
goto out;
}
if (!pskb_may_pull(skb, sizeof(struct iphdr))) //确保skb还可以容纳标准的报头(即20字节)
goto inhdr_error;
iph = ip_hdr(skb); //得到IP头
/*
* RFC1122: 3.2.1.2 MUST silently discard any IP frame that fails the checksum.
*
* Is the datagram acceptable?
*
* 1. Length at least the size of an ip header
* 2. Version of 4
* 3. Checksums correctly. [Speed optimisation for later, skip loopback checksums]
* 4. Doesn't have a bogus length
*/
if (iph->ihl < 5 || iph->version != 4) //ip头长度至少为20字节(ihl>=5),只支持v4
goto inhdr_error;
BUILD_BUG_ON(IPSTATS_MIB_ECT1PKTS != IPSTATS_MIB_NOECTPKTS + INET_ECN_ECT_1);
BUILD_BUG_ON(IPSTATS_MIB_ECT0PKTS != IPSTATS_MIB_NOECTPKTS + INET_ECN_ECT_0);
BUILD_BUG_ON(IPSTATS_MIB_CEPKTS != IPSTATS_MIB_NOECTPKTS + INET_ECN_CE);
IP_ADD_STATS_BH(dev_net(dev),
IPSTATS_MIB_NOECTPKTS + (iph->tos & INET_ECN_MASK),
max_t(unsigned short, 1, skb_shinfo(skb)->gso_segs));
if (!pskb_may_pull(skb, iph->ihl*4)) //确保skb还可以容纳实际的报头(ihl*4)
goto inhdr_error;
iph = ip_hdr(skb);
if (unlikely(ip_fast_csum((u8 *)iph, iph->ihl))) //ip头csum校验
goto csum_error;
len = ntohs(iph->tot_len);
if (skb->len < len) {
IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_INTRUNCATEDPKTS);
goto drop;
} else if (len < (iph->ihl*4))
goto inhdr_error;
/* Our transport medium may have padded the buffer out. Now we know it
* is IP we can trim to the true length of the frame.
* Note this now means skb->len holds ntohs(iph->tot_len).
*/
if (pskb_trim_rcsum(skb, len)) { //去除多余的字节
IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_INDISCARDS);
goto drop;
}
skb->transport_header = skb->network_header + iph->ihl*4; //设置传输层header
/* Remove any debris in the socket control block */
memset(IPCB(skb), 0, sizeof(struct inet_skb_parm)); //清空cb,即inet_skb_parm值
/* Must drop socket now because of tproxy. */
skb_orphan(skb);
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, NULL, skb, //调用netfilter,实现iptables功能,通过后调用ip_rcv_finish
dev, NULL,
ip_rcv_finish);
csum_error:
IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_CSUMERRORS);
inhdr_error:
IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_INHDRERRORS);
drop:
kfree_skb(skb);
out:
return NET_RX_DROP;
}核心逻辑就是做一些数据合法性验证,统计计数器更新,设置传输层的header,最后调用PRE_ROUTING规则,如果包没有被丢掉到话最后调用ip_rcv_finish。
ip_rcv_finish
为了能将包送到合适的目的地,需要一个路由子系统的 dst_entry 变量。这里有两种可能性,一种是存在early_demux优化,直接从 socket中拿 dst_entry;否则的话在路由子系统中进行计算,路由子系统由ip_route_input_noref进入。
路由子系统完成工作后,会更新计数器,然后调用 dst_input,后者会进一步调用 dst_entry 变量中的 input 方法,这是由路由子系统初始化的一个函数指针,如果 packet 的最终目的地是本机,路由子系统会将 ip_local_deliver 赋给 input,否则的话把 ip_forward 赋给 input。
ip_local_deliver
int ip_local_deliver(struct sk_buff *skb)
{
/*
* Reassemble IP fragments.
*/
if (ip_is_fragment(ip_hdr(skb))) {
if (ip_defrag(skb, IP_DEFRAG_LOCAL_DELIVER))
return 0;
}
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN, skb, skb->dev, NULL,
ip_local_deliver_finish);
}这个函数看似简单,却包含了网络栈上两个大功能
最后调用ip_local_deliver_finish
ip_local_deliver_finish
最重要的处理步骤如下,即通过 protocol 字段选择对应的 net_protocol 结构,然后调用其 handler:
int protocol = ip_hdr(skb)->protocol;
const struct net_protocol *ipprot;
int raw;
resubmit:
raw = raw_local_deliver(skb, protocol);
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot != NULL) {
int ret;
if (!ipprot->no_policy) {
if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {
kfree_skb(skb);
goto out;
}
nf_reset(skb);
}
ret = ipprot->handler(skb);
if (ret < 0) {
protocol = -ret;
goto resubmit;
}udp 的 net_protocol 结构定义如下:
static const struct net_protocol udp_protocol = {
.early_demux = udp_v4_early_demux,
.handler = udp_rcv,
.err_handler = udp_err,
.no_policy = 1,
.netns_ok = 1,
};核心功能实现在__udp4_lib_rcv中:
int __udp4_lib_rcv(struct sk_buff *skb, struct udp_table *udptable,
int proto)
{
struct sock *sk;
struct udphdr *uh;
unsigned short ulen;
struct rtable *rt = skb_rtable(skb); //得到路由表项信息
__be32 saddr, daddr;
struct net *net = dev_net(skb->dev);
/*
* Validate the packet.
*/
if (!pskb_may_pull(skb, sizeof(struct udphdr))) //检测报文长度
goto drop; /* No space for header. */
uh = udp_hdr(skb);
ulen = ntohs(uh->len);
saddr = ip_hdr(skb)->saddr;
daddr = ip_hdr(skb)->daddr;
if (ulen > skb->len) //skb报文长度必须UDP头设定的长度,skb可能存在pad
goto short_packet;
if (proto == IPPROTO_UDP) {
/* UDP validates ulen. */
if (ulen < sizeof(*uh) || pskb_trim_rcsum(skb, ulen)) //裁剪skb报文
goto short_packet;
uh = udp_hdr(skb);
}
if (udp4_csum_init(skb, uh, proto)) //csum值校验,如果非零则表示csum错误
goto csum_error;
sk = skb_steal_sock(skb); //IP层调用UDP的early_demux函数设置的sk
if (sk) {
struct dst_entry *dst = skb_dst(skb);
int ret;
if (unlikely(sk->sk_rx_dst != dst))
udp_sk_rx_dst_set(sk, dst);
ret = udp_queue_rcv_skb(sk, skb); //sock处理skb报文
sock_put(sk);
/* a return value > 0 means to resubmit the input, but
* it wants the return to be -protocol, or 0
*/
if (ret > 0)
return -ret;
return 0;
}
if (rt->rt_flags & (RTCF_BROADCAST|RTCF_MULTICAST))
return __udp4_lib_mcast_deliver(net, skb, uh, //组播报文上送
saddr, daddr, udptable, proto);
sk = __udp4_lib_lookup_skb(skb, uh->source, uh->dest, udptable); //全量检索sock
if (sk) {
int ret;
if (inet_get_convert_csum(sk) && uh->check && !IS_UDPLITE(sk))
skb_checksum_try_convert(skb, IPPROTO_UDP, uh->check, //如果skb->ip_summed == CHECKSUM_NONE,重置csum
inet_compute_pseudo);
ret = udp_queue_rcv_skb(sk, skb); //sock处理skb报文
sock_put(sk);
/* a return value > 0 means to resubmit the input, but
* it wants the return to be -protocol, or 0
*/
if (ret > 0)
return -ret;
return 0;
}
if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) //ipset安全检测
goto drop;
nf_reset(skb);
/* No socket. Drop packet silently, if checksum is wrong */
if (udp_lib_checksum_complete(skb)) //没有socket,如果checksum出错则直接丢弃
goto csum_error;
UDP_INC_STATS_BH(net, UDP_MIB_NOPORTS, proto == IPPROTO_UDPLITE);
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PORT_UNREACH, 0); //发送icmp,通知发送方目的不可达
/*
* Hmm. We got an UDP packet to a port to which we
* don't wanna listen. Ignore it.
*/
kfree_skb(skb);
return 0;
short_packet:
net_dbg_ratelimited("UDP%s: short packet: From %pI4:%u %d/%d to %pI4:%u\n",
proto == IPPROTO_UDPLITE ? "Lite" : "",
&saddr, ntohs(uh->source),
ulen, skb->len,
&daddr, ntohs(uh->dest));
goto drop;
csum_error:
/*
* RFC1122: OK. Discards the bad packet silently (as far as
* the network is concerned, anyway) as per 4.1.3.4 (MUST).
*/
net_dbg_ratelimited("UDP%s: bad checksum. From %pI4:%u to %pI4:%u ulen %d\n",
proto == IPPROTO_UDPLITE ? "Lite" : "",
&saddr, ntohs(uh->source), &daddr, ntohs(uh->dest),
ulen);
UDP_INC_STATS_BH(net, UDP_MIB_CSUMERRORS, proto == IPPROTO_UDPLITE); //UDP csum错误统计
drop:
UDP_INC_STATS_BH(net, UDP_MIB_INERRORS, proto == IPPROTO_UDPLITE); //UDP丢包统计
kfree_skb(skb);
return 0;
}这里做的事情大概可以分为如下几步:
udp_queue_rcv_skb
开始做了如下判断[11]:
// 判断sk_rcvbuf是否为满
if (sk_rcvqueues_full(sk, skb, sk->sk_rcvbuf))
goto drop;
rc = 0;
ipv4_pktinfo_prepare(sk, skb);
bh_lock_sock(sk);
if (!sock_owned_by_user(sk))
rc = __udp_queue_rcv_skb(sk, skb);
else if (sk_add_backlog(sk, skb, sk->sk_rcvbuf)) {
bh_unlock_sock(sk);
goto drop;
}
bh_unlock_sock(sk);最后对 sk_rcvbuf 判满以后调用 __udp_queue_rcv_skb
本文由哈喽比特于3年以前收录,如有侵权请联系我们。
文章来源:https://mp.weixin.qq.com/s/66-PPfz3M1W8fXCkXnVIlg
京东创始人刘强东和其妻子章泽天最近成为了互联网舆论关注的焦点。有关他们“移民美国”和在美国购买豪宅的传言在互联网上广泛传播。然而,京东官方通过微博发言人发布的消息澄清了这些传言,称这些言论纯属虚假信息和蓄意捏造。
日前,据博主“@超能数码君老周”爆料,国内三大运营商中国移动、中国电信和中国联通预计将集体采购百万台规模的华为Mate60系列手机。
据报道,荷兰半导体设备公司ASML正看到美国对华遏制政策的负面影响。阿斯麦(ASML)CEO彼得·温宁克在一档电视节目中分享了他对中国大陆问题以及该公司面临的出口管制和保护主义的看法。彼得曾在多个场合表达了他对出口管制以及中荷经济关系的担忧。
今年早些时候,抖音悄然上线了一款名为“青桃”的 App,Slogan 为“看见你的热爱”,根据应用介绍可知,“青桃”是一个属于年轻人的兴趣知识视频平台,由抖音官方出品的中长视频关联版本,整体风格有些类似B站。
日前,威马汽车首席数据官梅松林转发了一份“世界各国地区拥车率排行榜”,同时,他发文表示:中国汽车普及率低于非洲国家尼日利亚,每百户家庭仅17户有车。意大利世界排名第一,每十户中九户有车。
近日,一项新的研究发现,维生素 C 和 E 等抗氧化剂会激活一种机制,刺激癌症肿瘤中新血管的生长,帮助它们生长和扩散。
据媒体援引消息人士报道,苹果公司正在测试使用3D打印技术来生产其智能手表的钢质底盘。消息传出后,3D系统一度大涨超10%,不过截至周三收盘,该股涨幅回落至2%以内。
9月2日,坐拥千万粉丝的网红主播“秀才”账号被封禁,在社交媒体平台上引发热议。平台相关负责人表示,“秀才”账号违反平台相关规定,已封禁。据知情人士透露,秀才近期被举报存在违法行为,这可能是他被封禁的部分原因。据悉,“秀才”年龄39岁,是安徽省亳州市蒙城县人,抖音网红,粉丝数量超1200万。他曾被称为“中老年...
9月3日消息,亚马逊的一些股东,包括持有该公司股票的一家养老基金,日前对亚马逊、其创始人贝索斯和其董事会提起诉讼,指控他们在为 Project Kuiper 卫星星座项目购买发射服务时“违反了信义义务”。
据消息,为推广自家应用,苹果现推出了一个名为“Apps by Apple”的网站,展示了苹果为旗下产品(如 iPhone、iPad、Apple Watch、Mac 和 Apple TV)开发的各种应用程序。
特斯拉本周在美国大幅下调Model S和X售价,引发了该公司一些最坚定支持者的不满。知名特斯拉多头、未来基金(Future Fund)管理合伙人加里·布莱克发帖称,降价是一种“短期麻醉剂”,会让潜在客户等待进一步降价。
据外媒9月2日报道,荷兰半导体设备制造商阿斯麦称,尽管荷兰政府颁布的半导体设备出口管制新规9月正式生效,但该公司已获得在2023年底以前向中国运送受限制芯片制造机器的许可。
近日,根据美国证券交易委员会的文件显示,苹果卫星服务提供商 Globalstar 近期向马斯克旗下的 SpaceX 支付 6400 万美元(约 4.65 亿元人民币)。用于在 2023-2025 年期间,发射卫星,进一步扩展苹果 iPhone 系列的 SOS 卫星服务。
据报道,马斯克旗下社交平台𝕏(推特)日前调整了隐私政策,允许 𝕏 使用用户发布的信息来训练其人工智能(AI)模型。新的隐私政策将于 9 月 29 日生效。新政策规定,𝕏可能会使用所收集到的平台信息和公开可用的信息,来帮助训练 𝕏 的机器学习或人工智能模型。
9月2日,荣耀CEO赵明在采访中谈及华为手机回归时表示,替老同事们高兴,觉得手机行业,由于华为的回归,让竞争充满了更多的可能性和更多的魅力,对行业来说也是件好事。
《自然》30日发表的一篇论文报道了一个名为Swift的人工智能(AI)系统,该系统驾驶无人机的能力可在真实世界中一对一冠军赛里战胜人类对手。
近日,非营利组织纽约真菌学会(NYMS)发出警告,表示亚马逊为代表的电商平台上,充斥着各种AI生成的蘑菇觅食科普书籍,其中存在诸多错误。
社交媒体平台𝕏(原推特)新隐私政策提到:“在您同意的情况下,我们可能出于安全、安保和身份识别目的收集和使用您的生物识别信息。”
2023年德国柏林消费电子展上,各大企业都带来了最新的理念和产品,而高端化、本土化的中国产品正在不断吸引欧洲等国际市场的目光。
罗永浩日前在直播中吐槽苹果即将推出的 iPhone 新品,具体内容为:“以我对我‘子公司’的了解,我认为 iPhone 15 跟 iPhone 14 不会有什么区别的,除了序(列)号变了,这个‘不要脸’的东西,这个‘臭厨子’。